denne artikel giver en introduktion af det ikke-grupperede indeks i en server ved hjælp af eksempler.
introduktion
i en tidligere artikeloversigt over et indeks og grupperede indekser i en server.
før vi går videre, lad os få en hurtig oversigt over:
- det sorterer fysisk data i henhold til den grupperede indeksnøgle
- vi kan kun have et grupperet indeks pr. tabel
- en tabel uden et grupperet indeks er en bunke, og det kan føre til ydelsesproblemer
- i B-Tree format og indeholder data sider i bladet node, som vist nedenfor
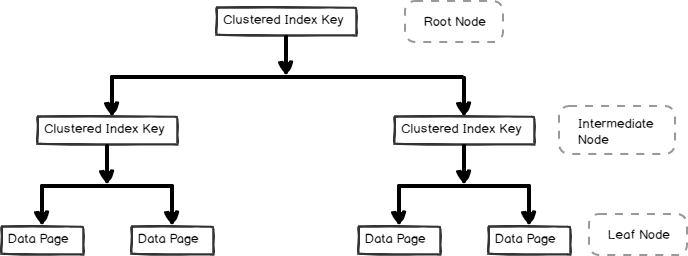
ikke-grupperet indeks er også nyttige til forespørgsel ydeevne og optimering afhængigt af forespørgslen arbejdsbyrde. I denne artikel, lad os undersøge det ikke-grupperede indeks og dets interne.
oversigt over det ikke-grupperede indeks i server
i et ikke-grupperet indeks indeholder bladnoden ikke de faktiske data. Den består af en peger til de faktiske data.
- hvis tabellen indeholder et grupperet indeks, peger bladknudepunktet på den grupperede indeksdataside, der består af faktiske data
- hvis tabellen er en bunke (uden et grupperet indeks), peger bladknudepunktet på bunkesiden
i nedenstående billede kan vi se på bladniveauet for ikke-grupperet indeks, der peger mod datasiden i det grupperede indeks:
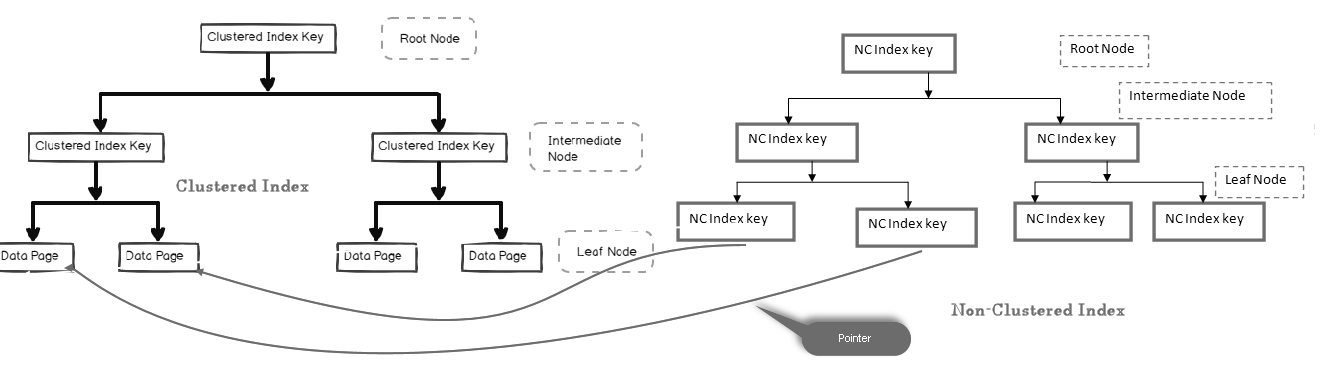
vi kan have flere ikke-grupperede indekser i KVL-tabeller, fordi det er et logisk indeks og ikke sorterer data fysisk sammenlignet med det klyngede indeks.
lad os forstå det ikke-grupperede indeks i en server ved hjælp af et eksempel.
