acest articol oferă o introducere a indexului non-cluster în SQL Server folosind exemple.
Introducere
într-un articol anterior Prezentare generală a indexurilor SQL Server grupate, am explorat cerința unui index și a indexurilor grupate în SQL Server.
înainte de a continua, să avem un rezumat rapid al indexului SQL Server pus în cluster:
- acesta sortează fizic datele în funcție de cheia indexului pus în cluster
- putem avea un singur index pus în cluster pe tabel
- un tabel fără un index pus în cluster este o grămadă și ar putea duce la probleme de performanță
- SQL Server creează automat un index pus în cluster pentru coloana cheie primară
- index este stocat în format B-Tree și conține paginile de date din nodul leaf, așa cum se arată mai jos
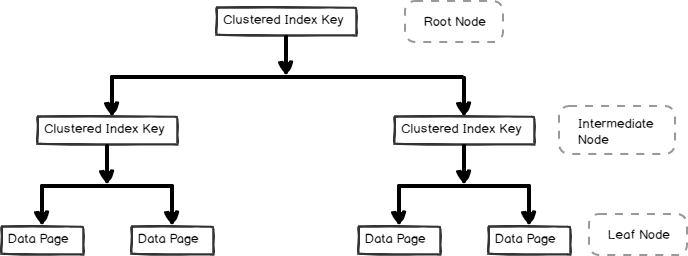
indici non-cluster sunt, de asemenea, utile pentru performanța interogării și optimizarea în funcție de volumul de lucru al interogării. În acest articol, să explorăm indicele non-grupat și internele sale.
Prezentare generală a indexului non-cluster în SQL Server
într-un index non-cluster, nodul leaf nu conține datele reale. Se compune dintr-un pointer la datele reale.
- dacă tabelul conține un index pus în cluster, nodul frunzei indică pagina de date indexate în cluster care constă din date reale
- dacă tabelul este un heap (fără un index pus în cluster), nodul frunzei indică pagina heap
în imaginea de mai jos, ne putem uita la nivelul frunzei indicelui care nu este pus în cluster indicând spre pagina de date din indexul pus în cluster:
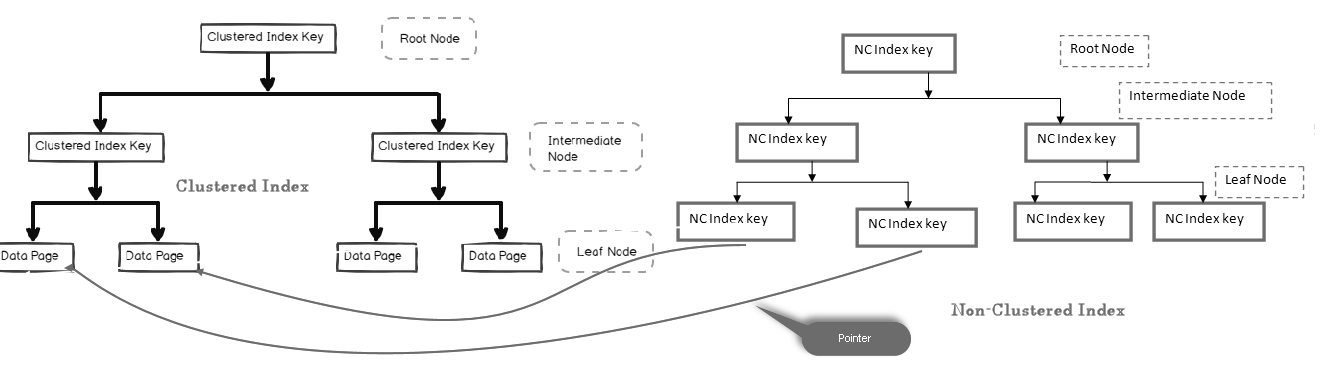
putem avea mai multe indici non-cluster în tabelele SQL, deoarece este un index logic și nu sortează datele fizic în comparație cu indicele cluster.
să înțelegem indexul non-cluster în SQL Server folosind un exemplu.
