tässä artikkelissa esitellään SQL Serverin ei-ryhmitelty indeksi esimerkkien avulla.
Johdanto
aiemmassa artikkelissa katsaus SQL Serverin Ryhmiteltyihin indekseihin selvitimme SQL Serverin indeksivaatimusta ja ryhmiteltyjä indeksejä.
ennen kuin etenemme, tehdään nopea yhteenveto SQL Server clustered-indeksistä:
- se lajittelee tiedot fyysisesti ryhmitetyn indeksiavaimen mukaan
- meillä voi olla vain yksi ryhmitetty indeksi taulukkoa kohti
- taulukko ilman ryhmitettyä indeksiä on kasa, ja se saattaa johtaa suorituskykyyn liittyviin ongelmiin
- SQL Server luo automaattisesti ryhmitetyn indeksin ensisijaiselle sarakkeelle
- ryhmitetty indeksi on tallennettu b-puu-muodossa ja sisältää tietosivut lehtisolmussa, kuten alla on esitetty
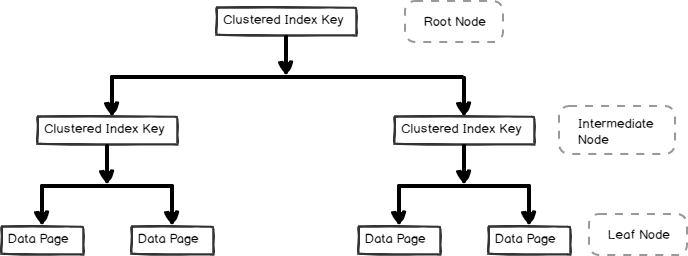
Ei-Clustered indexes ovat myös hyödyllisiä kyselyn suorituskyvyn ja optimoinnin riippuen kyselyn työmäärä. Tässä artikkelissa tarkastellaan ei-ryhmitelty indeksi ja sen sisäosat.
yleiskatsaus SQL Serverin ei-ryhmitetystä indeksistä
ei-ryhmitetyssä indeksissä lehtisolmu ei sisällä varsinaista tietoa. Se koostuu osoitin todellinen data.
- jos taulukko sisältää ryhmitetyn indeksin, lehtisolmu osoittaa ryhmiteltyä indeksitietosivua, joka koostuu todellisista tiedoista
- jos taulukko on kasa (ilman ryhmiteltyä indeksiä), lehtisolmu osoittaa kasasivua
alla olevassa kuvassa, voimme tarkastella Ei-ryhmitellyn indeksin lehtitasoa osoittaen kohti ryhmitetyssä indeksissä olevaa datasivua:
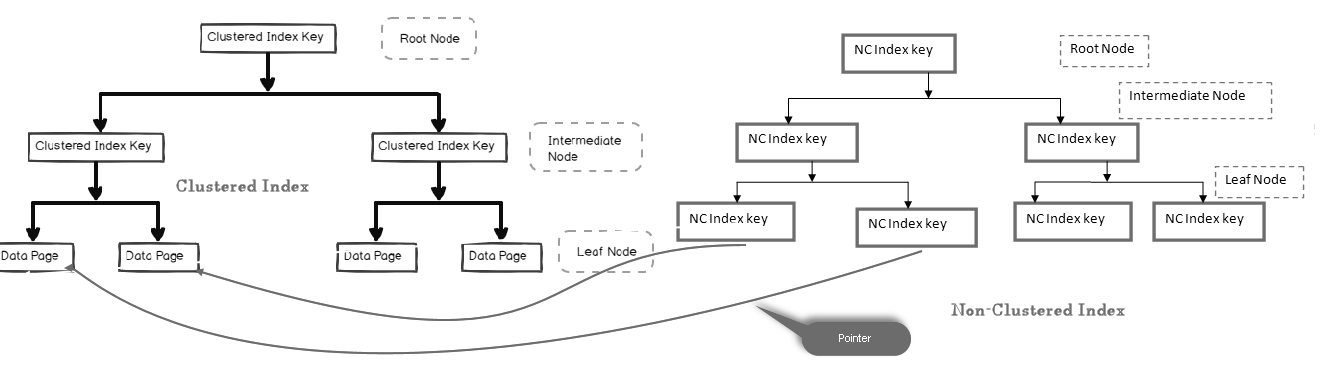
SQL-taulukoissa voi olla useita ei-ryhmiteltyjä indeksejä, koska se on looginen indeksi eikä Lajittele tietoja fyysisesti verrattuna ryhmiteltyyn indeksiin.
ymmärretään SQL Serverin ei-ryhmitelty indeksi esimerkin avulla.