-
Opret en Medarbejdertabel uden noget indeks på det
123456Opret tabel dbo.Medarbejder(EmpID INT,EMpName VARCHAR(50),EmpAge INT,Empcontactnummer VARCHAR(10)); -
Indsæt få poster i den
123Indsæt i medarbejderværdier (1, ‘Raj’,32,8474563217)Indsæt i medarbejderværdier (2, ‘kusum’,30,9874563210)Indsæt i medarbejderværdier (3, ‘Akshita’,28,9632547120) -
Søg efter EmpID 2 og se efter den faktiske eksekveringsplan for den
1vælg * fra medarbejder hvor EmpID=2det gør en tabel scanning, fordi vi ikke har nogen indeks på denne tabel:
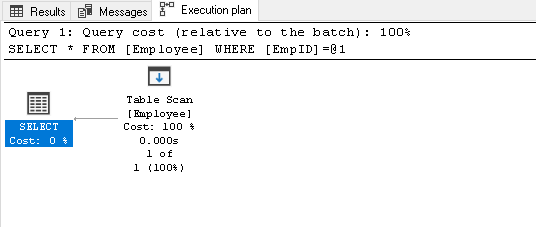
-
Opret et unikt grupperet indeks i EmpID-kolonnen
1Opret unikke grupperet indeks Iks_clustered_empployee på dbo.Medarbejder (EmpID); -
Søg efter EmpID 2 og se efter den faktiske eksekveringsplan for den
i denne udførelsesplan kan vi bemærke, at tabelscanningen ændres til en grupperet indekssøgning:
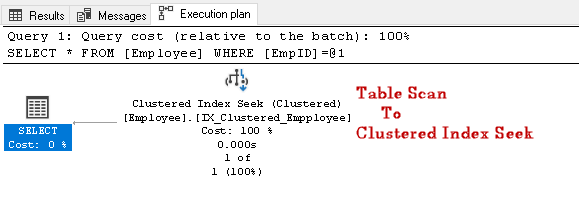
lad os udføre en anden KVL-forespørgsel for at søge medarbejder med et bestemt kontaktnummer:
|
1
|
vælg * fra medarbejder hvor EmpContactNumber=’9874563210′
|
vi har ikke et indeks i kolonnen EmpContactNumber, derfor bruger Forespørgselsoptimering det grupperede indeks, men det scanner hele indekset for at hente posten:
Højreklik på eksekveringsplanen, og vælg Vis eksekveringsplan:
den åbner eksekveringsplanen i det nye forespørgselsvindue. Her bemærker vi, at den bruger den klyngede indeksnøgle og læser de enkelte rækker for at hente resultatet:

|
1
2
3
|
Indsæt i medarbejderværdier (4, ‘Manoj’,38,7892145637)
Indsæt i medarbejderværdier (5, ‘John’,33,7900654123)
Indsæt i medarbejderværdier (6, ‘Priya’,18,9603214569)
|
vi har seks medarbejderes optegnelser i denne tabel. Udfør nu select-sætningen igen for at hente medarbejderposter med et specifikt kontaktnummer:
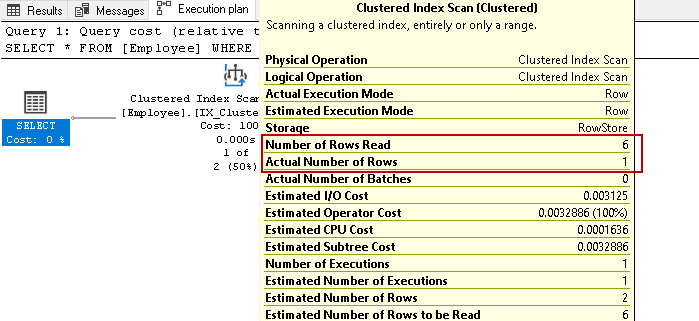
det scanner igen alle seks rækker for resultatet baseret på den angivne tilstand. Forestil dig, at vi har millioner af poster i tabellen. Hvis en server skal læse alle indeksnøglerækker, ville det være en ressource-og tidskrævende opgave.
