Por: Ben Snaidero
Visão
nesta seção trataremos de coisas que você precisa saber sobre índices não clusterizados.
o que é um índice não agrupado
um índice não agrupado (ou índice B-tree regular) é um índice em que a ordem das linhas não corresponde à ordem física dos dados reais. É insteadordered pelas colunas que compõem o índice. Em um índice não agrupado, as páginas do índice não contêm nenhum dado real, mas contêm ponteiros para os dados reais. Esses ponteiros apontariam para o clustered index datapage onde os dados reais existem (ou a página heap se nenhum índice clusterizado existisse na tabela).
por que criar índices não clusterizados
o principal benefício de ter um índice não clusterizado em uma tabela é que ele fornece acesso rápido aos dados. O índice permite que o mecanismo de banco de dados localize dados rapidamentesem ter que digitalizar toda a tabela. Como uma tabela fica maior é muito importante que os índices corretos sejam adicionados à tabela, pois sem anyindexes o desempenho da consulta cairá drasticamente.
quando os índices Não agrupados devem ser criados
existem dois casos em que ter um índice não agrupado em uma tabela é benéfico. Primeiro, quando há mais de um conjunto de colunas que são usadas nas consultas where clauseof que acessam a tabela. Um segundo índice (supondo que já existeum índice agrupado na coluna chave primária) acelerará os tempos de execução e reduceIO para as outras consultas. Em segundo lugar, se suas consultas frequentemente exigem datato ser retornado em uma determinada ordem, ter um índice nessas colunas pode reduzir oamount de CPU e memória necessária como classificação adicional não precisará ser donesince os dados no índice já está ordenado.
o exemplo a seguir showshow no table scan é necessário para buscar os dados, apenas uma busca de índice do não clusteredindex e uma pesquisa do índice agrupado para obter os dados. Além disso, note quenenhuma classificação é necessária, pois os dados já estão na ordem correta.
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

Como criar um índice não agrupado em cluster
Criação de um índice não agrupado é basicamente o mesmo que a criação de índice de cluster,mas em vez de especificar theCLUSTEREDclause nós specifyNONCLUSTERED. Também podemos omitir essa cláusula completamente, pois um não agrupado é o padrão ao criar um índice.
o TSQL abaixo mostra um exemplo de cada instrução.
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
o Que é um índice de cobertura
Acovering índice é um índice de que é feito o backup de todos (ou mais) dos columnsrequired para satisfazer uma consulta como colunas de chave de índice. Quando um índice de cobertura pode ser usado para executar uma consulta, menos operações IO são necessárias, pois o optimizerno precisa realizar pesquisas extras para recuperar os dados reais da tabela.
abaixo está um exemplo do TSQL que você pode usar para criar o índice de acovering na tabela de produtos.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
a consulta TSQL a seguir agora pode ser executada acessando apenas o novo indexnós acabamos de criar, Pois todas as colunas na consulta fazem parte do Índice.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
o plano followingEXPLAIN confirma que não há necessidade de pesquisa extra para esta consulta.

o Que é um índice com colunas incluídas
Um índice criado com colunas incluídas é um índice não-agrupado também includesnon-chave colunas nos nós folha de índice, semelhante a um índice de cluster. Existem alguns benefícios em usar colunas incluídas. Primeiro, dá a vocêa capacidade de incluir tipos de colunas que não são permitidos como chaves de índice em seuindex. Além disso, quando todas as colunas em sua consulta são uma chave de índice ouincluída coluna, a consulta não precisa mais fazer uma pesquisa extra para obter todos os dados necessários para satisfazer a consulta, o que resulta em menos operações de disco. Isso é semelhante ao índice de cobertura mencionado anteriormente.
usando o mesmo exemplo acima do seguinte TSQL criará o mesmo índice, exceto com o productnumber columnreferenced como uma coluna incluída e não uma coluna de chave de índice.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
Usando a mesma consulta acima, isso também deve ser capaz de executar sem requiringany extra pesquisas.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
o plano followingEXPLAIN confirma que não há nenhuma pesquisa extra necessária para esta consulta também.

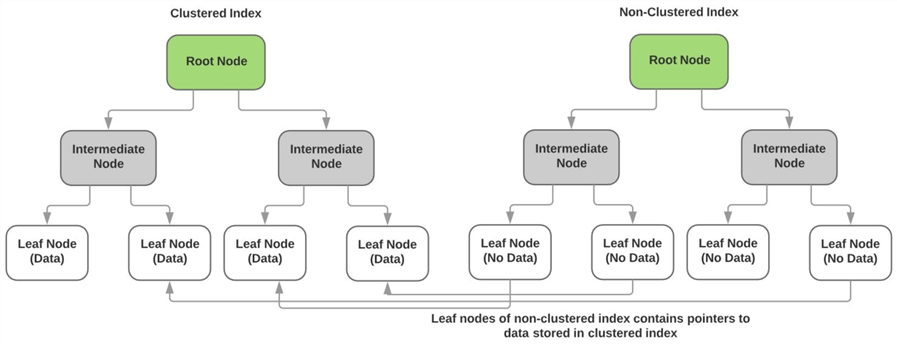
Não-agrupado indexesrelation ao índice de cluster
Como descrito acima, o índice de cluster armazena os dados reais do não-keycolumns nos nós folha do índice. Os nós de folha de cada Não clusteredindex não contêm nenhum dado e, em vez disso, têm ponteiros para a página de dados real(ou nó de folha) do índice agrupado. O diagrama abaixo ilustra issoponto.
índices filtrados
o que é isso?
o índice filtrado é um tipo de índice especial em que apenas uma determinada parte das linhasda tabela é indexada. Com base nos critérios de filtro aplicados Quandoo índice é criado apenas as linhas restantes são indexadas,o que pode economizar espaço, melhorar o desempenho da consulta e reduzir a sobrecarga de manutenção, pois o índice é muito menor.
por que usá-lo?
os índices filtrados são úteis quando você está criando índices em tabelas onde há muitos valores nulos em certas colunas ou certas colunas têm uma cardinalidade muito baixa e você está frequentemente consultando um valor de baixa frequência.
como criá-lo?
o índice filtrado é criado simplesmente adicionando uma cláusula WHERE a qualquer instrução de criação não clusteredindex. O TSQL a seguir é um exemplo da sintaxe paracrie um índice filtrado.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
confirme o uso do Índice
a consulta a seguir deve usar nosso índice recém-criado, pois há muito poucos registros na tabela com ShipDate NULL. Aqui está o TSQL.
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;