-
luo Työntekijätaulukko ilman indeksiä
123456Luo taulukko dbo.Employee(EmpID INT,EMpName VARCHAR(50),EmpAge INT,EmpContactNumber VARCHAR(10)); -
lisää siihen muutama levy
123lisätään työntekijöiden arvoihin (1, ”Raj’,32,8474563217)Insert into Employee values(2, ”kusum’,30,9874563210)Insert into Employee values (3, ”Akshita’,28,9632547120) -
Etsi EmpID 2 ja etsiä todellinen toteutussuunnitelma sen
1valitse * työntekijältä, jossa EmpID=2se tekee taulukon skannauksen, koska meillä ei ole mitään hakemistoa tässä taulukossa.:
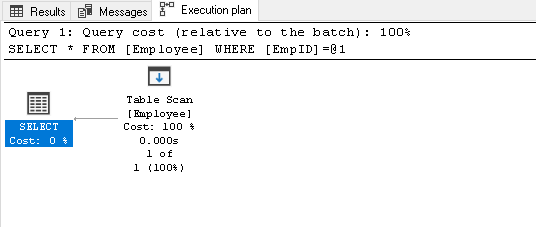
-
Luo ainutlaatuinen ryhmitelty indeksi EmpID-sarakkeeseen
1luo ainutlaatuinen ryhmitelty indeksi IX_Clustered_Empployee DBO: ssa.Työntekijä (EmpID); -
Etsi EmpID 2 ja etsiä todellinen toteutussuunnitelma sen
tässä suoritussuunnitelmassa voimme huomata, että taulukon skannauksen muutokset ryhmiteltyyn indeksiin pyrkivät:
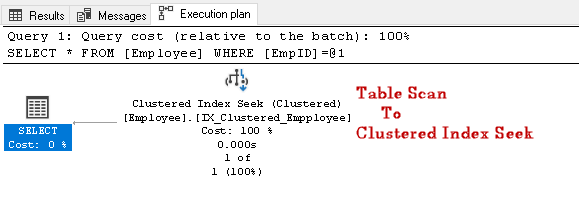
suoritetaan toinen SQL-kysely, jolla haetaan työntekijää, jolla on tietty yhteystietonumero:
|
1
|
valitse * työntekijältä, jossa EmpContactNumber=’9874563210′
|
meillä ei ole indeksiä EmpContactNumber-sarakkeessa, joten kysely Optimizer käyttää ryhmitettyä indeksiä, mutta se skannaa koko indeksin tietuetta noudettaessa.:
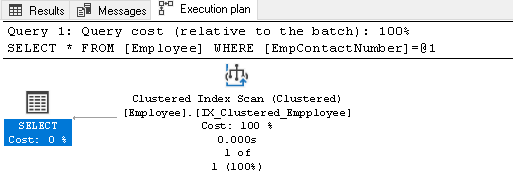
Napsauta suoritussuunnitelmaa hiiren kakkospainikkeella ja valitse Näytä Suoritussuunnitelma XML:
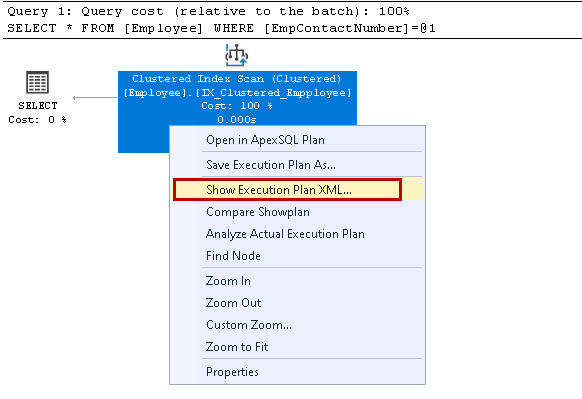
se avaa XML-suoritussuunnitelman uudessa kyselyikkunassa. Täällä, huomaamme, että se käyttää ryhmitelty indeksinäppäintä ja lukee yksittäisiä rivejä hakemiseen tulos:

lisätään Työntekijätaulukkoon vielä muutama tietuetta seuraavan komentosarjan avulla:
|
1
2
3
|
lisää työntekijöiden arvoihin (4, ”Manoj’,38,7892145637)
Insert into Employee values (5, ”John’,33,7900654123)
lisää työntekijöiden arvoihin (6, ”Priya’,18,9603214569)
|
taulukossa on kuuden työntekijän tiedot. Nyt, suorita select statement uudelleen hakemalla työntekijän tietueet tietyllä yhteystietonumerolla:
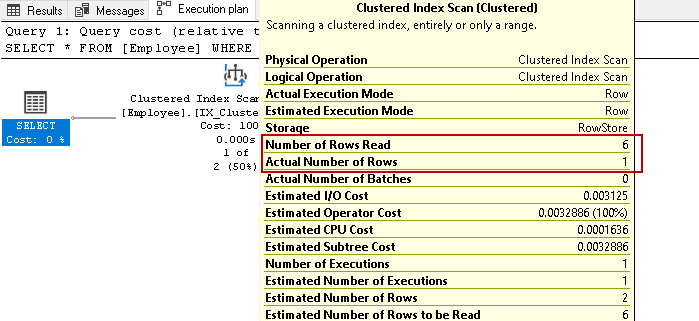
se skannaa uudelleen kaikki kuusi riviä tuloksen perusteella määritetyn ehdon. Kuvitelkaa, että meillä on miljoonia levyjä taulukossa. Jos SQL Serverin on luettava kaikki indeksiavainrivit, se olisi resurssi ja aikaa vievä tehtävä.
voimme esittää ryhmiteltyä indeksiä (ei varsinaista representaatiota) B-puun muodossa seuraavan kuvan mukaisesti:

edellisessä kyselyssä SQL Server lukee juurisolmun sivun ja hakee jokaisen lehtisolmun sivun ja rivin tiedonhakua varten.
nyt luodaan SQL Serverin ainutlaatuinen ei-ryhmitelty indeksi Empcontactnumber-sarakkeeseen indeksiavaimeksi:
|
1
|
luo ainutlaatuinen NONCLUSTERED indeksi Ix_nonclustered_työntekijä DBO.Työntekijä (EmpContactNumber);