vi kan repræsentere grupperet indeks (ikke faktisk repræsentation) i B-træformatet i henhold til følgende billede:

i den forrige forespørgsel læser vi rodknudesiden og henter hver bladknudeside og række til dataindhentning.
lad os nu oprette et unikt indeks, der ikke er grupperet, på Medarbejdertabellen i EmpContactNumber-kolonnen som indeksnøgle:
|
1
|
Opret unikke ikke-clustered indeks Ip_nonclustered_employee på dbo.Medarbejder (EmpContactNumber);
|
før vi forklarer dette indeks, skal du køre SELECT-sætningen igen og se den faktiske eksekveringsplan:
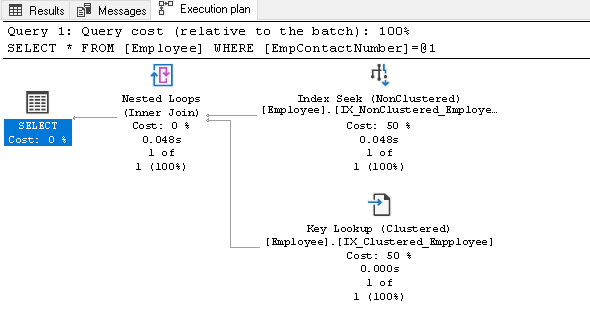
i denne eksekveringsplan kan vi se to komponenter:
- Indekssøgning (ikke-lukket)
- Nøgleopslag (grupperet)
for at forstå disse komponenter skal vi se på et ikke-grupperet indeks i server design. Her kan du se, at bladknuden indeholder den ikke-klyngede indeksnøgle (EmpContactNumber) og klyngede indeksnøgle (EmpID):
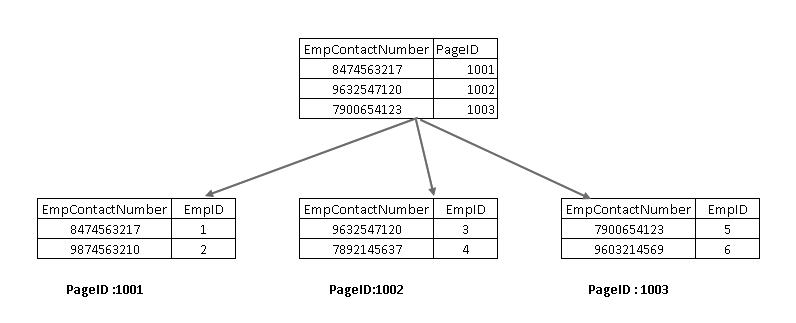
nu, hvis du kører SELECT-sætningen igen, krydser den ved hjælp af den ikke-grupperede indeksnøgle og peger på en side med grupperet indeksnøgle:
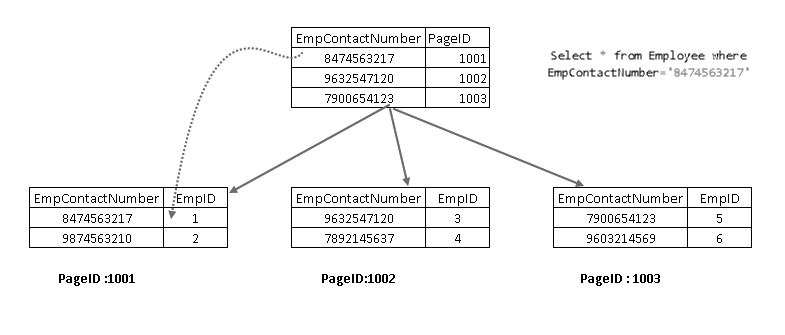
det viser, at det henter posten med en kombination af grupperet indeksnøgle og ikke-grupperet indeksnøgle. Du kan se komplet logik for SELECT-sætningen som vist nedenfor:
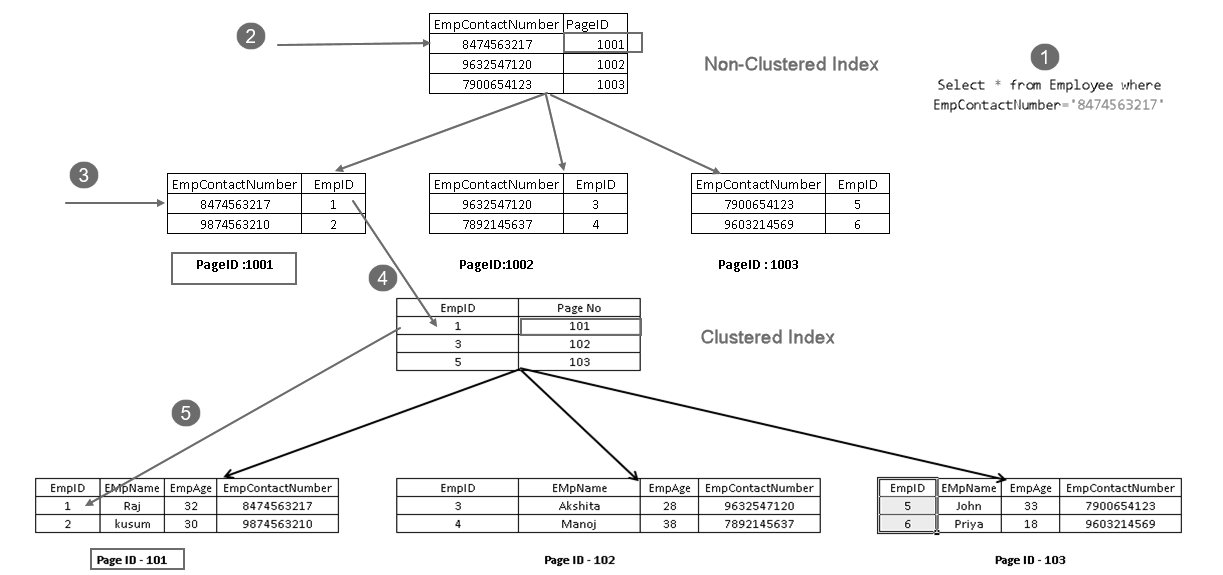
- en bruger udfører en select-sætning for at finde medarbejderposter, der matcher et angivet kontaktnummer
- Forespørgselsoptimering bruger en ikke-grupperet indeksnøgle og finder ud af sidetallet 1001
- denne side består af en grupperet indeksnøgle. 101, der består af EmpID 1-poster ved hjælp af den grupperede indeksnøgle
- den læser den matchende række og returnerer output til brugeren
tidligere så vi, at den læser seks rækker for at hente den matchende række og returnerer en række i output. Lad os se på en eksekveringsplan ved hjælp af det ikke-grupperede indeks:

ikke-unikt ikke-grupperet indeks i KVL-Server
vi kan have flere ikke-grupperede indekser i en KVL-tabel. Tidligere oprettede vi et unikt ikke-grupperet indeks i kolonnen EmpContactNumber.
