tento článek uvádí úvod do non-clusteru indexu v SQL Serveru pomocí příkladů.
Úvod
v předchozím článku Přehled clusterových indexů SQL Server jsme prozkoumali požadavek indexu a clusterových indexů v SQL Serveru.
než budeme pokračovat, pojďme mít rychlé shrnutí clusteru SQL Server index:
- fyzicky třídí data podle klíčového clusteru
- v tabulce můžeme mít pouze jeden seskupený index
- tabulka bez seskupeného indexu je halda a může to vést k problémům s výkonem
- SQL Server automaticky vytvoří seskupený index pro sloupec primárního klíče
- seskupený index je uložen ve formátu B-stromu a obsahuje datové stránky v uzlu listu, jak je uvedeno níže
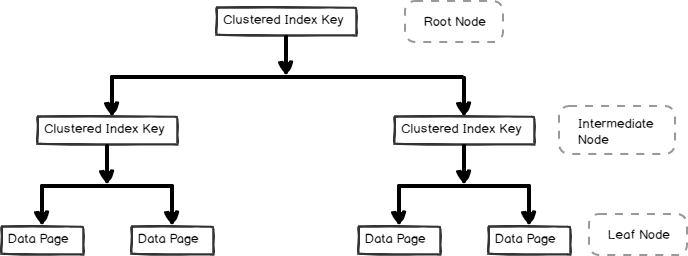
Non-Clustered indexy jsou také užitečné pro výkon dotazu a optimalizaci v závislosti na vytížení dotazu. V tomto článku, pojďme prozkoumat non-clustered index a jeho vnitřní.
přehled neklustrovaného indexu v SQL Serveru
v neklustrovaném indexu uzel listu neobsahuje skutečná data. Skládá se z ukazatele na skutečná data.
- pokud tabulka obsahuje seskupený index, uzel listu ukazuje na datovou stránku seskupeného indexu, která se skládá ze skutečných dat
- je-li tabulka haldou (bez seskupeného indexu), uzel listu ukazuje na stránku haldy
na obrázku níže se můžeme podívat na úroveň listu neklustrovaného indexu směřujícího k datové stránce v seskupeném indexu:
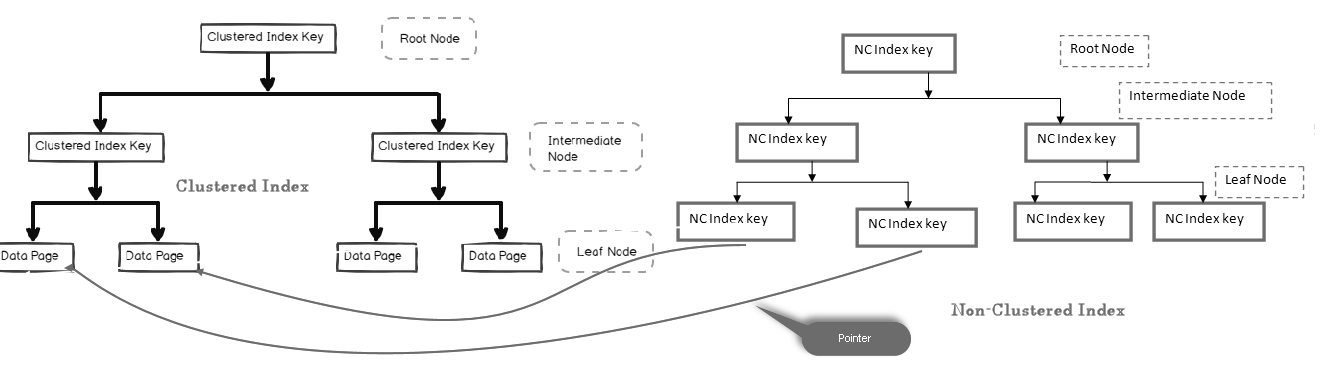
můžeme mít více non-clusteru indexy v tabulkách SQL, protože se jedná o logický index a není třídit data fyzicky ve srovnání s clusteru indexu.
Pojďme pochopit non-clustered index v SQL Serveru pomocí příkladu.