-
creați un tabel angajat fără nici un index pe ea
123456creați tabelul dbo.Angajat(EmpID int,EMpName VARCHAR(50),EmpAge int,EmpContactNumber VARCHAR(10)); -
introduceți câteva înregistrări în ea
123introduceți în valorile angajaților (1, ‘Raj’,32,8474563217)introduceți în valorile angajaților (2,’kusum’,30,9874563210)introduceți în valorile angajaților (3, ‘Akshita’,28,9632547120) -
căutați EmpID 2 și căutați planul real de execuție al acestuia
1selectați * de la angajat în cazul în care EmpID=2ea face o scanare de masă, deoarece nu avem nici un index pe acest tabel:
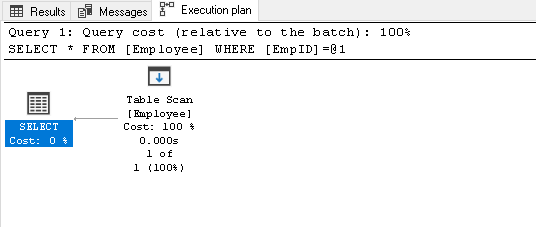
-
creați un index unic pus în cluster pe coloana EmpID
1creați unic IX_CLUSTERED_EMPPLOYEE index CLUSTERED pe dbo.Angajat (EmpID); -
căutați EmpID 2 și căutați planul real de execuție al acestuia
în acest plan de execuție, putem observa că scanarea tabelului se schimbă într-un index pus în cluster caută:
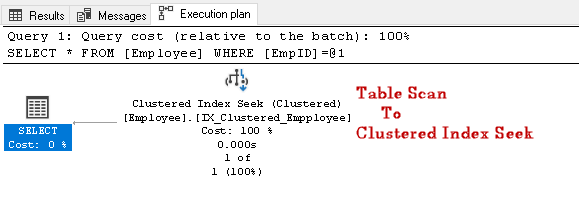
să executăm o altă interogare SQL pentru căutarea angajatului care are un anumit număr de contact:
|
1
|
selectați * de la angajat în cazul în care EmpContactNumber=’9874563210′
|
nu avem un index pe coloana EmpContactNumber, prin urmare, Query Optimizer utilizează indexul pus în cluster, dar scanează întregul index pentru preluarea înregistrării:
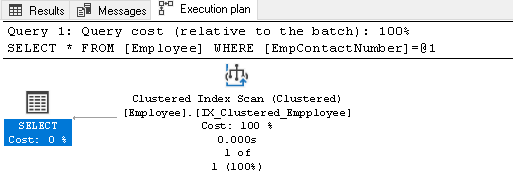
faceți clic dreapta pe planul de execuție și selectați Afișare plan de execuție XML:
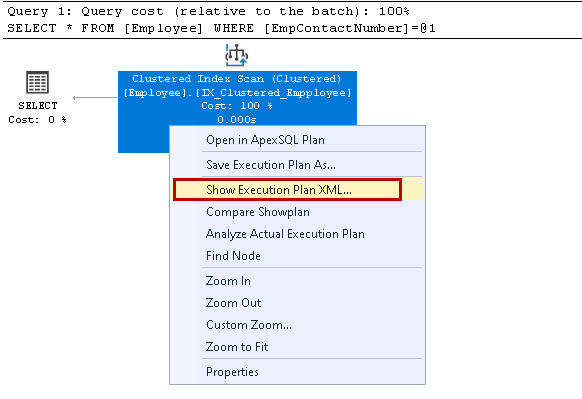
se deschide planul de execuție XML în fereastra de interogare nouă. Aici, observăm că folosește cheia index cluster și citește rândurile individuale pentru recuperarea rezultatului:

să inserăm câteva înregistrări în tabelul angajat folosind următorul script:
|
1
2
3
|
introduceți în valorile angajaților (4, ‘Manoj’,38,7892145637)
introduceți în valorile angajaților (5, ‘John’,33,7900654123)
introduceți în valorile angajaților (6, ‘Priya’,18,9603214569)
|
avem șase înregistrări ale angajaților în acest tabel. Acum, executați din nou instrucțiunea select pentru preluarea înregistrărilor angajaților cu un anumit număr de contact:
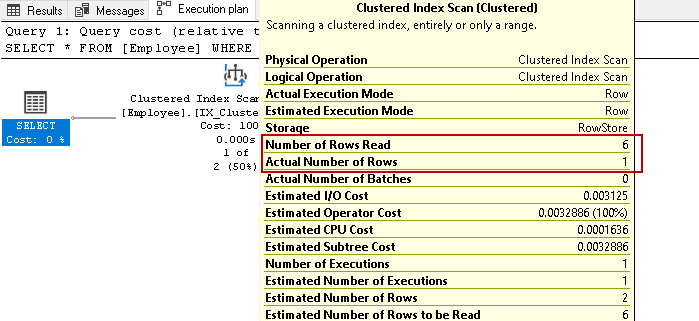
scanează din nou toate cele șase rânduri pentru rezultat pe baza condiției specificate. Imaginați-vă că avem milioane de înregistrări în tabel. Dacă SQL Server trebuie să citească toate rândurile cheie index, ar fi o sarcină consumatoare de resurse și de timp.