|
ennen kuin selitämme tämän indeksin, toista SELECT statement ja tarkastele todellista suoritussuunnitelmaa:
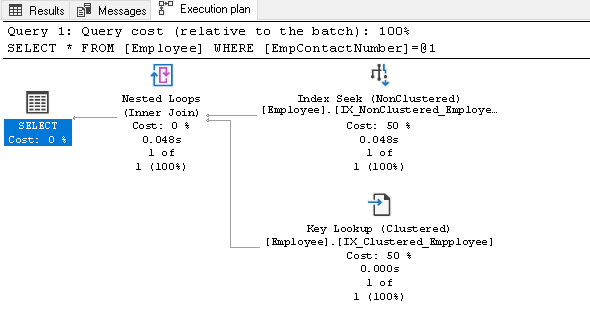
tässä toteutussuunnitelmassa voidaan nähdä kaksi osatekijää:
- Index Seek (NonClustered)
- Key Lookup (Clustered)
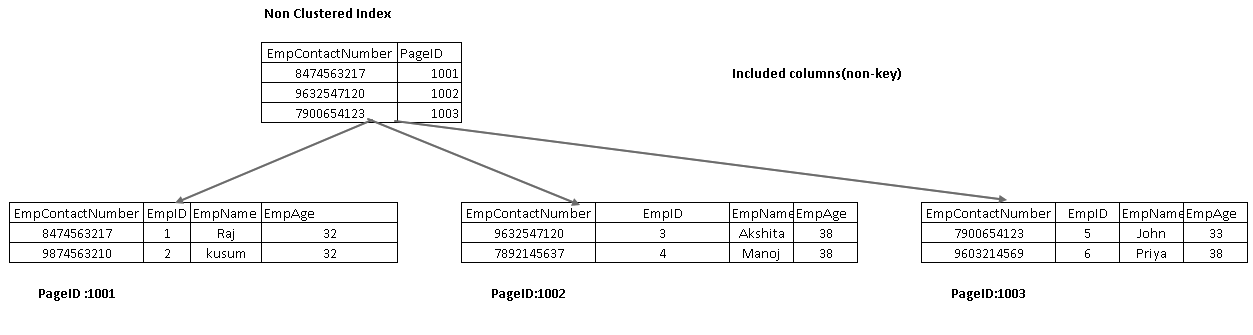
ymmärtääksemme näitä komponentteja, meidän täytyy tarkastella Ei-ryhmitelty indeksi SQL Server design. Tässä, voit nähdä, että lehtisolmu sisältää ei-ryhmitelty indeksiavain (EmpContactNumber) ja ryhmitelty indeksiavain (EmpID):
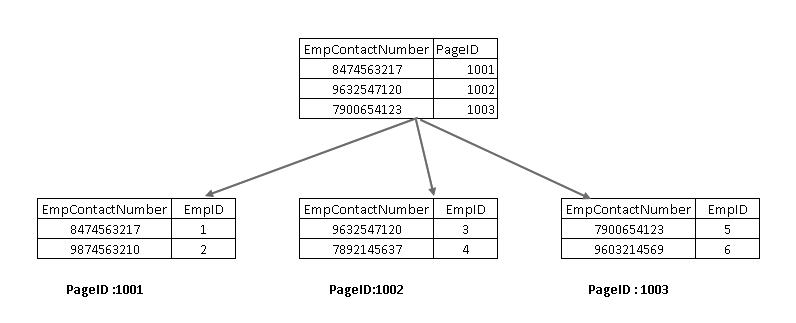
nyt, jos SELECT statement toistetaan, se kulkee käyttäen ei-ryhmiteltyä indeksiavainta ja osoittaa sivulle, jossa on ryhmitelty indeksiavain:
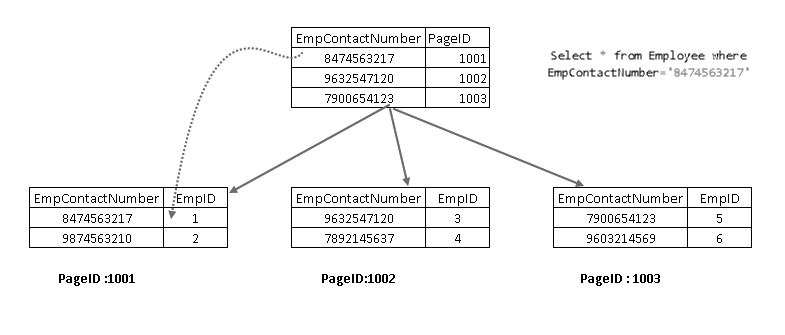
se osoittaa, että se hakee tietueen ryhmitetyn indeksiavaimen ja ei-ryhmitetyn indeksiavaimen yhdistelmällä. Voit nähdä täydellisen logiikan SELECT lauseke kuten alla:
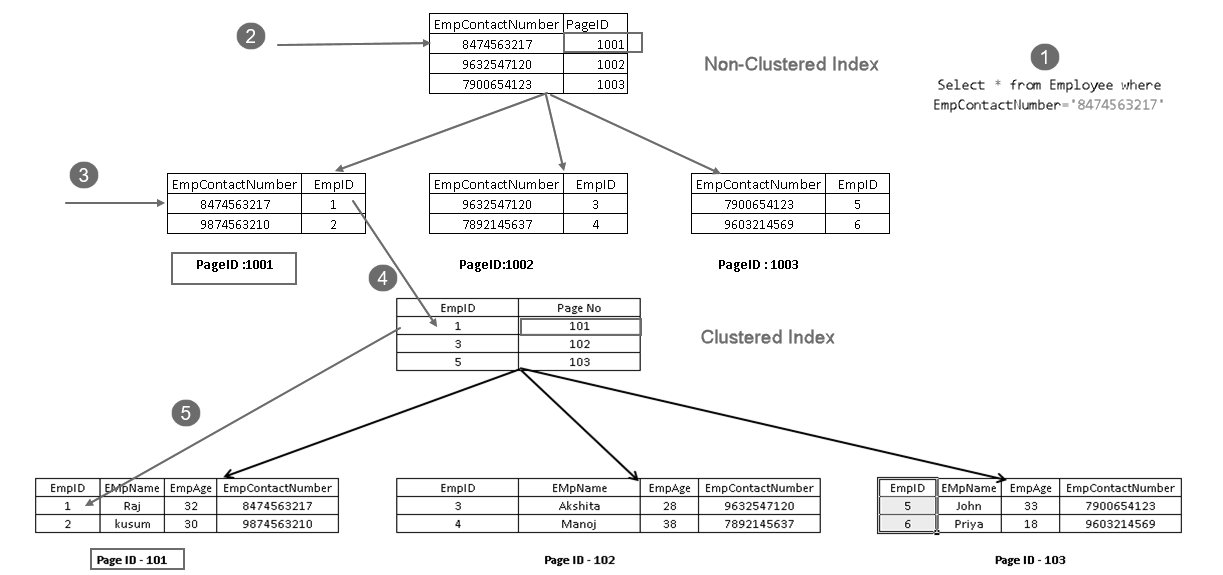
- käyttäjä suorittaa select statement-toiminnon löytääkseen työntekijän tietueet, jotka vastaavat tiettyä yhteystietonumeroa
- kyselyn Optimizer käyttää ei-ryhmitettyä indeksiavainta ja saa selville sivunumeron 1001
- Tämä sivu koostuu ryhmitetystä indeksiavaimesta. Näet EmpID 1 yllä olevassa kuvassa