før du opretter indekset, skal du udføre følgende forespørgsel, så vi har duplikatværdi i EmpAge-kolonnen:
|
1
2
3
|
Opdater Medarbejdersæt EmpAge=32 hvor EmpID=2
Opdater Medarbejdersæt EmpAge=38 hvor EmpID=6
Opdater Medarbejdersæt EmpAge=38 hvor EmpID=3
|
lad os udføre følgende forespørgsel for et ikke-unikt ikke-grupperet indeks. I forespørgselssyntaksen angiver vi ikke et unikt søgeord, og det fortæller os, at vi skal oprette et ikke-unikt indeks:
|
1
|
Opret NONCLUSTERED indeks Ncis_ Employee_empage på dbo.Medarbejder (EmpAge);
|
som vi ved, skal nøglen til et indeks være unik. I dette tilfælde vil vi tilføje en ikke-unik nøgle. Spørgsmålet opstår: Hvordan vil
server gør følgende ting for det:
- den tilføjer den grupperede indeksnøgle på blad-og ikke-bladsiderne i det ikke-unikke ikke-grupperede indeks
- hvis den grupperede indeksnøgle også er ikke-unik, tilføjer den en 4-byte unik, så indeksnøglen er unik
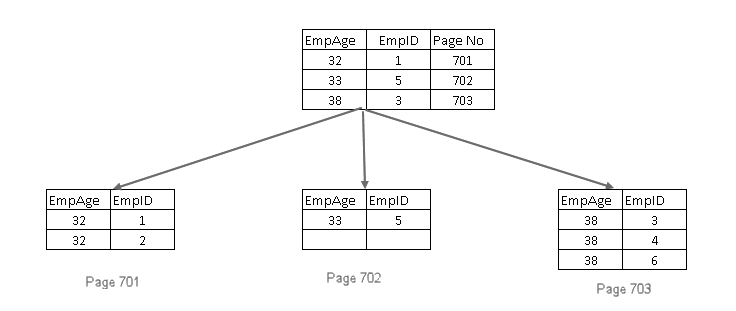
Inkluder ikke-nøglekolonner I ikke-grupperet indeks i KVL-Server
lad os se på følgende faktiske eksekveringsplan igen af følgende forespørgsel:
|
1
2
|
vælg * fra medarbejder
hvor Empcontactnummer=’8474563217′
|
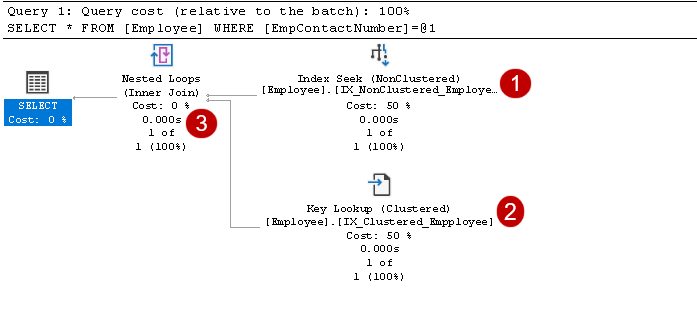
