este artigo fornece uma introdução do índice não agrupado no SQL Server usando exemplos.
introdução
em um artigo anterior visão geral dos índices clusterizados do SQL Server, exploramos o requisito de um índice e índices clusterizados no SQL Server.
Antes de prosseguir, vamos ter um resumo rápido do Índice de cluster do SQL Server:
- fisicamente tipos de dados de acordo com a chave de índice agrupado
- podemos ter somente um índice agrupado por tabela
- Uma tabela sem um índice de cluster é uma pilha, e isso pode levar a problemas de desempenho
- SQL Server cria automaticamente um índice de cluster para a coluna de chave primária
- Um índice de cluster é armazenado na b-árvore de formato e contém as páginas de dados no nó folha, como mostrado abaixo
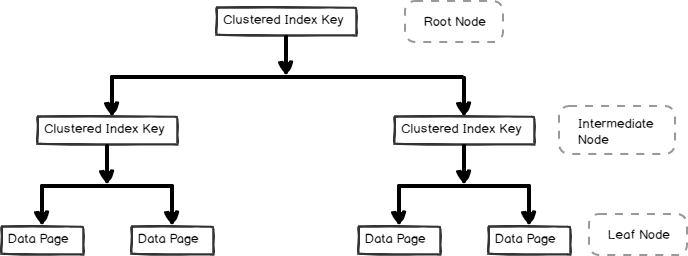
índices Não Clusterizados também são úteis para o desempenho e otimização da consulta, dependendo da carga de trabalho da consulta. Neste artigo, vamos explorar o índice não agrupado e seus internos.
Visão Geral do índice não agrupado no SQL Server
em um índice não agrupado, o nó leaf não contém os dados reais. Consiste em um ponteiro para os dados reais.
- Se a tabela que contém um índice de cluster de nó folha de pontos para o índice de cluster página de dados que consiste em dados reais
- Se a tabela é uma pilha (sem um índice de cluster), nó folha aponta para o heap de página
Na imagem abaixo, podemos observar o nível folha do índice não agrupado apontando para a página de dados no índice de cluster:
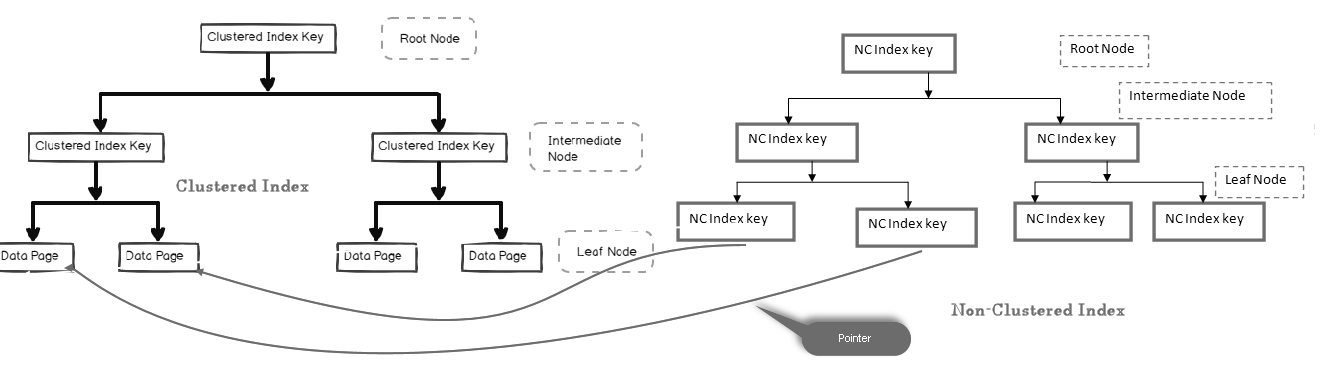
podemos ter vários índices Não agrupados em tabelas SQL porque é um índice lógico e não classifica dados fisicamente em comparação com o índice agrupado.
vamos entender o índice não agrupado no SQL Server usando um exemplo.