-
vytvořte tabulku zaměstnanců bez jakéhokoli indexu
123456vytvořit tabulku dbo.Zaměstnanec(EmpID INT,EMpName VARCHAR(50),EmpAge INT,EmpContactNumber VARCHAR(10)); -
vložte do něj několik záznamů
123vložit do zaměstnaneckých hodnot (1, „Raj‘,32,8474563217)vložit do zaměstnaneckých hodnot (2, „kusum‘,30,9874563210)vložit do zaměstnaneckých hodnot (3, ‚Akshita‘,28,9632547120) -
vyhledejte EmpID 2 a vyhledejte jeho skutečný plán provedení
1Vyberte * od zaměstnance, kde EmpID=2provádí skenování tabulky, protože v této tabulce nemáme žádný index:
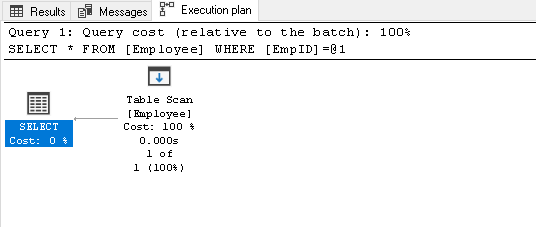
-
vytvořte jedinečný seskupený index ve sloupci EmpID
1vytvořit unikátní clusteru INDEX IX_Clustered_Empployee na DBO.Zaměstnanec (EmpID); -
vyhledejte EmpID 2 a vyhledejte jeho skutečný plán provedení
v tomto plánu provádění, můžeme si všimnout, že skenování tabulky se změní na hledání seskupeného indexu:
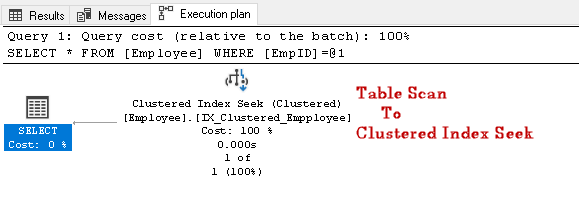
pojďme provést další dotaz SQL pro vyhledávání zaměstnance s konkrétním kontaktním číslem:
|
1
|
Vyberte * od zaměstnance, kde EmpContactNumber=’9874563210′
|
ve sloupci EmpContactNumber nemáme index, proto optimalizátor dotazů používá seskupený index, ale skenuje celý index pro načtení záznamu:
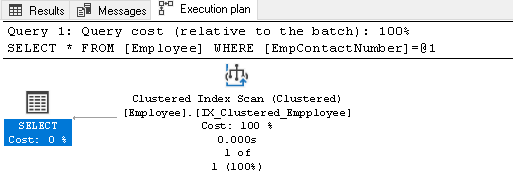
klepněte pravým tlačítkem myši na plán provádění a vyberte Zobrazit plán provádění XML:
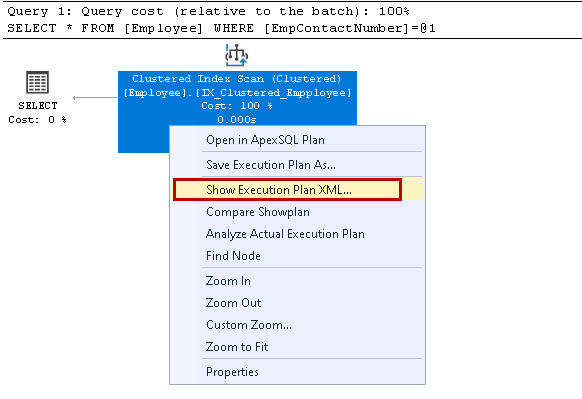