- SQL Server selvittää sivun nro 101, joka koostuu EmpID 1 tietueista käyttäen ryhmitettyä indeksinäppäintä
- se lukee vastaavan rivin ja palauttaa tulosteen käyttäjälle
Aiemmin näimme, että se lukee kuusi riviä hakeakseen vastaavan rivin ja palauttaa yhden rivin tulosteessa. Katsotaanpa toteutussuunnitelmaa ei-ryhmitetyllä indeksillä:

Non-unique non-clustered index in SQL Server
We can have multiple non-clustered indexes in a SQL table. Aiemmin loimme ainutlaatuisen Ei-ryhmitetyn indeksin EmpContactNumber-sarakkeeseen.
ennen indeksin luomista suorita seuraava kysely niin, että EmpAge-sarakkeessa on kaksoisarvo:
|
1
2
3
|
Update Empire set EmpAge=32 where EmpID = 2
Update Empire set EmpAge=38 where EmpID=6
Update Empire set EmpAge=38 where EmpID=3
|
suoritetaan seuraava kysely ei-ainutkertaiselle ei-ryhmitetylle indeksille. Kyselysyntaksissa emme määritä uniikkia avainsanaa, ja se kertoo SQL Serverin luovan ei-uniikin indeksin:
|
1
|
luo NONCLUSTERED INDEX Ncix_ Employee_empage ON dbo.Työntekijä(EmpAge);
|
kuten tiedämme, indeksin avaimen pitäisi olla ainutlaatuinen. Tässä tapauksessa, haluamme lisätä Ei-ainutlaatuinen avain. Herää kysymys: Miten SQL Server tekee tästä avaimesta ainutlaatuisen?
SQL Server tekee sille seuraavia asioita:
- se lisää ryhmitellyn indeksiavaimen ei-ainutkertaisen ei-ryhmitellyn indeksin