-
Criar uma tabela de Empregados, sem qualquer índice de
123456CRIAR TABELA de dbo.Funcionário(EmpID INT,VARCHAR EMpName(50),EmpAge INT,EmpContactNumber VARCHAR(10)); -
Insira alguns registros
123Insert into Empregados values(1,”Raj’,32,8474563217)Insert into Empregados values(2,’kusum’,30,9874563210)Insert into Empregados values(3,’Akshita’,28,9632547120) -
Procure o EmpID 2 e olhar para o real plano de execução de
1Select * from Empregado where EmpID=2Ele faz uma verificação de tabela porque não temos qualquer índice nesta tabela:
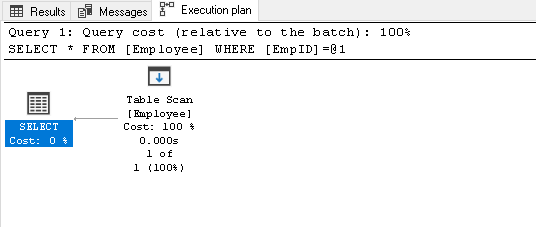
-
Criar um índice em cluster exclusivo na coluna EmpID
1CRIAR ÍNDICE em CLUSTER EXCLUSIVO IX_Clustered_Empployee EM dbo.Empregado (EmpID); -
Procure o EmpID 2 e olhar para o real plano de execução de
neste plano De execução, podemos notar que a tabela de verificação de alterações para uma busca de índice em cluster:
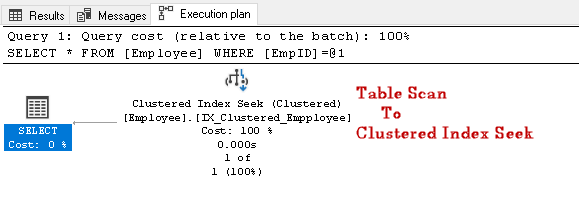
Vamos executar outra consulta SQL para pesquisa de Funcionário que tenha um determinado número de contacto:
|
1
|
Select * from Empregado where EmpContactNumber=’9874563210′
|
não temos um índice em EmpContactNumber coluna, portanto Otimizador de Consulta usa o índice de cluster, mas ele verifica todo o índice para recuperar o registro de:
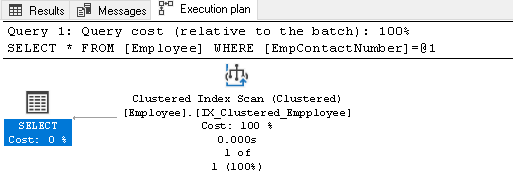
clique com o botão Direito do mouse sobre o plano de execução e seleccione Mostrar o Plano de Execução XML:
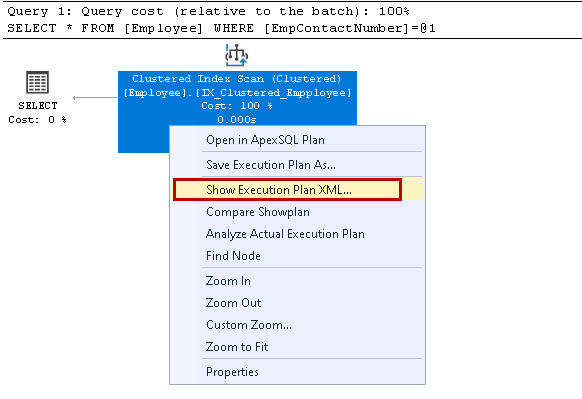
abre o XML plano de execução na nova janela de consulta. Aqui, podemos notar que ele usa a chave de índice agrupado e lê as linhas individuais para obter o resultado:

Vamos inserir mais alguns registros na tabela de Funcionários, usando o seguinte script:
|
1
2
3
|
Insert into Empregados values(4,’Manoj’,38,7892145637)
Insert into Empregados values(5,’João’,33,7900654123)
Insert into Empregados values(6,’Priya’,18,9603214569)
|
temos seis funcionários registros nesta tabela. Agora, execute a instrução select novamente para recuperar registros de funcionários com um número de contato específico:
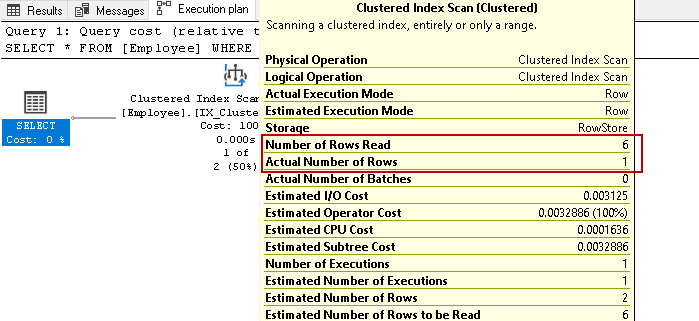
novamente verifica todas as seis linhas para o resultado com base na condição especificada. Imagine que temos milhões de registros na tabela. Se o SQL Server tiver que ler todas as linhas de chave de índice, seria um recurso e uma tarefa demorada.