otevře plán provádění XML v novém okně dotazu. Zde si všimneme, že používá clustered index key a čte jednotlivé řádky pro načtení výsledku:

vložíme několik dalších záznamů do tabulky zaměstnanců pomocí následujícího skriptu:
|
1
2
3
|
vložit do zaměstnaneckých hodnot (4, ‚Manoj‘,38,7892145637)
vložit do zaměstnaneckých hodnot (5, „John‘,33,7900654123)
vložit do zaměstnaneckých hodnot (6, „Priya‘,18,9603214569)
|
v této tabulce máme záznamy šesti zaměstnanců. Nyní znovu spusťte příkaz select pro načtení záznamů zaměstnanců s konkrétním kontaktním číslem:
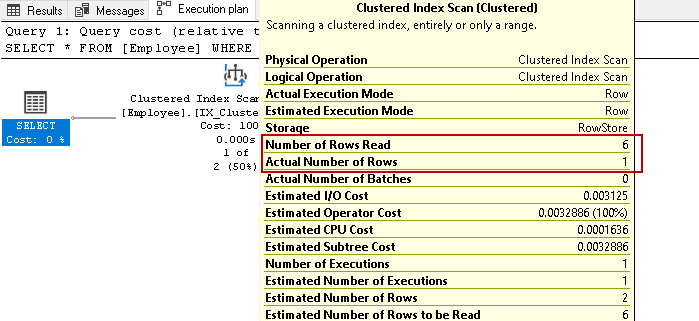
znovu prohledá všech šest řádků pro výsledek na základě zadané podmínky. Představte si, že máme v tabulce miliony záznamů. Pokud SQL Server musí číst všechny řádky indexových klíčů, byl by to úkol náročný na zdroje a čas.
můžeme reprezentovat seskupený index (nikoli skutečnou reprezentaci) ve formátu B-stromu podle následujícího obrázku:

v předchozím dotazu SQL Server přečte stránku kořenového uzlu a načte každou stránku uzlu listu a řádek pro vyhledávání dat.
nyní vytvoříme jedinečný neklustrovaný index v SQL Serveru v tabulce zaměstnanců ve sloupci EmpContactNumber jako klíč indexu:
|
1
|
vytvořit jedinečný NONCLUSTERED INDEX IX_NonClustered_Employee na DBO.Zaměstnanec (EmpContactNumber);
|
než vysvětlíme tento index, znovu spusťte příkaz SELECT a zobrazte skutečný plán provádění:
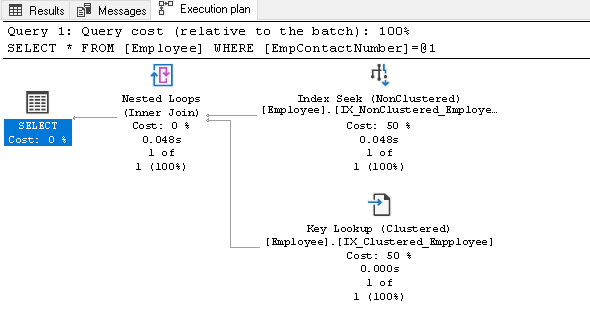
v tomto plánu provádění vidíme dvě složky:
- hledání indexu (bez zahrnutí)
- vyhledávání klíčů (seskupené)
abychom porozuměli těmto komponentám, musíme se podívat na neklustrovaný index v návrhu serveru SQL. Zde můžete vidět, že uzel leaf obsahuje klíč indexu bez klastrů (EmpContactNumber) a klíč clusteru index (EmpID):
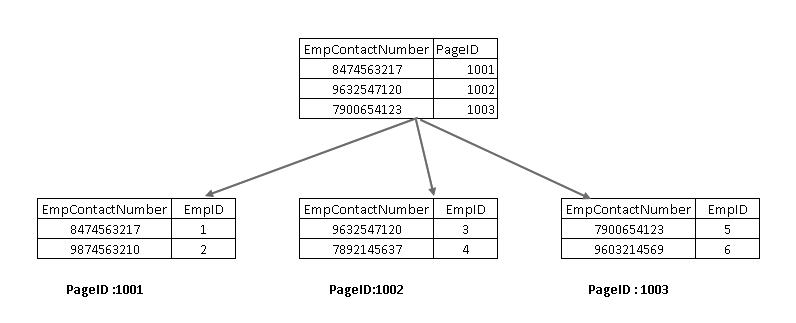
Nyní, pokud znovu spustit příkaz SELECT, prochází pomocí non-clusteru index klíč a ukazuje na stránku s clusteru index klíč:
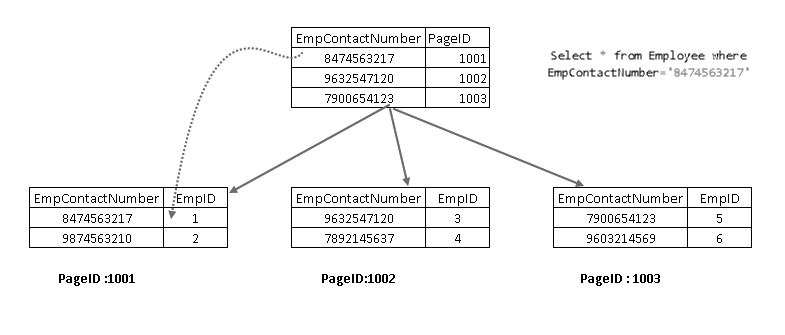
ukazuje, že načte záznam kombinací clusteru index key a non-clusteru index key. Můžete vidět úplnou logiku pro příkaz SELECT, jak je uvedeno níže:
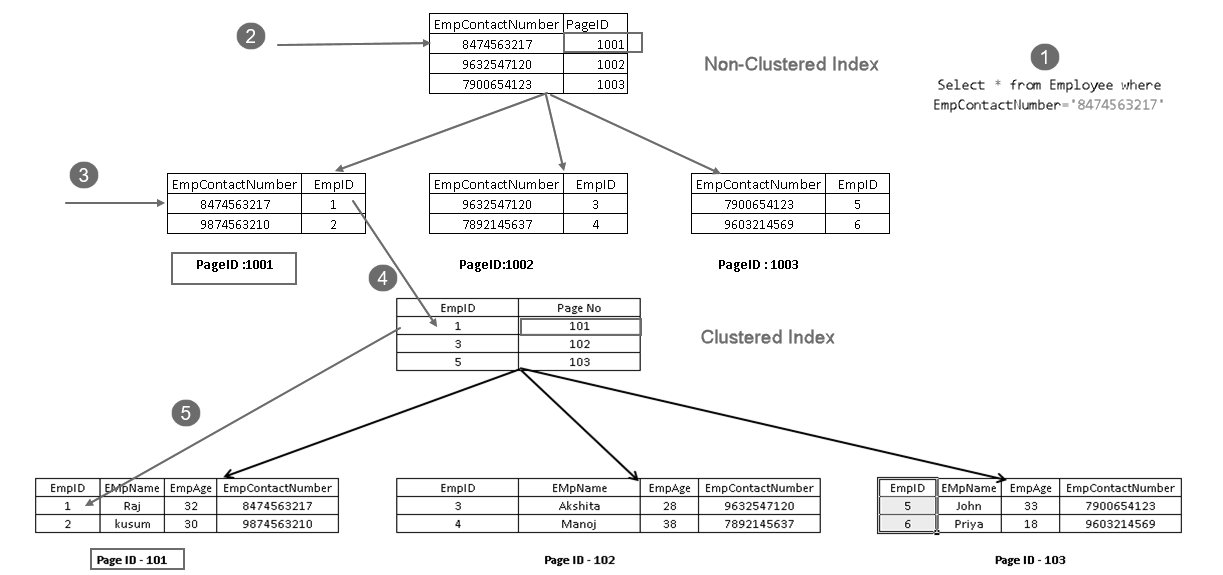
- uživatel provede příkaz select, aby našel záznamy zaměstnanců odpovídající zadanému kontaktnímu číslu
- optimalizátor dotazů používá neklustrovaný indexový klíč a zjistí číslo stránky 1001
- Tato stránka se skládá z clusterového indexového klíče. EmpID 1 můžete vidět na obrázku výše
- SQL Server zjistí stránku č. 101, která se skládá ze záznamů EmpID 1 pomocí klíčového indexu clusteru
- přečte odpovídající řádek a vrátí výstup uživateli
dříve jsme viděli, že čte šest řádků pro načtení odpovídajícího řádku a vrátí jeden řádek ve výstupu. Podívejme se na plán provádění pomocí indexu bez klastrů:

Non-unikátní non-clusteru index v SQL Serveru
můžeme mít více non-clusteru indexy v SQL tabulce. Dříve jsme ve sloupci EmpContactNumber vytvořili jedinečný non-clustered index.
