By: Ben Snaidero
přehled
v této části se budeme zabývat věci, které potřebujete vědět o non-clusteru indexy.
co je non-clustered index
non-clustered index (nebo pravidelný B-stromový index) je index, kde pořadí řádků neodpovídá fyzickému pořadí skutečných dat. Místo toho je uspořádán podle sloupců, které tvoří index. V non-clusteru index, Leaf stránky indexu neobsahují žádná skutečná data, ale místo toho obsahují ukazatele na skutečná data. Tyto ukazatele by ukazovaly na seskupenou datovou stránku indexu, kde existují skutečná data (nebo na stránku haldy, pokud v tabulce neexistuje žádný seskupený index).
proč vytvářet non-clustery indexy
hlavní výhodou mít non-clusteru index v tabulce je, že poskytuje fastaccess k datům. Index umožňuje databázovému stroji rychle vyhledat databez nutnosti prohledávat celou tabulku. Jak se tabulka zvětšuje, je velmi důležité, aby byly do tabulky přidány správné indexy, protože bez jakéhokoli dotazu se výkon dotazu dramaticky sníží.
kdy by měly být vytvořeny non-clustered indexy
existují dva případy, kdy mají non-clustered index v tabulce je výhodné. Za prvé, pokud existuje více než jedna sada sloupců, které se používají v dotazech WHERE clauseof, které přistupují k tabulce. Druhý index (za předpokladu, že ve sloupci primárního klíče již existuje seskupený index) urychlí dobu provádění a sníží počet dalších dotazů. Za druhé, pokud vaše dotazy často vyžadují datato být vrácena v určitém pořadí, s indexem na těchto sloupcích může snížit počet CPU a paměti potřebné jako další třídění nebude muset být donesce data v indexu je již objednáno.
následující příklad ukazuje, že pro načtení dat není vyžadováno žádné skenování tabulky, pouze hledání indexu non-clusteredindex a vyhledávání clusteru indexu pro získání dat. Také si to všimnětežádný druh není vyžadován, protože data jsou již ve správném pořadí.
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

jak vytvořit index bez klastrů
vytvoření indexu bez klastrů je v podstatě stejné jako vytvoření clusteru index, ale místo určení theCLUSTEREDclause specifikujeme. Můžeme také vynechat tuto klauzuli úplně jako non-clustered je výchozí při creatingan index.
níže uvedený TSQL ukazuje příklad každého příkazu.
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
co je krycí index
Acovering index je index, který se skládá ze všech (nebo více) sloupců potřebných k uspokojení dotazu jako klíčových sloupců indexu. Když krycí index lze použít k provedení dotazu, je zapotřebí méně operací IO, protože optimizerno již musí provádět další vyhledávání, aby získal skutečná data tabulky.
níže je uveden příklad TSQL, který můžete použít k vytvoření indexu acovering v tabulce produktů.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
následující dotaz TSQL lze nyní provést pouze přístupem k novému právě vytvořenému indexuwe, protože všechny sloupce v dotazu jsou součástí indexu.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
následující plán explain potvrzuje, že pro tento dotaz není vyžadováno žádné další vyhledávání.

co je index se zahrnutými sloupci
index vytvořený se zahrnutými sloupci je index bez klastrů, který také zahrnuje sloupce bez klíče v uzlech listů indexu, podobně jako seskupený index. Použití zahrnutých sloupců má několik výhod. Za prvé to vám dává možnost zahrnout typy sloupců, které nejsou povoleny jako indexové klíče v yourindex. Také, když jsou všechny sloupce v dotazu buď indexový klíč nebo zahrnutý sloupec, dotaz již nemusí provádět další vyhledávání, aby získal všechna data potřebná k uspokojení dotazu, což má za následek méně operací na disku. To je podobné jako výše uvedený krycí index.
pomocí stejného examplefrom výše následující TSQL vytvoří stejný index S výjimkou sloupce ProductNumber columnreferenced jako zahrnutý sloupec a nikoli sloupec indexového klíče.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
použití stejného dotazu jako výše by mělo být také možné provést bez nutnosti dalších vyhledávání.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
následující plán explain potvrzuje, že pro tento dotaz není vyžadováno žádné další vyhledávání.

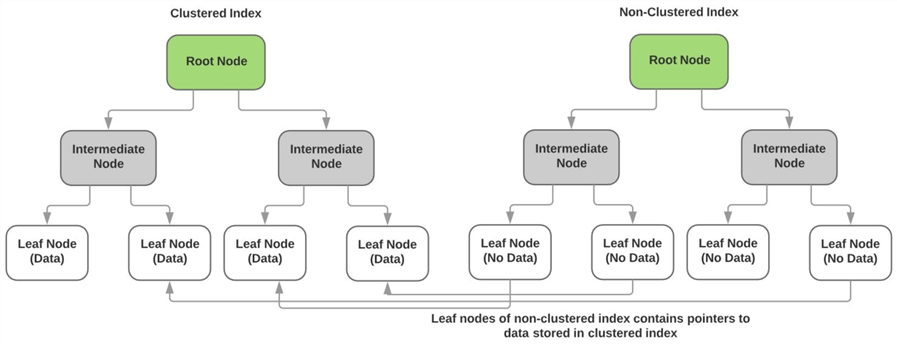
non-clustered indexesrelation to clustered index
jak je popsáno výše, clustered index ukládá skutečná data non-keycolumns v listových uzlech indexu. Uzly listů každého non-clusteredindexu neobsahují žádná data a místo toho mají ukazatele na skutečnou datovou stránku(nebo uzel listů) seskupeného indexu. Níže uvedený diagram to ilustruje. bod.
filtrované indexy
co je to?
Afiltrovaný index je speciální typ indexu, kde je indexována pouze určitá část řádků tabulky. Na základě kritérií filtru, která se používají při vytváření indexu, jsou indexovány pouze zbývající řádky, které mohou ušetřit místo, zlepšit výkon dotazu a snížit režii údržby, protože index je mnohem menší.
proč ji používat?
filtrované indexy jsou užitečné při vytváření indexů v tabulkách, kde existuje mnoho nulových hodnot v určitých sloupcích nebo některé sloupce mají velmi nízkou kardinalitua často se ptáte na nízkou hodnotu frekvence.
jak jej vytvořit?
Afiltrovaný index je vytvořen jednoduše přidáním klauzule WHERE do jakéhokoli příkazu pro vytvoření non-clusteredindex. Následující TSQL je příkladem syntaxe navytvořit filtrovaný index.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
potvrďte použití indexu
následující dotaz by měl použít náš nově vytvořený index, protože v tabulce s ShipDate NULL je velmi málo záznamů. Zde je TSQL.
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;