podemos representar o índice agrupado (não representação real) no formato B-tree de acordo com a imagem a seguir:

na consulta anterior, o SQL Server lê a página do nó raiz e recupera cada página e linha do nó da folha para recuperação de dados.
Agora Vamos criar um único índice não agrupado em cluster no SQL Server na tabela Funcionários no EmpContactNumber coluna como a chave de índice:
|
1
|
CRIAR ÍNDICE AGRUPADO EXCLUSIVO IX_NonClustered_Employee EM dbo.Empregado (EmpContactNumber);
|
Antes de explicar esse índice, volte a executar a instrução SELECT e exibir o plano de execução real:
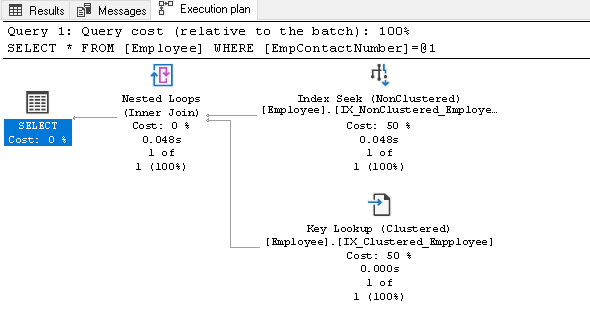
neste plano De execução, podemos ver dois componentes:
- Índice de procura (Agrupada)
- Chave de Pesquisa (em Cluster)
Para compreender esses componentes, precisamos olhar para um índice não clusterizado no SQL Server design. Aqui, você pode ver que o nó folha contém a chave de índice não agrupado (EmpContactNumber) e chave de índice agrupado (EmpID):
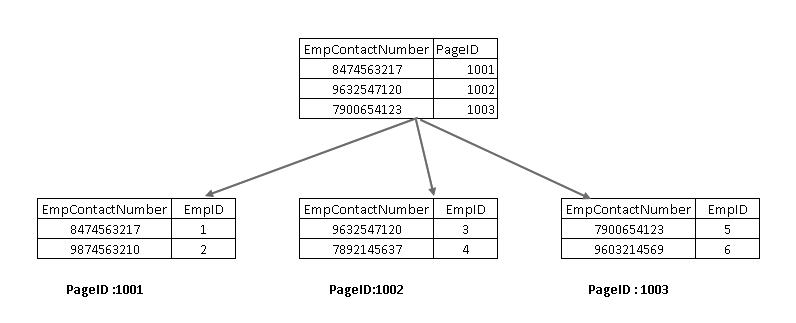
Agora, se executar novamente a instrução SELECT, que atravessam usando a chave de índice não agrupado e aponta para uma página com chave de índice agrupado:
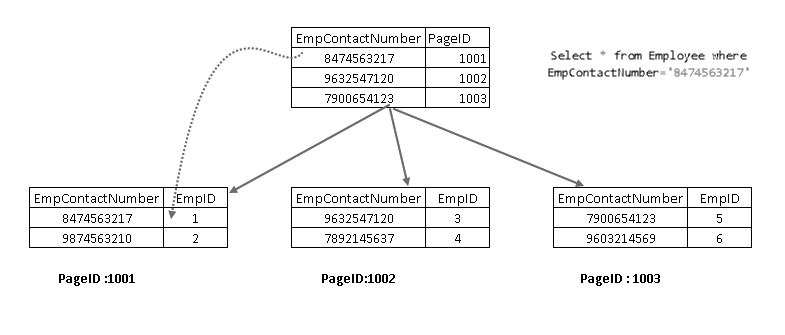
mostra que Ele recupera o registro com uma combinação de chave de índice agrupado e a chave de índice não agrupado. Você pode ver a lógica para a instrução SELECT, como mostrado abaixo:
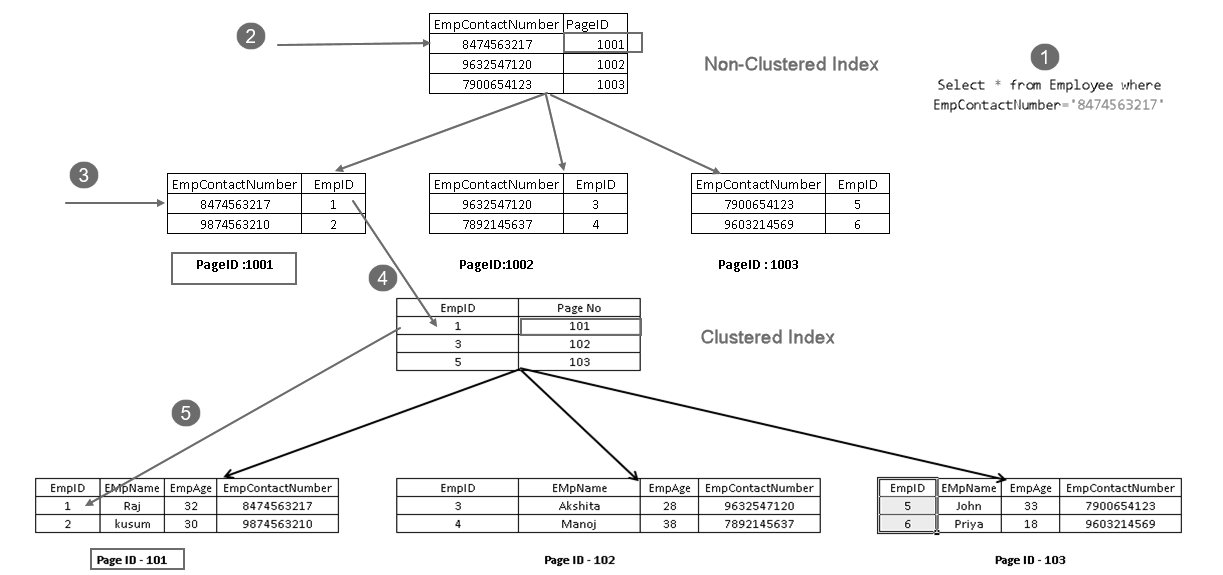
- Um usuário executa uma instrução select para encontrar registros de funcionários equivalentes com um determinado número de contacto
- Otimizador de Consulta usa uma chave de índice não agrupado e descobre que o número da página 1001
- Esta página consiste de uma chave de índice agrupado. Você pode ver EmpID 1 na imagem acima
- SQL Server descobre página nº 101, que consiste em EmpID 1 registros usando a chave de índice agrupado
- lê a linha correspondente e retorna o resultado para o usuário
Anteriormente, vimos que ele lê de seis linhas para recuperar a linha correspondente e retorna uma linha na saída. Vejamos um plano de execução usando o índice não agrupado:

Non-unique non-clustered index in SQL Server
podemos ter vários índices não clusterizados em uma tabela SQL. Anteriormente, criamos um índice exclusivo não agrupado na coluna EmpContactNumber.