putem reprezenta indexul grupat (nu reprezentarea reală) în formatul arborelui B conform următoarei imagini:

în interogarea anterioară, SQL Server citește pagina nod rădăcină și preia fiecare pagină nod frunze și rând pentru recuperarea datelor.
acum să creăm un index unic non-cluster în SQL Server pe tabelul angajat pe coloana EmpContactNumber ca cheie index:
|
1
|
creați un INDEX unic NONCLUSTERED IX_NONCLUSTERED_EMPLOYEE pe dbo.Angajat (EmpContactNumber);
|
înainte de a explica acest index, rulați din nou instrucțiunea SELECT și vizualizați planul de execuție real:
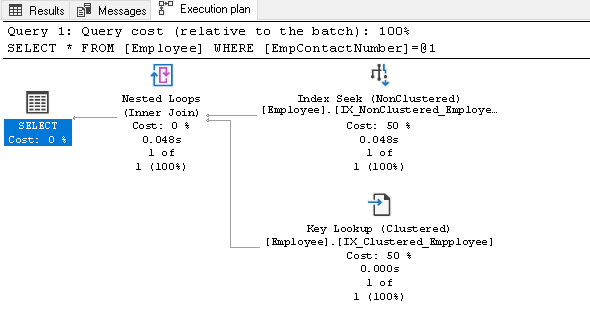
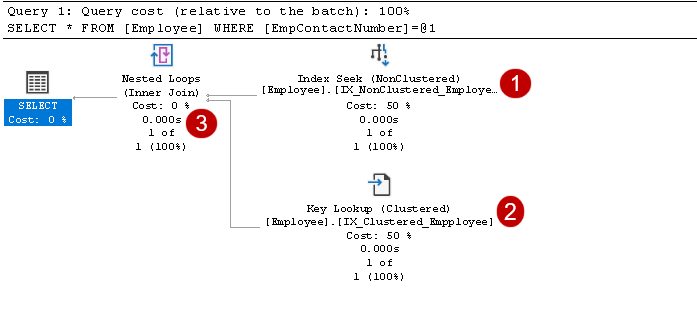
în acest plan de execuție, putem vedea două componente:
- Index caută (NonClustered)
- căutare cheie (grupate)
pentru a înțelege aceste componente, trebuie să ne uităm la un index non-cluster în SQL Server design. Aici, puteți vedea că nodul leaf conține cheia index non-cluster (EmpContactNumber) și cheia index cluster (EmpID):
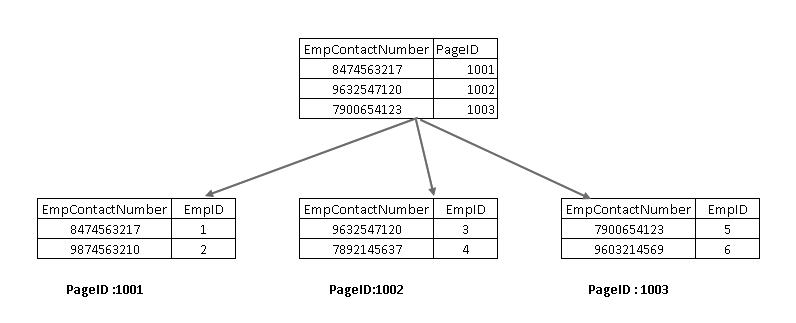
acum, dacă rulați din nou instrucțiunea SELECT, aceasta traversează folosind cheia index non-cluster și indică o pagină cu cheie index cluster:
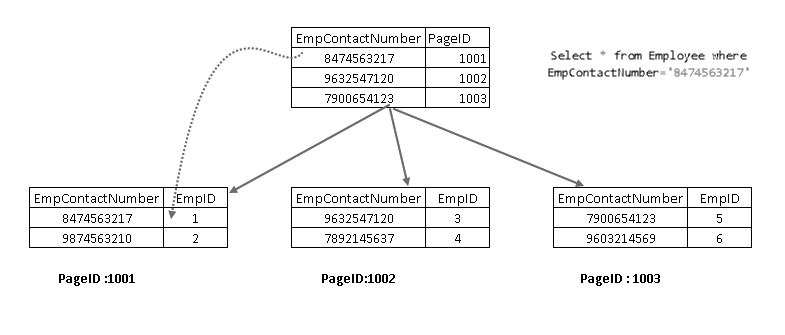
arată că preia înregistrarea cu o combinație de cheie index cluster și cheie index non-cluster. Puteți vedea logica completă pentru instrucțiunea SELECT așa cum se arată mai jos:
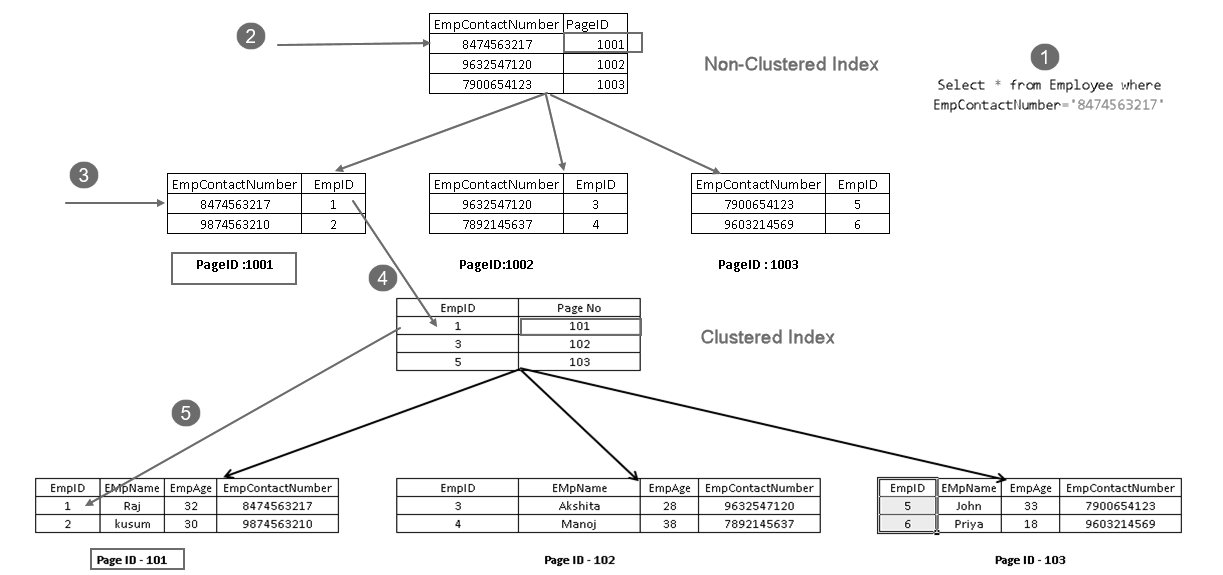
- un utilizator execută o instrucțiune select pentru a găsi înregistrările angajaților care se potrivesc cu un număr de contact specificat
- Query Optimizer utilizează o cheie index non-cluster și află numărul paginii 1001
- această pagină constă dintr-o cheie index cluster. Puteți vedea EmpID 1 în imaginea de mai sus
- SQL Server află pagina nr 101 care constă din înregistrări EmpID 1 folosind tasta index cluster
- citește rândul de potrivire și returnează ieșirea utilizatorului
anterior, am văzut că citește șase rânduri pentru a prelua rândul de potrivire și returnează un rând în ieșire. Să ne uităm la un plan de execuție folosind indexul non-cluster:

index non-unic non-cluster în SQL Server
putem avea mai multe indici non-cluster într-un tabel SQL. Anterior, am creat un index unic non-cluster pe coloana EmpContactNumber.