det inkluderer indekssøgnings-og nøgleopslagsoperatører, som vist i ovenstående billede:
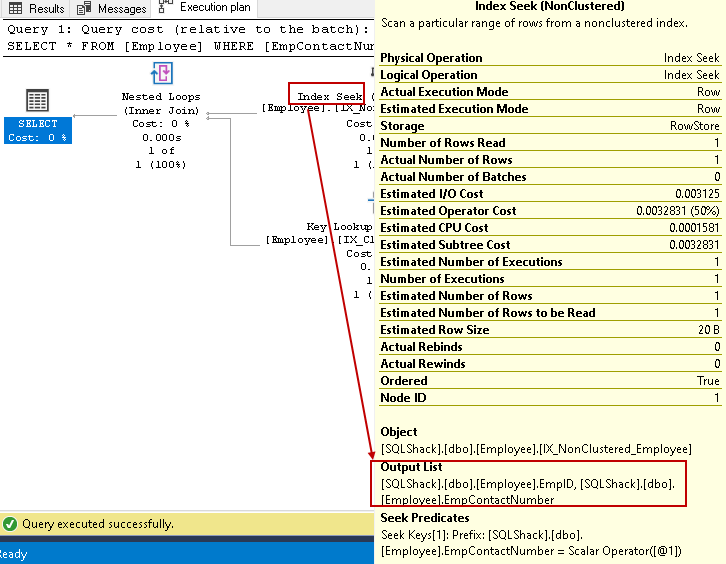
- indekset søger: Bruger en indekssøgning på det ikke-grupperede indeks og henter EmpID, empcontactnumber kolonner
-
i dette trin bruger Forespørgselsoptimering nøgleopslag på det grupperede indeks og henter værdier for empname og EmpAge kolonner
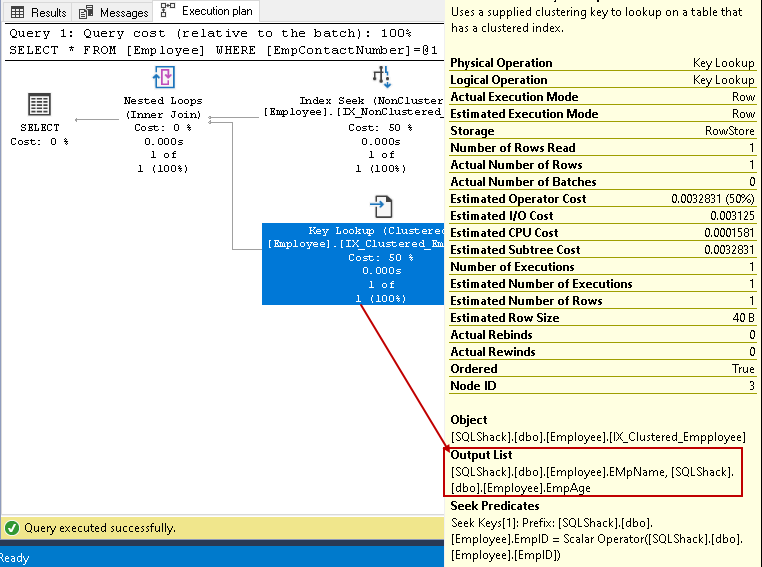
-
i dette trin bruger Forespørgselsoptimering de indlejrede sløjfer for hver rækkeudgang fra det ikke-grupperede indeks til at matche med den grupperede indeksrække
den indlejrede sløjfe kan være en dyr operatør til store borde. Vi kan reducere omkostningerne ved hjælp af de ikke-grupperede indeks ikke-nøglekolonner. Vi angiver kolonnen ikke-nøgle i det ikke-grupperede indeks ved hjælp af indeksklausulen.
lad os slippe og oprette det ikke-klyngede indeks i serveren ved hjælp af de inkluderede kolonner:
|
1
2
3
4
5
6
7
|
DROP indeks på .
GÅ
OPRET UNIKT IKKE-LUKKET INDEKS PÅ .
(
ASC
)
Inkluder(EmpName, EmpAge)
|
inkluderede kolonner er en del af bladknuden i et indekstræ. Det hjælper med at hente dataene fra selve indekset i stedet for at krydse videre til dataindhentning.
