By: Ben Snaidero
Overview
tässä osiossa käsitellään asioita, jotka sinun tulee tietää ei-ryhmitetyistä indekseistä.
mikä on ryhmittelemätön indeksi
ryhmittelemätön indeksi (tai säännöllinen B-puuindeksi) on indeksi, jossa rivien järjestys ei vastaa todellisen tiedon fyysistä järjestystä. Se on insteadordered sarakkeet, jotka muodostavat indeksin. Ryhmittelemättömässä hakemistossa indeksin takasivuilla ei ole varsinaisia tietoja, vaan ne sisältävät todellisia tietoja. Nämä osoittimet osoittaisivat ryhmitelty Hakemisto datapage, jossa todellinen data on olemassa (tai kasaan sivun, jos ei ryhmitelty Hakemisto existson the table).
miksi ei-ryhmiteltyjen indeksien luominen
tärkein etu ei-ryhmitetyssä indeksissä taulukossa on se, että se tarjoaa nopean pääsyn tietoihin. Indeksin avulla tietokantamoottori voi paikantaa tietoja nopeastikannatta skannata läpi koko taulukon. Koska taulukko saa suurempi on erittäin tärkeää, että oikeat indeksit lisätään taulukkoon, koska ilman indexes kyselyn suorituskyky putoaa dramaattisesti.
milloin pitäisi luoda ei-ryhmitettyjä indeksejä
on kaksi tapausta, joissa ryhmittelemättömän indeksin pitäminen pöydällä on hyödyllistä. Ensimmäinen, kun on enemmän kuin yksi joukko sarakkeita, joita käytetään missä clauseof kyselyt, jotka käyttävät taulukkoa. Toinen indeksi (olettaen, että ensisijaisessa avainsarakkeessa on jo ryhmitelty indeksi) nopeuttaa suoritusaikoja ja vähentää muiden kyselyiden suoritusaikoja. Toiseksi, jos kyselyt vaativat usein datato palautetaan tietyssä järjestyksessä, ottaa indeksi näiden sarakkeiden voi vähentää THEAMOUNT suorittimen ja muistin tarvitaan ylimääräisiä lajittelu ei tarvitse tehdä, koska tiedot indeksi on jo tilattu.
seuraavassa esimerkissä ei tarvita taulukkokannausta tietojen hakemiseksi, vain hakemistohaku ei-clusteredindexistä ja hakutoiminto clustered indexistä tietojen saamiseksi. Huomaa myös, että lajittelua ei tarvita, koska tiedot ovat jo oikeassa järjestyksessä.
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

Miten luodaan ei-ryhmitelty indeksi
ei-ryhmitelty indeksi on periaatteessa sama kuin ryhmitetyn indeksin luominen, mutta sen sijaan, että määrittäisimme yhdistetyn liuskan, määrittelimme yhdistetyn. Voimme myös jättää tämän lausekkeen kokonaan pois, koska ei-ryhmitelty on oletuksena luotaessa indeksi.
alla oleva TSQL näyttää esimerkin jokaisesta lauseesta.
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
se, mikä on peittävä indeksi
, on indeksi, joka koostuu kaikista (tai useammista) sarakkeista, joita tarvitaan kyselyn tyydyttämiseksi indeksin keskeisinä sarakkeina. Kun kattavaa indeksiä voidaan käyttää kyselyn suorittamiseen, vähemmän IO-operaatioita tarvitaan, koska optimizerno enää on suoritettava ylimääräisiä hakuja hakea todellinen taulukon tiedot.
alla on esimerkki TSQL: stä, jolla voit luoda verkkoindeksin Tuotetaulukkoon.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
seuraava TSQL-kysely voidaan nyt suorittaa vain käyttämällä juuri luotua uutta indeksiä, koska kaikki kyselyn sarakkeet ovat osa indeksiä.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
seuraava Explain-suunnitelma vahvistaa, että tähän kyselyyn ei tarvita ylimääräistä hakua.

