den här artikeln ger en introduktion av det icke-klustrade indexet i SQL Server med exempel.
Inledning
i en tidigare artikel översikt över SQL Server klustrade index, undersökte vi kravet på ett index och klustrade index i SQL Server.
innan vi fortsätter, låt oss få en snabb sammanfattning av SQL Server clustered index:
- det sorterar fysiskt data enligt clustered index key
- vi kan bara ha ETT clustered index per tabell
- en tabell utan ett clustered index är en heap, och det kan leda till prestandaproblem
- SQL Server skapar automatiskt ett clustered index för den primära nyckelkolumnen
- ett clustered index Index lagras i b-trädformat och innehåller datasidorna i bladnoden, som visas nedan
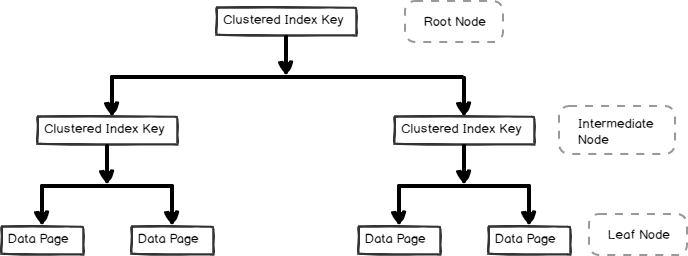
icke-klustrade index är också användbara för frågeprestanda och optimering beroende på frågans arbetsbelastning. I den här artikeln, låt oss utforska det icke-klustrade indexet och dess interna.
översikt över det icke-grupperade indexet i SQL Server
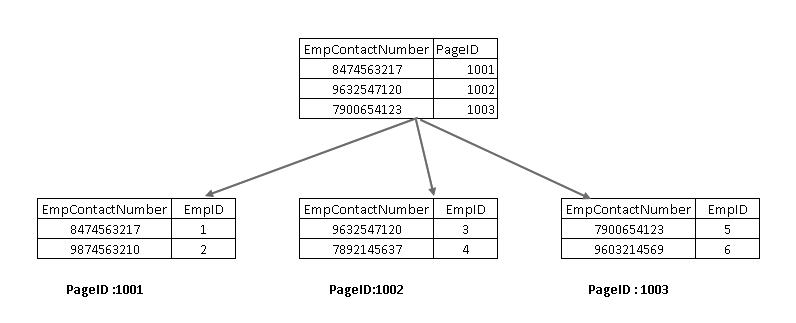
i ett icke-grupperat index innehåller bladnoden inte de faktiska data. Den består av en pekare till de faktiska data.
- om tabellen innehåller ett grupperat index pekar bladnoden på den grupperade indexdatasidan som består av faktiska data
- om tabellen är en heap (utan ett grupperat index) pekar bladnoden på heapsidan
i bilden nedan kan vi titta på bladnivån för icke-grupperat index som pekar mot datasidan i det grupperade indexet:
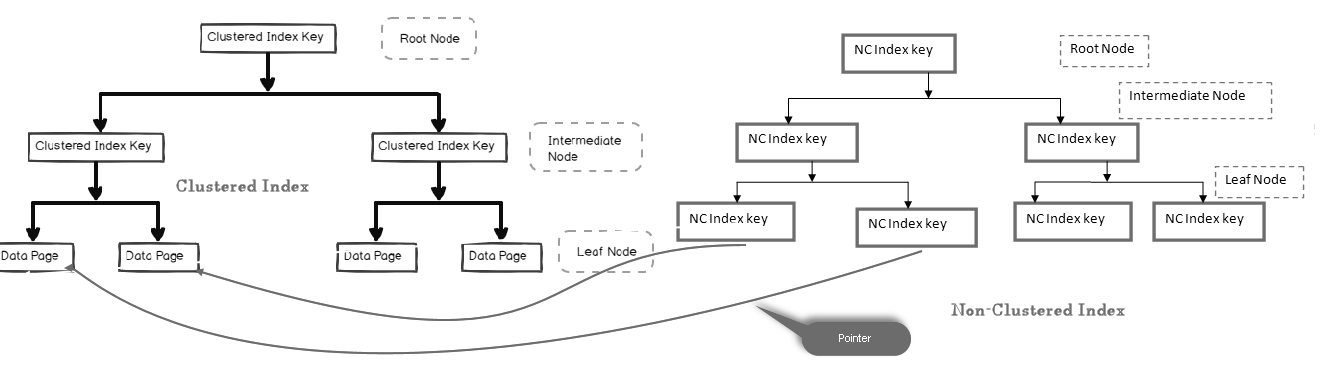
vi kan ha flera icke-grupperade index i SQL-tabeller eftersom det är ett logiskt index och inte sorterar data fysiskt jämfört med det grupperade indexet.