antes de criar o índice, execute a seguinte consulta para que tenhamos valor duplicado na coluna EmpAge:
|
1
2
3
|
Update Empregado set EmpAge=32, onde EmpID=2
Update Empregado set EmpAge=38, onde EmpID=6
Update Empregado set EmpAge=38, onde EmpID=3
|
Vamos executar a consulta a seguir para um não-exclusivo de índice não agrupado. Na sintaxe de consulta, não especificamos uma palavra-chave exclusiva e ela diz ao SQL Server para criar um índice não exclusivo:
|
1
|
CRIAR ÍNDICE AGRUPADO NCIX_Employee_EmpAge EM dbo.Empregado(EmpAge);
|
Como sabemos, a chave de um índice deve ser exclusivo. Nesse caso, queremos adicionar uma chave não exclusiva. Surge a pergunta: como o SQL Server tornará essa chave única?
SQL Server faz as seguintes coisas para ele:
- adiciona a chave de índice agrupado na folha e não páginas de folha do não-exclusiva, não-índice de cluster
- Se a chave de índice agrupado é também não-exclusivo, ele adiciona um 4 bytes uniquifier, de modo que a chave de índice é sem igual,
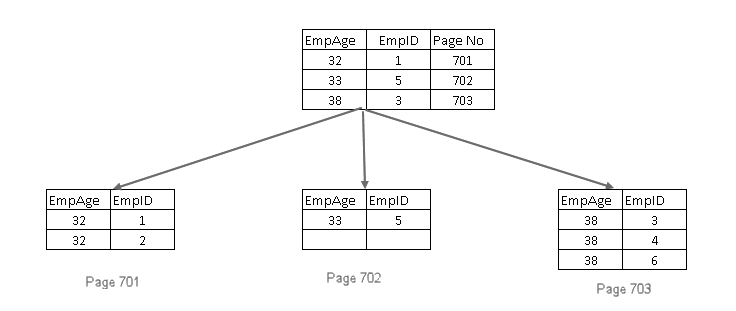
não-colunas de chave de índice não agrupado em cluster no SQL Server
vejamos o seguinte plano de execução real novamente a consulta seguinte:
|
1
2
|
Select * from Empregado
onde EmpContactNumber=’8474563217′
|
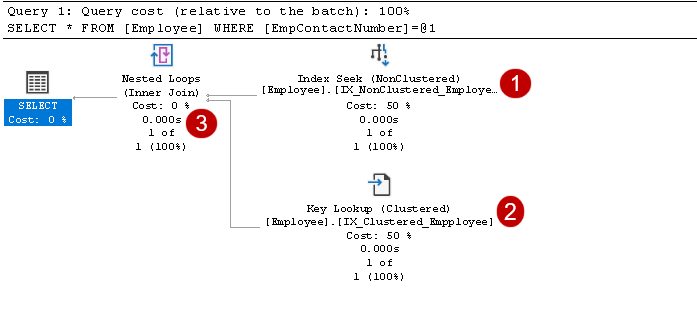