înainte de a crea indexul, executați următoarea interogare, astfel încât să avem o valoare duplicată în coloana EmpAge:
|
1
2
3
|
actualizare angajat set EmpAge = 32 unde EmpID = 2
actualizare angajat set EmpAge = 38 unde EmpID=6
actualizare angajat set EmpAge = 38 unde EmpID=3
|
să executăm următoarea interogare pentru un index non-unic non-clustered. În sintaxa de interogare, nu specificați un cuvânt cheie unic, și spune SQL Server pentru a crea un index non-unic:
|
1
|
creați Index NONCLUSTERED NCIX_Employee_EmpAge pe dbo.Angajat (EmpAge);
|
după cum știm, cheia unui index ar trebui să fie unică. În acest caz, dorim să adăugăm o cheie non-unică. Se pune întrebarea: cum va face SQL Server această cheie ca unică?
SQL Server face următoarele lucruri pentru el:
- se adaugă cheia indexului pus în cluster în paginile frunze și non-frunze ale indexului non-unic pus în cluster
- dacă cheia indexului pus în cluster este, de asemenea, non-unică, se adaugă un unicificator de 4 octeți, astfel încât cheia index să fie unică
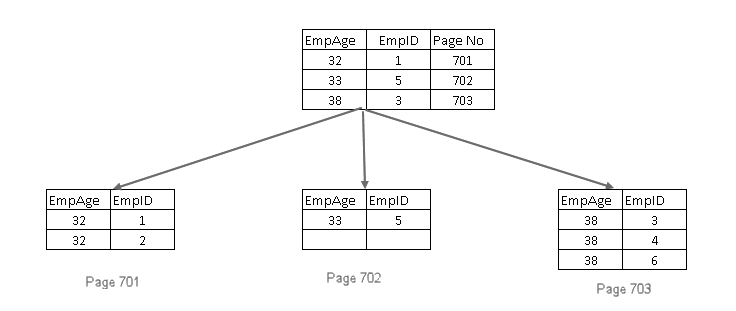
includ coloane non-cheie în index non-cluster în SQL Server
să ne uităm la următorul plan de execuție reală din nou de următoarea interogare:
|
1
2
|
selectați * de la angajat