Låt oss förstå det icke-grupperade indexet i SQL Server med ett exempel.
-
skapa en anställd tabell utan index på den
123456Skapa tabell dbo.Anställd(EmpID INT,EMpName VARCHAR(50),EmpAge INT,Empkontaktnummer VARCHAR(10)); -
sätt in några poster i den
123infoga i anställdas värden (1, ’Raj’,32,8474563217)infoga i anställdas värden (2, ’kusum’,30,9874563210)infoga i anställdas värden (3, ’Akshita’,28,9632547120) -
Sök efter EmpID 2 och leta efter den faktiska genomförandeplanen för den
1Välj * från anställd där EmpID=2det gör en tabellsökning eftersom vi inte har något index på den här tabellen:
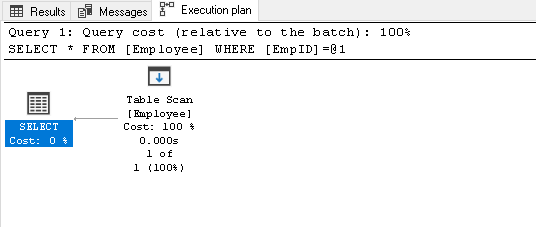
-
skapa ett unikt grupperat index i EmpID-kolumnen
1skapa unika klustrade INDEX ix_clustered_empployee på dbo.Anställd (EmpID); -
Sök efter EmpID 2 och leta efter den faktiska genomförandeplanen för den
i den här exekveringsplanen kan vi märka att tabellskanningen ändras till en grupperad indexsökning:
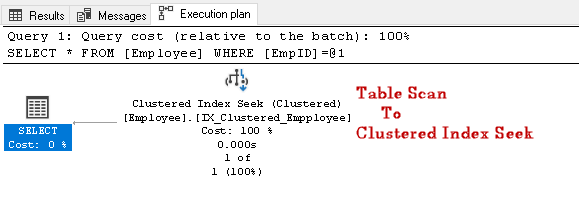
Låt oss utföra en annan SQL-fråga för att söka anställd som har ett specifikt kontaktnummer:
|
1
|
Välj * från anställd där EmpContactNumber=’9874563210′
|
vi har inte ett index på empcontactnumber kolumnen därför Query Optimizer använder klustrade index, men det skannar hela indexet för att hämta posten:
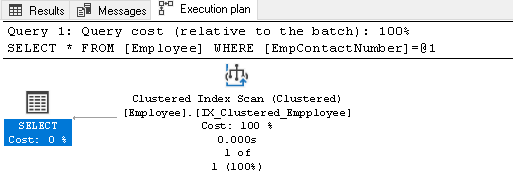
högerklicka på exekveringsplanen och välj Visa Exekveringsplan XML:
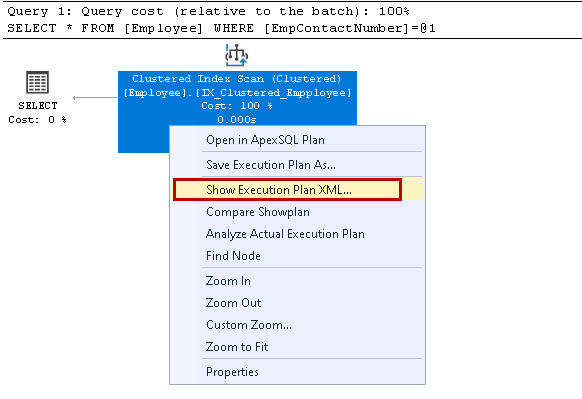