před vytvořením indexu proveďte následující dotaz, abychom ve sloupci EmpAge měli duplicitní hodnotu:
|
1
2
3
|
Update Employee set EmpAge=32 where EmpID=2
Update Empage set EmpAge=38 where EmpID=6
Update Empage set = 38 where EmpID=3
|
provedeme následující dotaz pro nejedinečný index bez klastrů. V syntaxi dotazu neurčujeme jedinečné Klíčové slovo a říká serveru SQL Server, aby vytvořil nejedinečný index:
|
1
|
vytvořit NONCLUSTERED INDEX NCIX_Employee_EmpAge na DBO.Zaměstnanec (EmpAge);
|
jak víme, klíč indexu by měl být jedinečný. V tomto případě chceme přidat jedinečný klíč. Vyvstává otázka: jak SQL Server učiní tento klíč jedinečným?
SQL Server dělá následující věci pro něj:
- přidá klíč clusterového indexu do listových a nelistových stránek nejedinečného non-clusterového indexu
- pokud je clusterový indexový klíč také jedinečný, přidá 4-byte uniquifier, takže indexový klíč je jedinečný
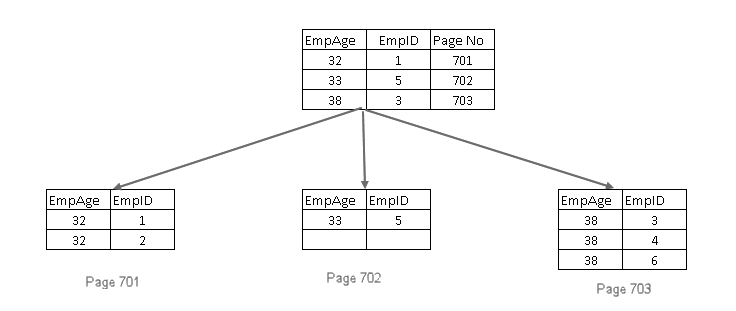
zahrnout non-key sloupce v non-clustered indexu v SQL Serveru
podívejme se na následující skutečný plán provádění znovu následujícího dotazu:
|
1
2
|
Vyberte * od zaměstnance
kde EmpContactNumber=’8474563217′