mikä on indeksi, jossa on mukana sarakkeita
indeksi, joka on luotu sisältyvillä sarakkeilla, on ei-ryhmitelty indeksi, joka sisältää myös ei-avain-sarakkeita indeksin lehtisolmuissa, samaan tapaan kuin ryhmitetty indeksi. On olemassa pari etuja käyttämällä mukana sarakkeita. Ensinnäkin se antaa sinulle mahdollisuuden sisällyttää saraketyyppejä, jotka eivät ole sallittuja indeksinäppäiminä Indexissä. Lisäksi, kun kaikki kyselyn sarakkeet ovat joko indeksiavaimia tai sisällytetään sarakkeeseen, kyselyn ei enää tarvitse tehdä ylimääräistä hakua saadakseen kaikki tarvittavat tiedot kyselyn tyydyttämiseksi, mikä johtaa vähemmän levyn toimintoja. Tämä vastaa edellä mainittua kattavaa indeksiä.
käyttämällä samaa esimerkkiä yllä olevasta seuraavasta TSQL: stä luodaan sama indeksi lukuun ottamatta Tuotenumerosaraketta, johon viitataan sisältyvänä sarakkeena eikä indeksiavainsarakkeena.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
käyttämällä samaa kysely kuin edellä tämä pitäisi myös pystyä suorittamaan ilman requiringany ylimääräisiä hakuja.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
seuraava Explain-suunnitelma vahvistaa, että tähän kyselyyn ei tarvita ylimääräistä hakua.

ei-ryhmitelty indeksirelaatio ryhmiteltyyn indeksiin
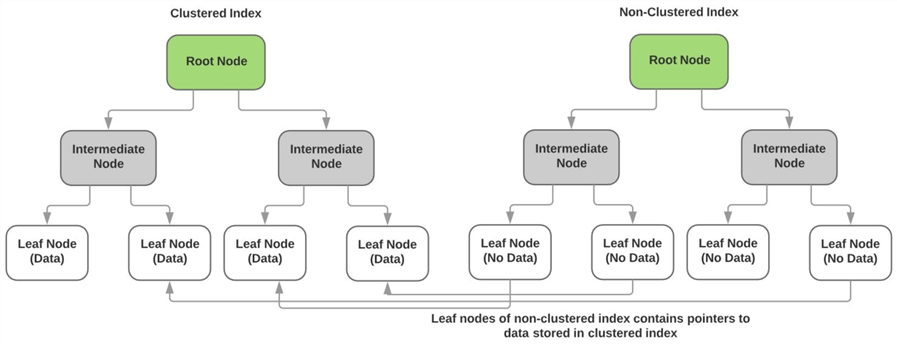
kuten edellä on kuvattu, ryhmitetty indeksi tallentaa muiden kuin keykolumnien todelliset tiedot indeksin lehtisolmuihin. Kunkin Ei-clusteredindeksin lehtisolmut eivät sisällä mitään tietoa, vaan niissä on osoittimia clustered Indexin varsinaiselle tietosivulle(tai lehtisolmulle). Oheinen kaavio havainnollistaa tätä kohtaa.
suodatetut indeksit
mikä se on?
Afiltered index on erityinen indeksityyppi, jossa vain tietty osa taulukon riveistä on indeksoitu. Suodattimen kriteerien perusteella, joita sovelletaan, kun indeksi luodaan, vain jäljellä olevat rivit indeksoidaan, mikä voi säästää tilaa, parantaa kyselyn suorituskykyä ja vähentää kunnossapitoa yläpuolella, koska indeksi on paljon pienempi.
Miksi käyttää sitä?
suodatetut indeksit ovat hyödyllisiä, kun luot indeksejä taulukoihin, joissa on paljon nollia tietyissä sarakkeissa tai tietyillä sarakkeilla on hyvin alhainen kardinaalisuus ja kyselet usein matalan taajuuden arvoa.
miten se luodaan?
Afiltered index luodaan yksinkertaisesti lisäämällä WHERE-lauseke mihin tahansa ei-clusteredindex-luomislauseeseen. Seuraava TSQL on esimerkki syntaksista suodatetun indeksin luomiseksi.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
Vahvista indeksin käyttö
seuraavassa kyselyssä tulisi käyttää vasta luotua indeksiä, koska taulukossa on hyvin vähän ilmoituksia ShipDate NULL: llä. Tässä on TSQL.
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;