det öppnar XML-exekveringsplanen i det nya frågefönstret. Här märker vi att den använder den grupperade indexnyckeln och läser de enskilda raderna för att hämta resultatet:

låt oss infoga några fler poster i Medarbetartabellen med följande skript:
|
1
2
3
|
infoga i anställdas värden (4, ’Manoj’,38,7892145637)
infoga i anställdas värden (5, ’John’,33,7900654123)
infoga i anställdas värden (6, ’Priya’,18,9603214569)
|
vi har sex anställdas poster i denna tabell. Kör nu select-uttalandet igen för att hämta anställdas poster med ett specifikt kontaktnummer:
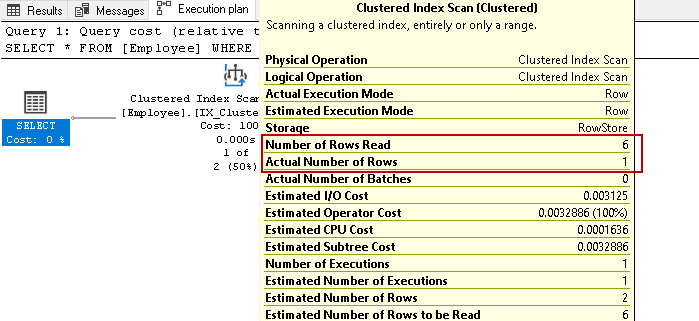
den skannar igen alla sex raderna för resultatet baserat på det angivna villkoret. Tänk dig att vi har miljontals poster i tabellen. Om SQL Server måste läsa alla indexnyckelrader skulle det vara en resurs och tidskrävande uppgift.
vi kan representera grupperat index (inte faktisk representation) i b-trädformatet enligt följande bild:

i föregående fråga läser SQL Server rotnodsidan och hämtar varje bladnodsida och rad för datahämtning.
Låt oss nu skapa ett unikt icke-grupperat index i SQL Server på Medarbetartabellen i kolumnen EmpContactNumber som indexnyckel:
|
1
|
skapa unika NONCLUSTERED INDEX ix_nonclustered_employee på dbo.Anställd (EmpContactNumber);
|
innan vi förklarar detta index, kör SELECT-uttalandet igen och visa den faktiska exekveringsplanen:
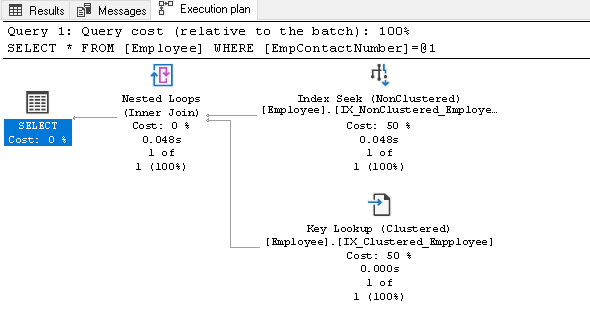
i denna exekveringsplan kan vi se två komponenter:
- Index söka (NonClustered)
- Key Lookup (Clustered)
för att förstå dessa komponenter måste vi titta på ett icke-grupperat index i SQL Server design. Här kan du se att bladnoden innehåller den icke-grupperade indexnyckeln (EmpContactNumber) och grupperade indexnyckeln (EmpID):
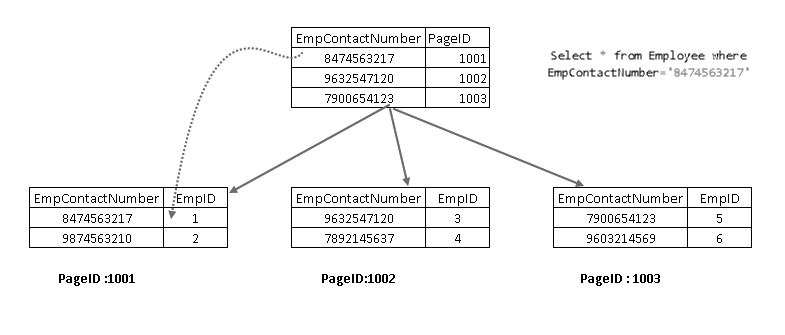
nu, om kör SELECT-satsen, går den igenom med den icke-grupperade indexnyckeln och pekar på en sida med grupperad indexnyckel:
det visar att det hämtar posten med en kombination av klustrad indexnyckel och icke-klustrad indexnyckel. Du kan se fullständig logik för SELECT-satsen som visas nedan:
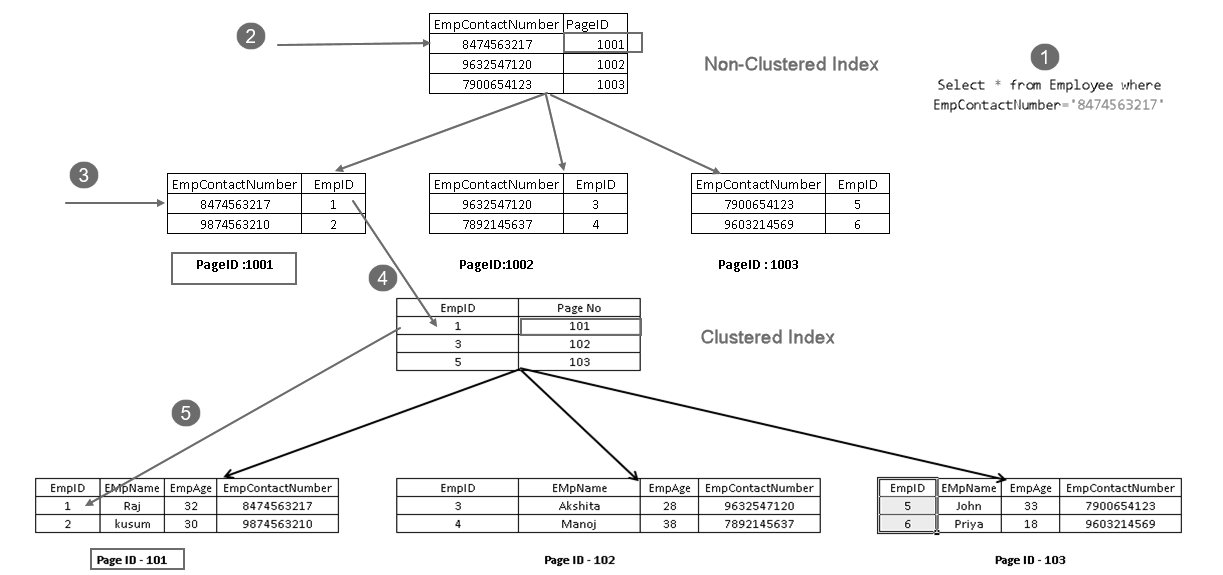
- en användare utför ett select-uttalande för att hitta anställdas poster som matchar ett angivet kontaktnummer
- Query Optimizer använder en icke-grupperad indexnyckel och får reda på sidnumret 1001
- den här sidan består av en grupperad indexnyckel. Du kan se EmpID 1 i ovanstående bild
- SQL Server får reda på Sida nr 101 som består av EmpID 1-poster med den grupperade indexnyckeln
- den läser matchande raden och returnerar utmatningen till användaren
Tidigare såg vi att den läser sex rader för att hämta matchande rad och returnerar en rad i utmatningen. Låt oss titta på en exekveringsplan med det icke-grupperade indexet:

icke-unikt icke-grupperat index i SQL Server
vi kan ha flera icke-grupperade index i en SQL-tabell. Tidigare skapade vi ett unikt icke-grupperat index i kolumnen EmpContactNumber.