i det følgende billede får vi begge inkluderede kolonner EmpName og EmpAge som en del af bladnoden:
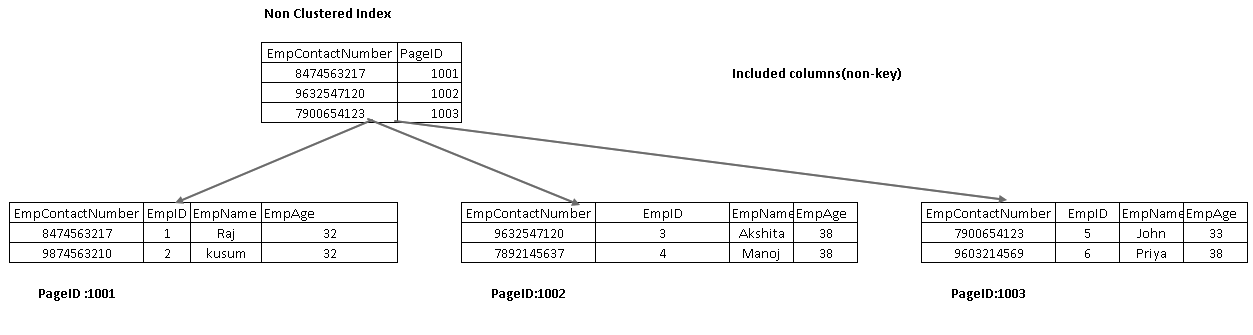
udfør SELECT-sætningen igen, og se den faktiske eksekveringsplan nu. Vi har ikke nøgleopslag og indlejret løkke i denne udførelsesplan:

lad os holde markøren over indekssøgningen og se listen over outputkolonner. Kan finde alle de kolonner ved hjælp af denne ikke-grupperet indeks søge:
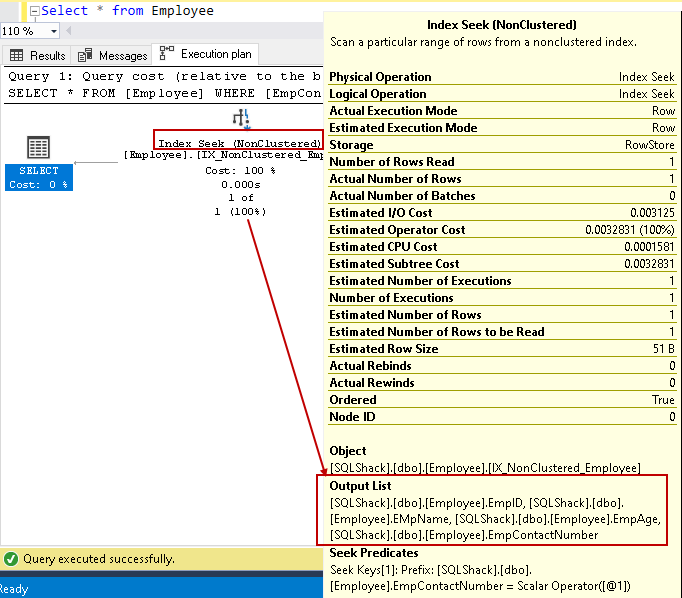
vi kan forbedre forespørgselsydelsen ved hjælp af dækningsindekset ved hjælp af inkluderede ikke-nøglekolonner. Det betyder dog ikke, at vi skal alle ikke-nøglekolonner i indeksdefinitionen. Vi skal være forsigtige med Indeksdesign og bør teste indeksadfærden inden implementering i produktionsmiljøet.
konklusion
i denne artikel undersøgte vi det ikke-klyngede indeks i serveren og dets anvendelse i kombination med det klyngede indeks. Vi bør omhyggeligt designe indekset i henhold til arbejdsbyrden og forespørgselsadfærd.
- forfatter
- Seneste indlæg

han er skaberen af en af de største gratis online samlinger af artikler om et enkelt emne, med sin 50-delt serie på server altid på tilgængelighed grupper. Baseret på hans bidrag til SERVERFÆLLESSKABET er han blevet anerkendt med forskellige priser, herunder den prestigefyldte “årets bedste forfatter” kontinuerligt i 2020 og 2021 på
Raj er altid interesseret i nye udfordringer, så hvis du har brug for rådgivning om ethvert emne, der er omfattet af hans skrifter, kan han nås på [email protected]
se alle indlæg af Rajendra Gupta
- brug ARM-skabeloner til at implementere vores containerinstanser med vores serverlinjebilleder – 21. December 2021
- Fjernskrivebordsadgang til vores RDS – Server med vores brugerdefinerede RDS – 14. December 2021
- Gem vores serverfiler i vedvarende lagerplads til vores Containerinstanser-December 10, 2021