- jos ryhmitelty indeksiavain on myös ei-ainutkertainen, se lisää 4-tavuisen yksilöllisen indeksiavaimen siten, että indeksiavain on yksilöllinen
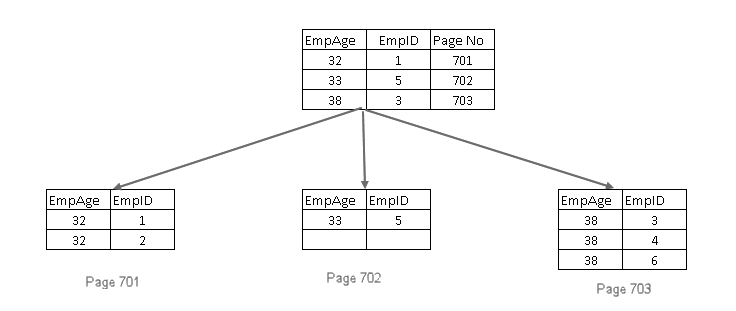
Include non-key columns in non-clustered index in SQL Server
Let ’ s look the following actual execution plan again of the following query:
|
1
2
|
valitse * työntekijältä
missä EmpContactNumber=’8474563217′
|
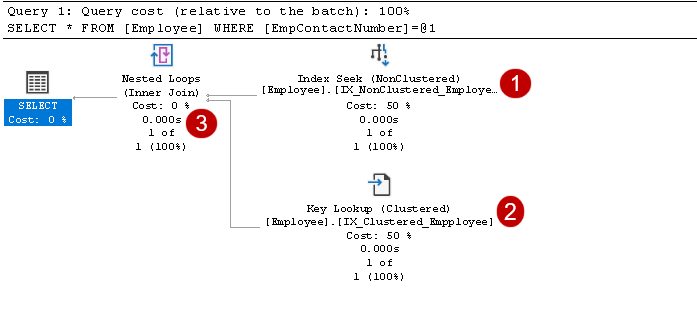
se sisältää indeksihakuoperaattorit ja avainhakuoperaattorit, kuten yllä olevasta kuvasta näkyy:
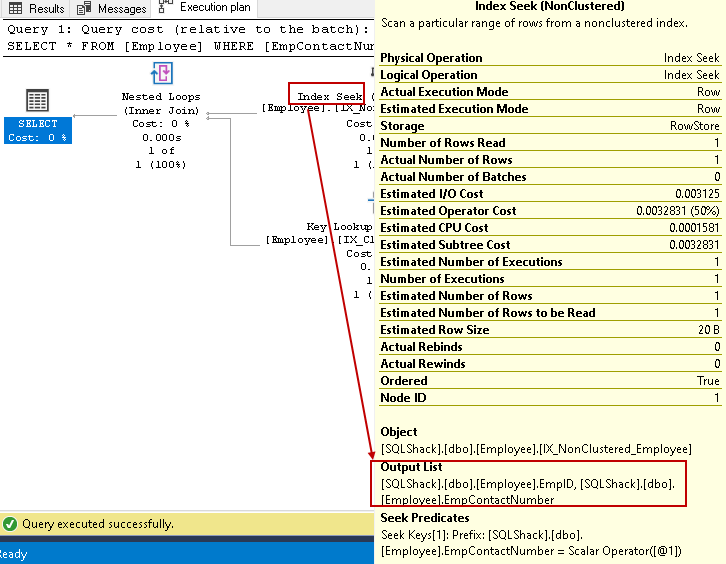
- Hakemisto hakee: SQL Query Optimizer käyttää indeksihakua ei-ryhmitetyssä indeksissä ja hakee EmpID, EmpContactNumber sarakkeet
-
tässä vaiheessa, Query Optimizer käyttää avainhakua ryhmitetyssä indeksissä ja hakee arvot EmpName ja EmpAge sarakkeet
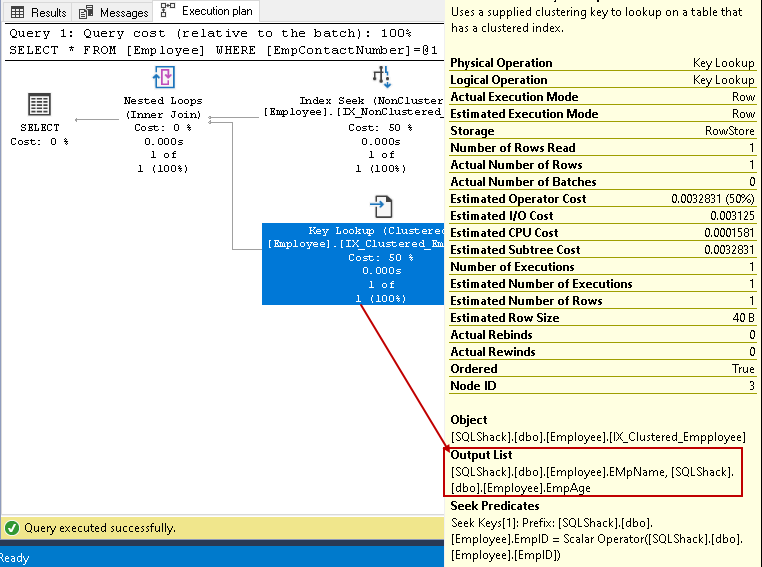
-
tässä vaiheessa, Query Optimizer käyttää sisäkkäisiä silmukoita kunkin rivin lähtö ei-ryhmitelty indeksi matching kanssa klusteroitu indeksi rivi
sisäkkäinen silmukka saattaa olla kallis operaattori isoille pöydille. Voimme vähentää kustannuksia käyttämällä ei-ryhmitelty indeksi ei-avain sarakkeet. Määrittelemme ei-avaimen sarakkeen ei-ryhmitetyssä indeksissä käyttäen indeksilauseketta.
pudotetaan ja luodaan SQL Serverin ei-ryhmitelty indeksi käyttäen mukana olevia sarakkeita:
|
1
2
3
4
5
6
7
|
pudota indeksi päälle .