innan du skapar indexet, kör följande fråga så att vi har dubblettvärde i EmpAge-kolumnen:
|
1
2
3
|
uppdatera anställd Set EmpAge = 32 där EmpID = 2
uppdatera anställd set EmpAge = 38 där EmpID=6
uppdatera anställd set EmpAge = 38 där EmpID=3
|
Låt oss utföra följande Fråga för ett icke-unikt icke-grupperat index. I frågesyntaxen anger vi inte ett unikt nyckelord, och det berättar för SQL Server att skapa ett icke-unikt index:
|
1
|
skapa NONCLUSTERED INDEX Ncix_ Employee_empage på dbo.Anställd (EmpAge);
|
som vi vet bör nyckeln till ett index vara unikt. I det här fallet vill vi lägga till en icke-unik nyckel. Frågan uppstår: Hur kommer SQL Server att göra den här nyckeln så unik?
SQL Server gör följande saker för det:
- den lägger till den grupperade indexnyckeln i blad-och icke-bladsidorna i det icke-unika icke-grupperade indexet
- om den grupperade indexnyckeln också är icke-unik, lägger den till en 4-byte uniquifier så att indexnyckeln är unik
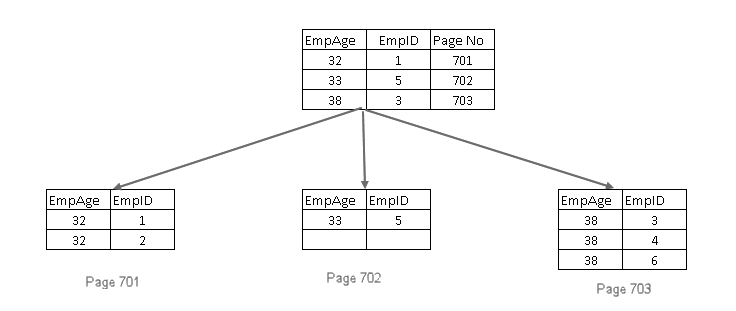
inkludera icke-nyckelkolumner i icke-grupperat index i SQL Server
Låt oss titta på följande faktiska exekveringsplan igen av följande fråga:
|
1
2
|
Välj * från anställd
där EmpContactNumber=’8474563217′
|