inclui pesquisa de índice de chave e operadores de pesquisa, como mostrado na imagem acima:
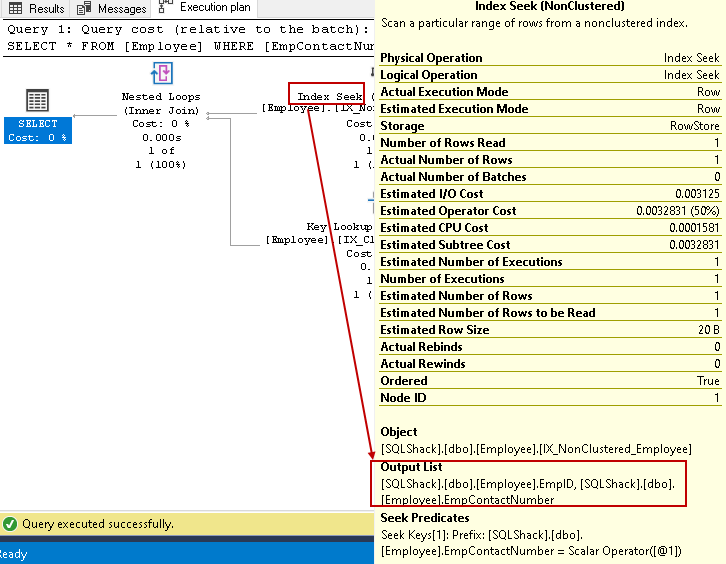
- O índice de procura: SQL Otimizador de Consulta usa um índice de procura de índice não agrupado em cluster e busca EmpID, EmpContactNumber colunas
-
neste passo, o Otimizador de Consulta usa a chave de pesquisa sobre o índice de cluster e de busca de valores para EmpName e EmpAge colunas
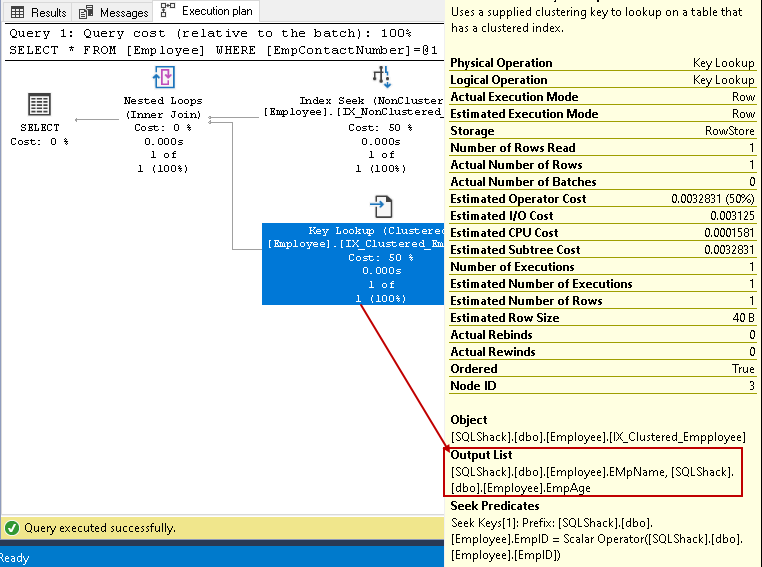
-
neste passo, Otimizador de consulta usa loops aninhados para cada linha de saída a partir do índice não agrupado para combinar com o índice de cluster linha
o loop aninhado pode ser um operador caro para tabelas grandes. Podemos reduzir o custo usando as colunas não-Chave de índice não agrupadas. Especificamos a coluna não chave no índice não agrupado usando a cláusula index.
vamos Deixar cair e criou o índice não agrupado em cluster no SQL Server usando as colunas incluídas:
|
1
2
3
4
5
6
7
|
QUEDA NO ÍNDICE .
VÁ
CRIE UM ÍNDICE EXCLUSIVO NÃO AGRUPADO EM .
(
ASC
)
INCLUEM(EmpName,EmpAge)
|
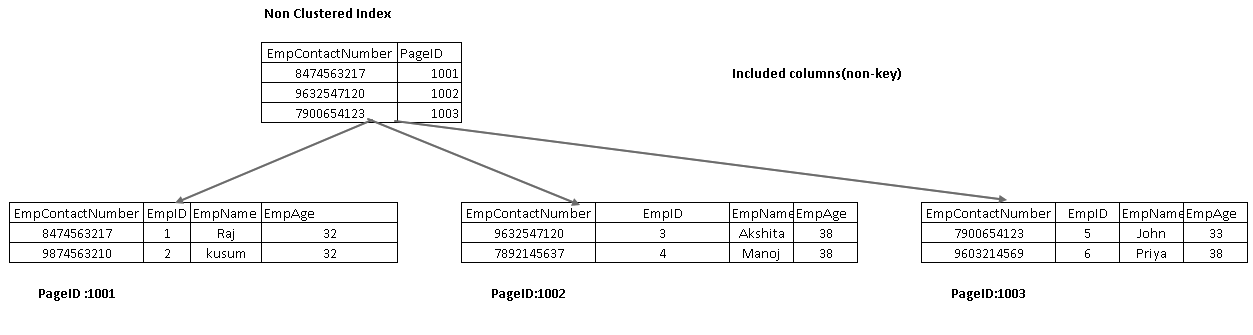
Incluído colunas são parte da folha, nó em uma árvore de índice. Ele ajuda a buscar os dados do próprio índice em vez de percorrer mais para a recuperação de dados.