unde EmpContactNumber=’8474563217′
|
acesta include căutare index și operatorii de căutare cheie, așa cum se arată în imaginea de mai sus:
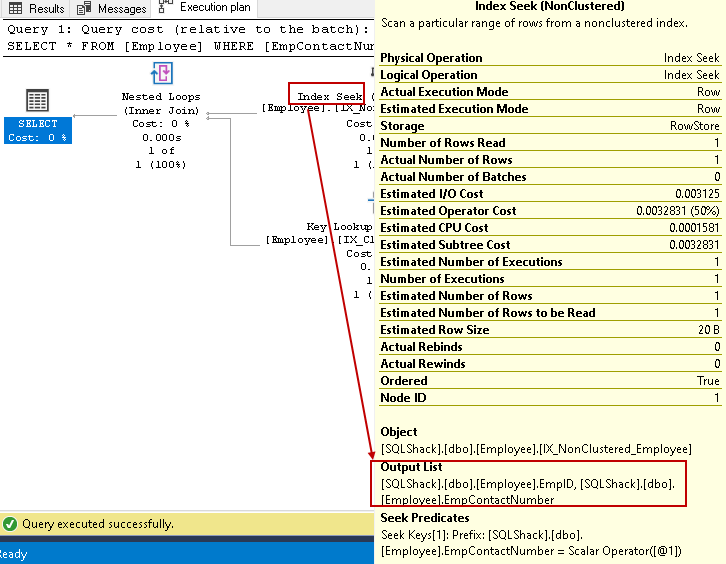
- indicele caută: SQL query Optimizer utilizează un index seek pe indexul non-cluster și preia EmpID, EmpContactNumber coloane
-
în acest pas, Query Optimizer utilizează căutare cheie pe indexul cluster și preia valori pentru empname și EmpAge coloane
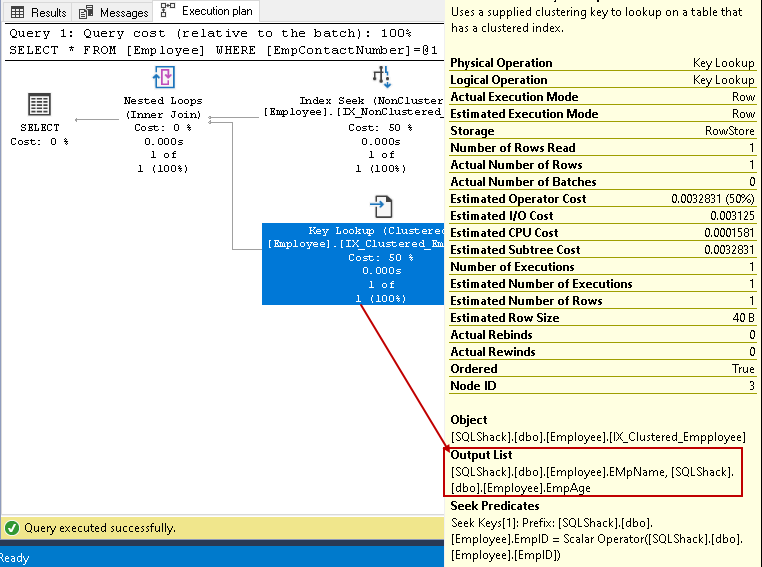
-
în acest pas, Query Optimizer utilizează buclele imbricate pentru fiecare ieșire rând din indexul non-cluster pentru potrivirea cu rândul indexului cluster
bucla imbricată ar putea fi un operator costisitor pentru mesele mari. Putem reduce costul folosind coloanele non-cheie index non-grupate. Specificăm coloana non-cheie din indexul non-cluster folosind clauza index.
să picătură și a creat indexul non-grupate în SQL Server folosind coloanele incluse:
|
1
2
3
4
5
6
7
|
DROP INDEX pe .
DU-TE
CREAREA INDEX UNIC NONCLUSTERED PE .
(
ASC
)
INCLUDE (EmpName, EmpAge)
|
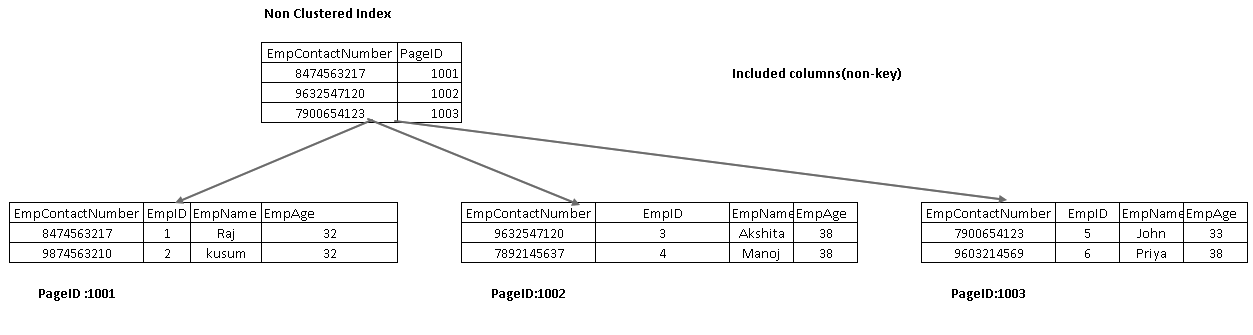
coloanele incluse fac parte din nodul frunzei dintr-un arbore index. Ajută la preluarea datelor din index în sine, în loc să traverseze mai departe pentru recuperarea datelor.