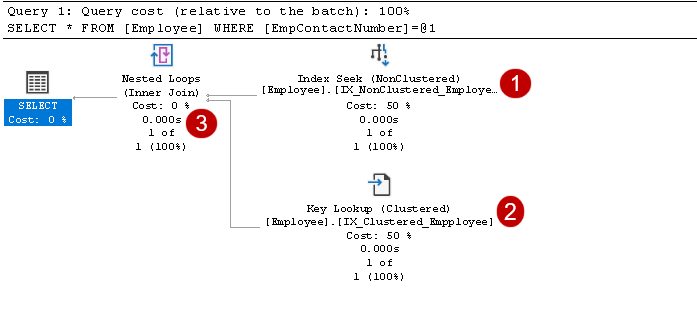
den innehåller index söka och nyckel lookup operatörer, som visas i bilden ovan:
- index söker: SQL Query Optimizer använder ett index söka på den icke-klustrade index och hämtar EmpID, EmpContactNumber kolumner
-
i det här steget, Query Optimizer använder nyckel lookup på klustrade index och hämtar värden för EmpName och EmpAge kolumner
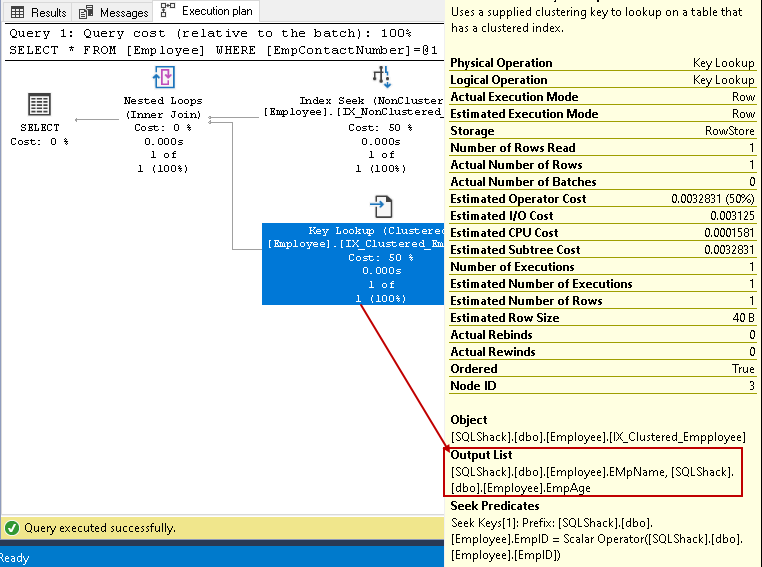
-
i det här steget använder Query Optimizer de kapslade looparna för varje rad som matas ut från det icke-grupperade indexet för matchning med den grupperade indexraden
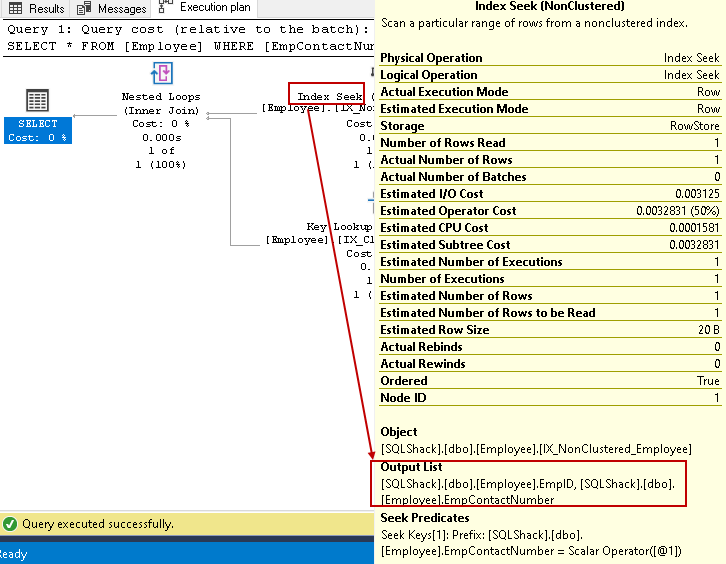
den kapslade slingan kan vara en kostsam operatör för stora bord. Vi kan minska kostnaden med hjälp av icke-klustrade index icke-nyckelkolumner. Vi anger kolumnen icke-nyckel i det icke-grupperade indexet med hjälp av indexklausulen.
Låt oss släppa och skapade det icke-grupperade indexet i SQL Server med de medföljande kolumnerna:
|
1
2
3
4
5
6
7
|
släpp INDEX på .
GÅ
SKAPA UNIKA NONCLUSTERED INDEX PÅ .
(
ASC
)
inkludera (EmpName, EmpAge)
|
inkluderade kolumner är en del av bladnoden i ett indexträd. Det hjälper till att hämta data från själva indexet istället för att gå vidare för datahämtning.
