av: ben Snaidero
översikt
i det här avsnittet kommer vi att täcka saker du behöver veta om icke-clustered index.
vad är ett icke-grupperat index
ett icke-grupperat index (eller regelbundet B-trädindex) är ett index där ordningen på raderna inte matchar den fysiska ordningen för de faktiska data. Det är iställetordnas av kolumnerna som utgör indexet. I ett icke-grupperat index innehåller inte indexets bladsidor några faktiska data, utan innehåller i stället pointer till de faktiska data. Dessa pekare pekar på den grupperade indexdatasidan där den faktiska data finns (eller heapsidan om inget grupperat index finns i tabellen).
varför skapa icke-klustrade index
den största fördelen med att ha en icke-klustrade index på en tabell är det ger fastaccess till data. Indexet gör det möjligt för databasmotorn att snabbt hitta datautan att behöva skanna igenom hela tabellen. Som en tabell blir större detär mycket viktigt att de korrekta index läggs till i tabellen, som utan anyindexes frågeprestanda kommer att sjunka dramatiskt.
När ska icke-grupperade index skapas
det finns två fall där det är fördelaktigt att ha ett icke-grupperat index på ett bord. Först när det finns mer än en uppsättning kolumner som används i where clauseof-frågor som kommer åt tabellen. Ett andra index (förutsatt att det redan finnsett grupperat index på primärnyckelkolumnen) kommer att påskynda exekveringstiderna och minska för de andra frågorna. För det andra, om dina frågor ofta kräver dataatt returneras i en viss ordning, med ett index på dessa kolumner kan minska mängden CPU och minne som krävs eftersom ytterligare sortering inte behöver göraseftersom data i indexet redan är beställt.
följande exempel showshow ingen tabellsökning krävs för att hämta data, bara en indexsökning av icke-clusteredindex och en sökning av det klustrade indexet för att få data. Observera också attingen sort krävs eftersom data redan är i rätt ordning.
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

hur man skapar ett icke-klustrat index
att skapa ett icke-klustrat index är i princip detsamma som att skapa klustrat index,men istället för att specificera clusteredclause anger vi att det inte är klustrat. Vi kan också utelämna denna klausul helt och hållet eftersom en icke-grupperad är standard när du skapar ett index.
TSQL nedan visar ett exempel på varje uttalande.
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
Vad är ett täckande index
Acovering index är ett index som består av alla (eller flera) av kolumnerna som krävs för att uppfylla en fråga som nyckelkolumner i indexet. När ett täckningsindex kan användas för att utföra en fråga krävs färre IO-operationer eftersom optimizerno längre måste utföra extra sökningar för att hämta de faktiska tabelldata.
nedan är ett exempel på TSQL som du kan använda för att skapa acovering index i produkttabellen.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
följande TSQL-fråga kan nu köras genom att bara komma åt det nya indexetvi skapade just eftersom alla kolumner i frågan är en del av indexet.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
followingEXPLAIN-Planen bekräftar att det inte krävs någon extra sökning för den här frågan.

vad är ett index med inkluderade kolumner
ett index Skapat med inkluderade kolumner är ett icke-grupperat index som också inkluderarnon-key kolumner i indexets bladnoder, liknande ett grupperat index. Det finns ett par fördelar med att använda inkluderade kolumner. Först ger det digförmågan att inkludera kolumntyper som inte är tillåtna som indexnycklar i dinindex. När alla kolumner i din fråga är antingen en indexnyckel ellerinkluderad kolumn behöver frågan inte längre göra en extra sökning för att få alladata som behövs för att tillfredsställa frågan vilket resulterar i färre diskoperationer. Detta liknar det täckningsindex som nämnts tidigare.
med samma exempelFrån ovan kommer följande TSQL att skapa samma index utom med productnumber columnreferenced som en inkluderad kolumn och inte en indextangentkolumn.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
använda samma fråga som ovan detta bör också kunna köra utan requiringany extra uppslagningar.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
followingEXPLAIN-Planen bekräftar att det inte krävs någon extra sökning för den här frågan också.

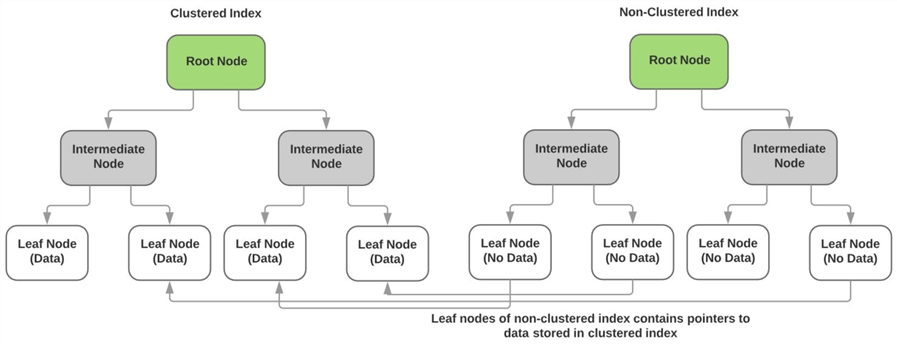
icke-grupperade indexrelation till grupperade index
som beskrivits ovan lagrar det grupperade indexet de faktiska data för icke-nyckelkolumnerna i indexets bladnoder. Bladnoderna för varje icke-clusteredindex innehåller inga data och har istället pekare till den faktiska datasidan(eller bladnoden) för det klustrade indexet. Diagrammet nedan illustrerar dettapunkt.
filtrerade index
Vad är det?
Afiltrerat index är en speciell indextyp där endast en viss del av tabellraderna indexeras. Baserat på filterkriterierna som tillämpas närindexet skapas endast de återstående raderna indexeras vilket kan spara på utrymme, förbättra frågans prestanda och minska underhållskostnaderna eftersom indexet är mycketmindre.
Varför använda den?
filtrerade index är användbara när du skapar index på tabeller där det finns många NULL-värden i vissa kolumner eller vissa kolumner har en mycket låg kardinalitetoch du frågar ofta ett lågfrekvensvärde.
Hur skapar man det?
Afiltered index skapas helt enkelt genom att lägga till en where-klausul i alla icke-clusteredindex-skapningsuttalanden. Följande TSQL är ett exempel på syntaxen tillskapa ett filtrerat index.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
bekräfta Indexanvändning
följande fråga bör använda vårt nyskapade index eftersom det finns väldigt få poster i tabellen med ShipDate NULL. Här är TSQL.
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;