af: Ben Snaidero
oversigt
i dette afsnit dækker vi ting, du har brug for at vide om ikke-grupperede indekser.
hvad er et ikke-grupperet indeks
et ikke-grupperet indeks (eller almindeligt B-træindeks) er et indeks, hvor rækkefølgen af rækkerne ikke svarer til den fysiske rækkefølge af de faktiske data. Det er insteadordered af de kolonner, der udgør indekset. I et ikke-grupperet indeks indeholder Indeksens bladsider ingen faktiske data, men indeholder i stedet punkter til de faktiske data. Disse henvisninger peger på den grupperede indeksdataside, hvor de faktiske data findes (eller heap-siden, hvis der ikke findes et grupperet indeks på tabellen).
hvorfor oprette ikke-grupperede indekser
den største fordel ved at have et ikke-grupperet indeks på et bord er, at det giver hurtig adgang til data. Indekset giver databasemotoren mulighed for hurtigt at lokalisere datauden at skulle scanne gennem hele tabellen. Når en tabel bliver større, er det meget vigtigt, at de korrekte indekser føjes til tabellen, da uden nogenindekser vil forespørgselsydelsen falde dramatisk.
Hvornår skal der oprettes ikke-grupperede indekser
der er to tilfælde, hvor det er fordelagtigt at have et ikke-grupperet indeks på et bord. Først når der er mere end et sæt kolonner, der bruges i hvor clauseof forespørgsler, der får adgang til tabellen. Et andet indeks (forudsat at der allerede eret grupperet indeks på den primære nøglekolonne) vil fremskynde udførelsestiderne og reducere for de andre forespørgsler. For det andet, hvis dine forespørgsler ofte kræver dataat blive returneret i en bestemt rækkefølge, kan et indeks på disse kolonner reducere mængden af CPU og hukommelse, der kræves, da yderligere sortering ikke behøver at blive gjort, da dataene i indekset allerede er bestilt.
følgende eksempel viser, at der ikke kræves nogen tabelscanning for at hente dataene, bare et indekssøgning af det ikke-klyngedeindeks og et opslag af det klyngede indeks for at hente dataene. Bemærk også detingen sortering er påkrævet, da dataene allerede er i den rigtige rækkefølge.
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

Sådan oprettes et ikke-grupperet indeks
oprettelse af et ikke-grupperet indeks er stort set det samme som at oprette grupperet indeks,men i stedet for at specificereclusteredclause vi specificereclustered. Vi kan også udelade denne klausul helt, da en ikke-grupperet er standard, når du opretter et indeks.
nedenstående TSKL viser et eksempel på hver erklæring.
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
hvad er et dækningsindeks
et Dækningsindeks er et indeks, der består af alle (eller flere) af kolonnerne, der kræves for at tilfredsstille en forespørgsel som nøglekolonner i indekset. Når et dækningsindeks kan bruges til at udføre en forespørgsel, kræves færre IO-operationer, da optimeringen ikke længere skal udføre ekstra opslag for at hente de faktiske tabeldata.
nedenfor er et eksempel på det TSKL, du kan bruge til at oprette et dækningsindeks på Produkttabellen.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
følgende tskl-forespørgsel kan nu udføres ved kun at få adgang til det nye indeks, vi lige har oprettet, da alle kolonner i forespørgslen er en del af indekset.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
den følgende forklaringsplan bekræfter, at der ikke kræves nogen ekstra opslag til denne forespørgsel.

Hvad er et indeks med inkluderede kolonner
et indeks oprettet med inkluderede kolonner er et ikke-grupperet indeks, der også inkludererikke-nøglekolonner i bladknudepunkterne i indekset, svarende til et grupperet indeks. Der er et par fordele ved at bruge inkluderede kolonner. Først giver det dig mulighed for at inkludere kolonnetyper, der ikke er tilladt som indeksnøgler i dinindeks. Når alle kolonnerne i din forespørgsel enten er en indeksnøgle eller en inkluderet kolonne, behøver forespørgslen ikke længere at foretage et ekstra opslag for at få alle de data, der er nødvendige for at tilfredsstille forespørgslen, hvilket resulterer i færre diskoperationer. Dette svarer til det tidligere nævnte dækningsindeks.
brug af det samme eksempelfra ovenstående vil følgende tskl oprette det samme indeks undtagen med kolonnen produktnummer, der henvises til som en inkluderet kolonne og ikke en indeksnøglekolonne.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
brug af den samme forespørgsel som ovenfor bør dette også være i stand til at udføre uden at kræve yderligere opslag.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
den følgende forklaringsplan bekræfter, at der heller ikke kræves nogen ekstra opslag til denne forespørgsel.

ikke-grupperede indekserforhold til grupperet indeks
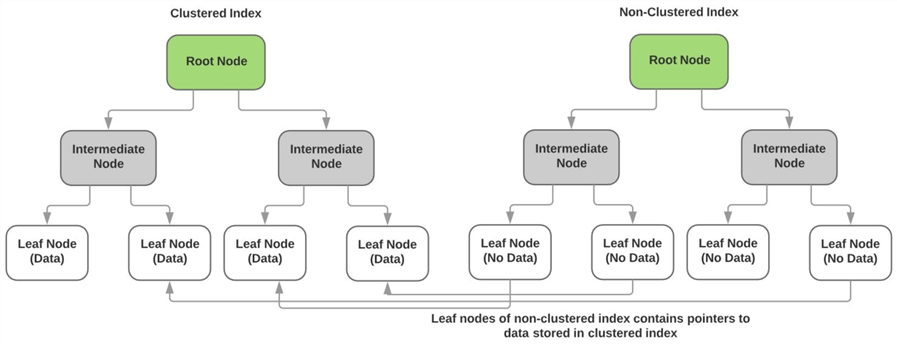
som beskrevet ovenfor gemmer det grupperede indeks de faktiske data for de ikke-nøglekolonner i bladnoderne i indekset. Bladknudepunkterne for hver ikke-grupperetindeks indeholder ingen data og har i stedet henvisninger til den faktiske dataside(eller bladknudepunkt) i det grupperede indeks. Diagrammet nedenfor illustrerer dettepunkt.
filtrerede indekser
Hvad er det?
Etfiltreret indeks er en særlig indekstype, hvor kun en vis del af rækkerne i tabellen er indekseret. Baseret på de filterkriterier,der anvendes, når indekset oprettes, indekseres kun de resterende rækker, som kan spare plads, forbedre forespørgselsydelsen og reducere vedligeholdelsesomkostninger, da indekset er meget mindre.
Hvorfor bruge det?
filtrerede indekser er nyttige, når du opretter indekser på tabeller, hvor der er mange nulværdier i bestemte kolonner, eller visse kolonner har en meget lav kardinalitet, og du spørger ofte om en lavfrekvensværdi.
hvordan oprettes det?
Affiltreret indeks oprettes simpelthen ved at tilføje en hvor-klausul til enhver ikke-grupperetindeksoprettelseserklæring. Det følgende er et eksempel på syntaksen forOpret et filtreret indeks.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
Bekræft Indeksbrug
følgende forespørgsel skal bruge vores nyoprettede indeks, da der er meget få optegnelser i tabellen med ShipDate NULL. Her er TKL.
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;