|
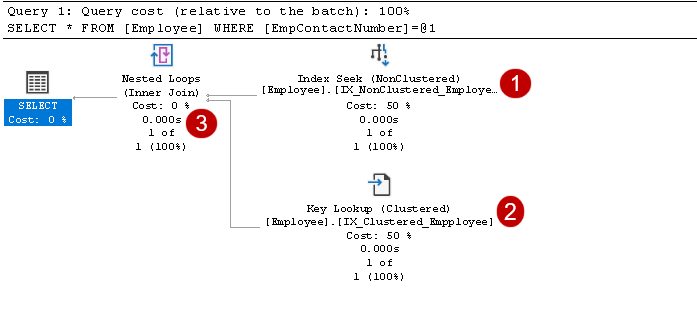
to zahrnuje index Hledat a klíčové vyhledávací operátory, jak je znázorněno na obrázku výše:
- index hledá: SQL Query Optimizer používá index seek na non-clusteru indexu a načte EmpID, EmpContactNumber sloupce
-
v tomto kroku, Query Optimizer používá klíčové vyhledávání na clusteru indexu a načte hodnoty pro EmpName a EmpAge sloupců
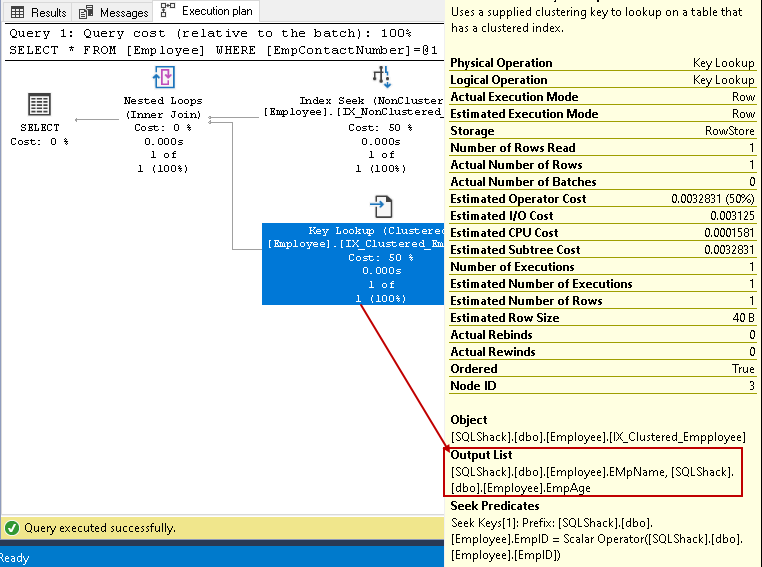
-
v tomto kroku Query Optimizer používá vnořené smyčky pro každý řádek výstup z non-clusteru indexu pro shodu s clusteru indexu řádku
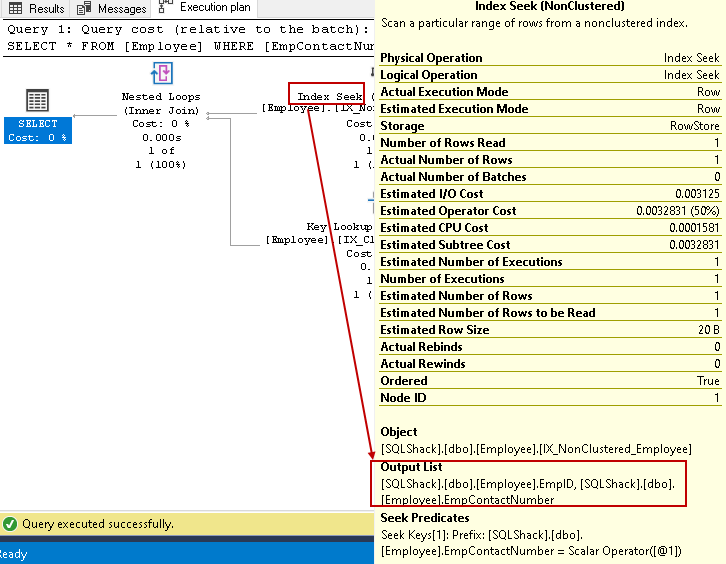
vnořená smyčka může být nákladným operátorem pro velké tabulky. Můžeme snížit náklady pomocí non-clusteru index non-klíčové sloupce. Pomocí klauzule index určíme sloupec bez klíče v non-clusteru indexu.
zahodíme a vytvoříme non-clustered index v SQL Serveru pomocí přiložených sloupců:
|
1
2
3
4
5
6
7
|
DROP INDEX na .
JÍT
VYTVOŘIT JEDINEČNÝ NONCLUSTERED INDEX NA .
(
ASC
)
zahrnout (EmpName, EmpAge)
|
zahrnuté sloupce jsou součástí uzlu listů v indexovém stromu. Pomáhá načíst data ze samotného indexu namísto dalšího procházení pro načítání dat.