GO
CREATE UNIQUE NONCLUSTERED INDEX ON .
(
ASC
)
INCLUDE(EmpName, EmpAge)
|
mukana olevat pylväät ovat osa lehtisolmua indeksipuussa. Se auttaa hakemaan tietoja itse indeksistä sen sijaan, että kulkisi edelleen tiedonhakua varten.
seuraavassa kuvassa saadaan molemmat mukana olevat sarakkeet EmpName ja EmpAge osaksi lehtisolmua:
suorita valittu lauseke uudelleen ja katso varsinainen toteutussuunnitelma nyt. Meillä ei ole avainlookup ja sisäkkäinen silmukka tässä suoritussuunnitelmassa:

vietäänpä kursori indeksin päälle ja katsotaan tulostesarakkeiden luetteloa. SQL Server voi löytää kaikki sarakkeet käyttämällä tätä ei-ryhmitelty Hakemisto etsiä:
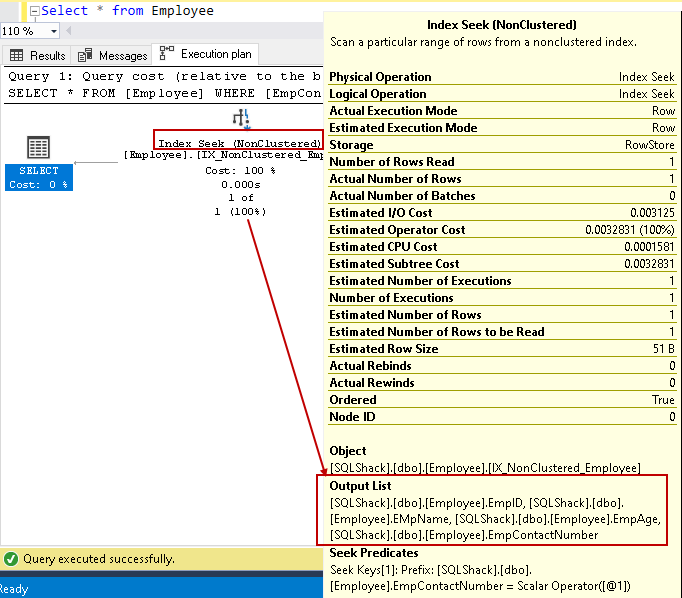
voimme parantaa kyselytehoa peittävällä indeksillä mukana olevien Ei-avainten sarakkeiden avulla. Se ei kuitenkaan tarkoita, että meidän kaikkien pitäisi olla indeksin määrittelyssä ei-keskeisiä sarakkeita. Meidän on oltava varovaisia indeksin suunnittelussa ja testattava indeksin käyttäytyminen ennen käyttöönottoa tuotantoympäristössä.
johtopäätös
tässä artikkelissa tarkastelimme SQL Serverin ei-ryhmitettyä indeksiä ja sen käyttöä yhdessä ryhmitetyn indeksin kanssa. Meidän pitäisi huolellisesti suunnitella indeksi kohti työmäärä ja kyselyn käyttäytymistä.
- tekijä
- tuoreita viestejä

hän on luonut yhden suurimmista ilmaisista verkkoartikkelikokoelmista yhdestä aiheesta, 50-osaisen SQL Server Always on Availability Groups-sarjan. Hänen panoksensa SQL Server-yhteisössä, hän on tunnustettu eri palkintoja, kuten arvostetun ”paras kirjailija vuoden” jatkuvasti 2020 ja 2021 sqlshack.
Raj on aina kiinnostunut uusista haasteista, joten jos tarvitset konsultointiapua mistä tahansa hänen kirjoituksissaan käsitellystä aiheesta, hänet voi tavoittaa [email protected]
Katso kaikki viestit käyttäjältä Rajendra Gupta
- käytä ARM-malleja Azure container-instanssien käyttöönottoon SQL Server Linux-kuvien kanssa-21. joulukuuta 2021
- Etätyöpöytäyhteys AWS RDS SQL Serverille Amazon RDS: n kanssa Custom-14. joulukuuta 2021
- säilytä SQL Server-tiedostot pysyvässä tallennustilassa Azure Container Instansseille-joulukuu 10, 2021