în imaginea următoare, obținem ambele coloane incluse EmpName și EmpAge ca parte a nodului frunzei:
executați din nou instrucțiunea SELECT și vizualizați acum planul de execuție real. Nu avem căutare cheie și buclă imbricată în acest plan de execuție:

să treceți cursorul peste index căuta și vizualiza lista de coloane de ieșire. SQL Server pot găsi toate coloanele folosind acest index non-grupate caută:
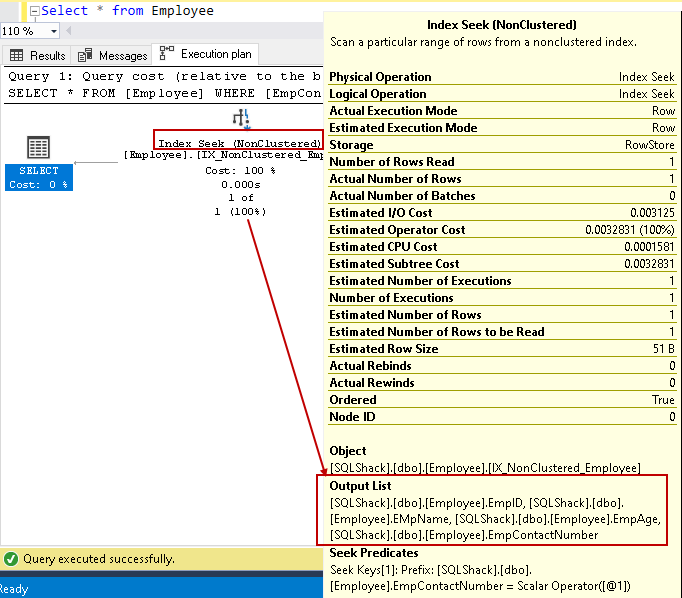
putem îmbunătăți performanța interogării folosind indexul de acoperire cu ajutorul coloanelor non-cheie incluse. Cu toate acestea, aceasta nu înseamnă că ar trebui să toate coloanele non-cheie în definiția indexului. Ar trebui să fim atenți în proiectarea indexului și ar trebui să testăm comportamentul indexului înainte de implementarea în mediul de producție.
concluzie
în acest articol, am explorat indexul non-pus în cluster în SQL Server și utilizarea acestuia în combinație cu indexul pus în cluster. Ar trebui să proiectăm cu atenție indexul în funcție de volumul de muncă și comportamentul interogării.
- autor
- Postări recente

este creatorul uneia dintre cele mai mari colecții online gratuite de articole pe un singur subiect, cu seria sa de 50 de părți pe SQL Server Always On Availability Groups. Pe baza contribuției sale la comunitatea SQL Server, a fost recunoscut cu diverse premii, inclusiv prestigiosul „cel mai bun autor al anului” continuu în 2020 și 2021 la SQLSHACK.
Raj este întotdeauna interesat de noi provocări, așa că dacă aveți nevoie de ajutor de consultanță cu privire la orice subiect acoperit în scrierile sale, el poate fi contactat la rajendra.gupta16 @ gmail.com
Vezi toate mesajele de Rajendra Gupta
- utilizați șabloane ARM pentru a implementa instanțe Azure container cu imagini SQL Server Linux-21 decembrie 2021
- acces desktop la distanță pentru AWS RDS SQL Server cu Amazon RDS Custom – 14 decembrie 2021
- stocați fișiere SQL Server în stocare persistentă pentru instanțe Azure Container-decembrie 10, 2021