na následujícím obrázku získáme oba zahrnuté sloupce EmpName a EmpAge jako součást uzlu listu:
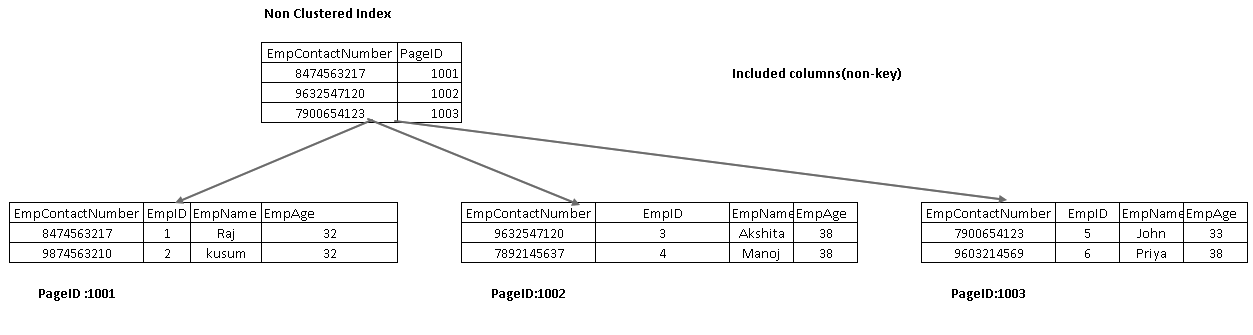
znovu spusťte příkaz SELECT a nyní zobrazte skutečný plán provedení. V tomto plánu provádění nemáme vyhledávání klíčů a vnořenou smyčku:

najeďte kurzorem na vyhledávání indexu a zobrazte seznam výstupních sloupců. SQL Server může najít všechny sloupce pomocí tohoto vyhledávání indexů bez klastrů:
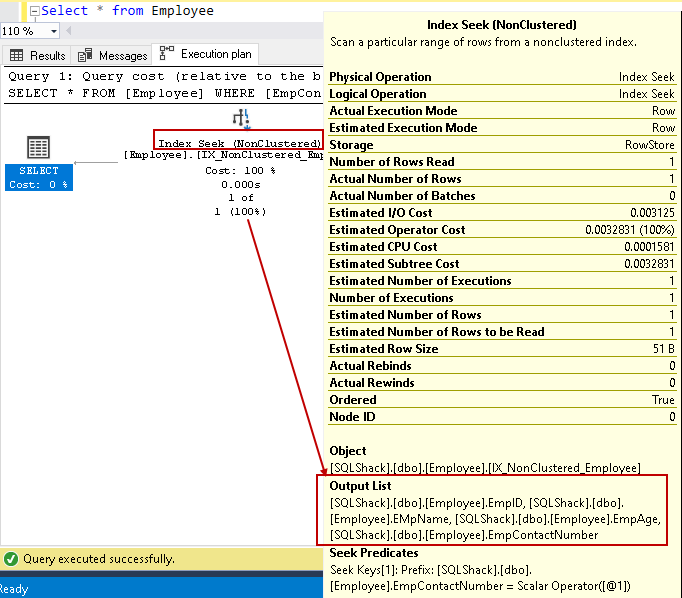
můžeme zlepšit výkon dotazu pomocí krycího indexu pomocí zahrnutých bezklíčových sloupců. Nicméně, to neznamená, že bychom měli všechny non-klíčové sloupce v definici indexu. Měli bychom být opatrní při návrhu indexu a měli bychom testovat chování indexu před nasazením ve výrobním prostředí.
závěr
v tomto článku jsme zkoumali non-clustered index v SQL Serveru a jeho použití v kombinaci s clustered indexem. Měli bychom pečlivě navrhnout index podle pracovního zatížení a chování dotazu.
- Autor
- poslední příspěvky

je tvůrcem jedné z největších bezplatných online sbírek článků na jedno téma, se svou 50dílnou sérií na serveru SQL Server vždy ve skupinách dostupnosti. Na základě svého příspěvku do komunity SQL Server byl v letech 2020 a 2021 na SQLShack oceněn různými oceněními včetně prestižního „nejlepšího autora roku“.
Raj se vždy zajímá o nové výzvy, takže pokud potřebujete poradit s jakýmkoli tématem obsaženým v jeho spisech,může být dosažen v [email protected]
Zobrazit všechny příspěvky od Rajendra Gupta
- použijte šablony ARM k nasazení instancí Azure container s obrázky SQL Server Linux-21. prosince 2021
- vzdálený přístup na plochu pro AWS RDS SQL Server s Amazon RDS Custom-14. prosince 2021
- uložte soubory SQL Serveru do trvalého úložiště pro instance Azure Container-prosinec 10, 2021