i följande bild får vi båda inkluderade kolumnerna EmpName och EmpAge som en del av bladnoden:
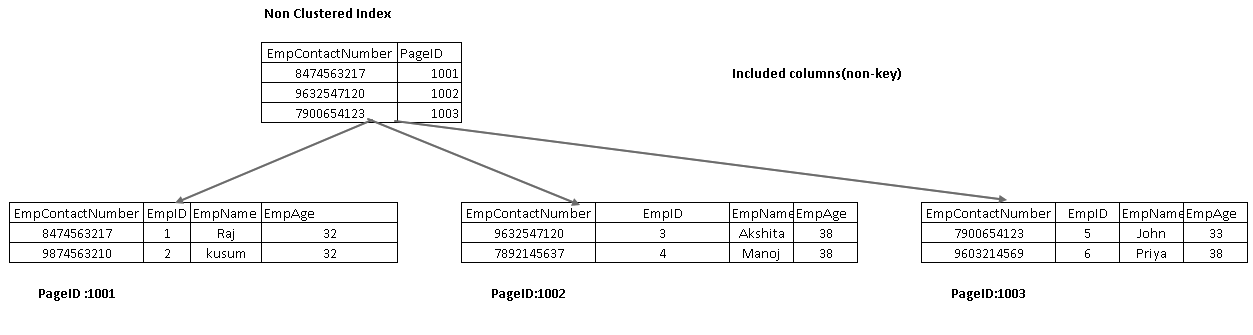
kör om SELECT-satsen och visa den faktiska exekveringsplanen nu. Vi har inte nyckeluppslag och kapslad slinga i denna exekveringsplan:

Låt oss sväva markören över indexsökningen och visa listan utgångskolumner. SQL Server kan hitta alla kolumner med hjälp av denna icke-klustrade index söka:
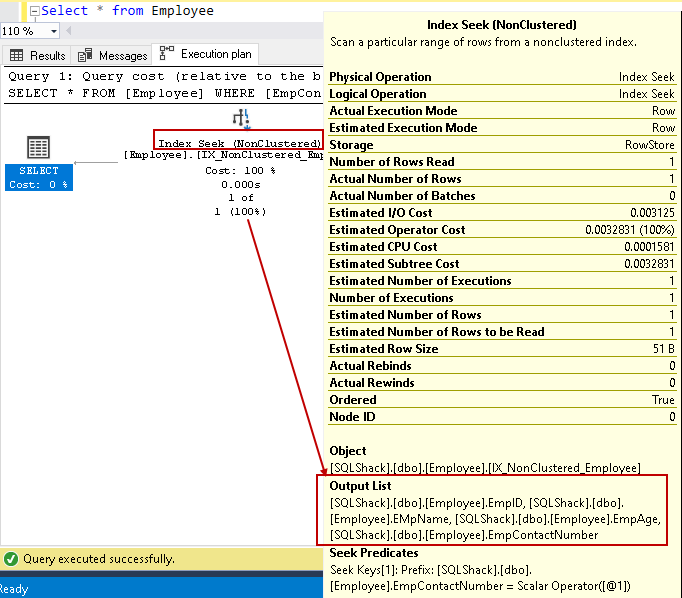
vi kan förbättra frågeprestanda med hjälp av täckningsindex med hjälp av inkluderade icke-nyckelkolumner. Det betyder dock inte att vi ska alla icke-nyckelkolumner i indexdefinitionen. Vi bör vara försiktiga i indexdesign och bör testa indexbeteendet före utplacering i produktionsmiljön.
slutsats
i den här artikeln undersökte vi det icke-grupperade indexet i SQL Server och dess användning i kombination med det grupperade indexet. Vi bör noggrant utforma indexet enligt arbetsbelastningen och frågebeteendet.
- författare
- Senaste inlägg

han är skaparen av en av de största gratis online-samlingarna av artiklar om ett enda ämne, med sin 50-delade serie på SQL Server alltid på Tillgänglighetsgrupper. Baserat på hans bidrag till SQL Server-communityn har han erkänts med olika utmärkelser inklusive den prestigefyllda ”årets bästa författare” kontinuerligt 2020 och 2021 på SQLShack.
Raj är alltid intresserad av nya utmaningar så om du behöver konsulthjälp om något ämne som omfattas av hans skrifter kan han nås på rajendra.Gupta 16 @ gmail.com
Visa alla inlägg av Rajendra Gupta
- använd ARM-mallar för att distribuera Azure container instances med SQL Server Linux – bilder – 21 December 2021
- Remote desktop access för AWS RDS SQL Server med Amazon RDS Custom-14 December 2021
- lagra SQL Server-filer i beständig lagring för Azure Container Instances-December 10, 2021