na imagem a seguir, obtemos as duas colunas incluídas EmpName e EmpAge como parte do nó leaf:
execute novamente a instrução SELECT e visualize o plano de execução real agora. Não temos a chave de pesquisa e de ciclo aninhado neste plano de execução:

Vamos passar o cursor sobre o índice de buscar e exibir a saída de lista de colunas. O SQL Server pode encontrar todas as colunas usando esta busca de índice não agrupada:
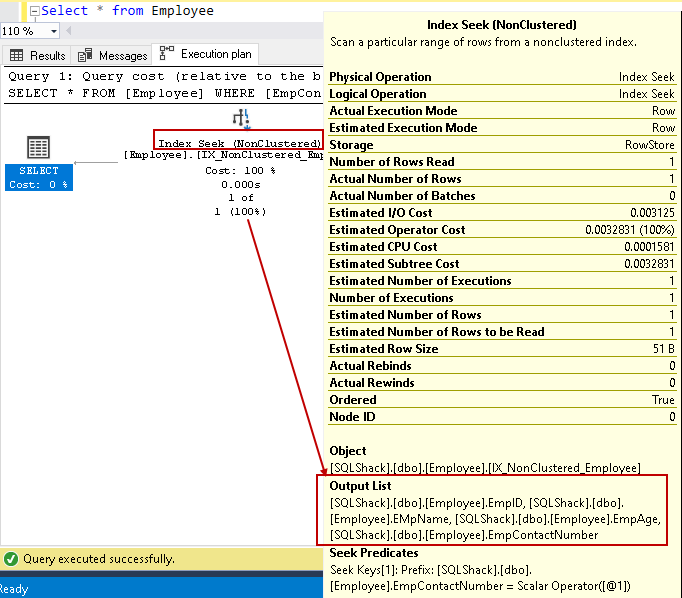
podemos melhorar o desempenho da consulta usando o índice de cobertura com a ajuda de colunas não chave. No entanto, isso não significa que devemos todas as colunas não-chave na definição do Índice. Devemos ter cuidado no design do índice e devemos testar o comportamento do Índice antes da implantação no ambiente de produção.
conclusão
neste artigo, exploramos o índice não agrupado no SQL Server e seu uso em combinação com o índice agrupado. Devemos projetar cuidadosamente o índice de acordo com a carga de trabalho e o comportamento da consulta.
- Autor
- Posts Recentes

ele é o criador de uma das maiores coleções online gratuitas de artigos sobre um único tópico, com sua série de 50 partes no SQL Server sempre em grupos de disponibilidade. Com base em sua contribuição para a comunidade SQL Server, ele foi reconhecido com vários prêmios, incluindo o prestigioso “melhor autor do ano” continuamente em 2020 e 2021 na SQLShack.
Raj está sempre interessado em novos desafios por isso, se você precisar de ajuda de consultoria sobre qualquer assunto coberto em seus escritos, ele pode ser alcançado em rajendra.gupta16 @ gmail.com
Ver todos os posts por Rajendra Gupta
- Use o BRAÇO de modelos para implantar o Azure recipiente de instâncias do SQL Server Linux imagens – 21 de dezembro de 2021
- área de trabalho Remota de acesso da AWS RDS para SQL Server com o Amazon RDS Personalizada – dezembro 14, 2021
- Armazenamento de arquivos do SQL Server no Armazenamento Persistente para Azure Recipiente Instâncias de dezembro de 10, 2021