Von: Ben Snaidero
Übersicht
In diesem Abschnitt werden die Dinge behandelt, die Sie über nicht gruppierte Indizes wissen müssen.
Was ist ein nicht gruppierter Index?
Ein nicht gruppierter Index (oder regulärer B-Tree-Index) ist ein Index, bei dem die Reihenfolge der Zeilen nicht mit der physischen Reihenfolge der tatsächlichen Daten übereinstimmt. Es ist insteadordered durch die Spalten, die den Index bilden. In einem nicht gruppierten Index enthalten die Blattseiten des Index keine tatsächlichen Daten, sondern Pointer zu den tatsächlichen Daten. Diese Zeiger würden auf die Clustered-Index-Datapage verweisen, auf der die tatsächlichen Daten vorhanden sind (oder auf die Heap-Seite, wenn in der Tabelle kein Clustered-Index vorhanden ist).
Warum nicht gruppierte Indizes erstellen
Der Hauptvorteil eines nicht gruppierten Index in einer Tabelle besteht darin, dass er schnellen Zugriff auf Daten bietet. Der Index ermöglicht es dem Datenbankmodul, Daten schnell zu lokalisieren, ohne die gesamte Tabelle durchsuchen zu müssen. Wenn eine Tabelle größer wird, ist es sehr wichtig, dass der Tabelle die richtigen Indizes hinzugefügt werden, da ohne anyindexes die Abfrageleistung dramatisch abnimmt.
Wann sollten nicht gruppierte Indizes erstellt werden?
Es gibt zwei Fälle, in denen ein nicht gruppierter Index für eine Tabelle von Vorteil ist. Erstens, wenn es mehr als einen Satz von Spalten gibt, die in den WHERE clauseof-Abfragen verwendet werden, die auf die Tabelle zugreifen. Ein zweiter Index (vorausgesetzt, es ist bereits ein Clusterindex für die Primärschlüsselspalte vorhanden) beschleunigt die Ausführungszeiten und reduziertio für die anderen Abfragen. Zweitens, wenn Ihre Abfragen häufig erfordern, dass Daten in einer bestimmten Reihenfolge zurückgegeben werden, kann ein Index für diese Spalten die erforderliche CPU- und Speichermenge reduzieren, da keine zusätzliche Sortierung erforderlich ist, da die Daten im Index bereits geordnet sind.
Das folgende Beispiel zeigt, dass zum Abrufen der Daten kein Tabellenscan erforderlich ist, sondern nur eine Indexsuche nach dem nicht gruppierten Index und eine Suche nach dem gruppierten Index, um die Daten abzurufen. Beachten Sie auch, dass keine Sortierung erforderlich ist, da sich die Daten bereits in der richtigen Reihenfolge befinden.
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

So erstellen Sie einen nicht gruppierten Index
Das Erstellen eines nicht gruppierten Indexes ist im Grunde dasselbe wie das Erstellen eines gruppierten Indexes, aber anstatt theCLUSTEREDclause wir specifyNONCLUSTERED . Wir können diese Klausel auch ganz weglassen, da ein non-clustered beim Erstellen eines Index der Standard ist.
Die folgende TSQL zeigt ein Beispiel für jede Anweisung.
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
Was ist ein Abdeckungsindex?
Ein Abdeckungsindex ist ein Index, der aus allen (oder mehreren) Spalten besteht, die erforderlich sind, um eine Abfrage als Schlüsselspalten des Index zu erfüllen. Wenn ein Abdeckungsindex zum Ausführen einer Abfrage verwendet werden kann, sind weniger E / A-Vorgänge erforderlich, da der Optimierer keine zusätzlichen Suchvorgänge mehr ausführen muss, um die tatsächlichen Tabellendaten abzurufen.
Unten finden Sie ein Beispiel für die TSQL, mit der Sie einen Covering-Index für die Produkttabelle erstellen können.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
Die folgende TSQL-Abfrage kann jetzt ausgeführt werden, indem nur auf den neuen Index zugegriffen wird, den Sie gerade erstellt haben, da alle Spalten in der Abfrage Teil des Index sind.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
Der followingEXPLAIN-Plan bestätigt, dass für diese Abfrage keine zusätzliche Suche erforderlich ist.

Was ist ein Index mit enthaltenen Spalten?
Ein mit enthaltenen Spalten erstellter Index ist ein nicht gruppierter Index, der auch Spalten ohne Schlüssel in den Blattknoten des Index enthält, ähnlich einem gruppierten Index. Die Verwendung der enthaltenen Spalten bietet einige Vorteile. Erstens gibt es Ihnen die Möglichkeit, Spaltentypen, die nicht als Indexschlüssel zulässig sind, in Ihren Index aufzunehmen. Wenn alle Spalten in Ihrer Abfrage entweder ein Indexschlüssel oder eine enthaltene Spalte sind, muss die Abfrage keine zusätzliche Suche mehr durchführen, um alle Daten abzurufen, die zur Erfüllung der Abfrage erforderlich sind, was zu weniger Festplattenvorgängen führt. Dies ähnelt dem zuvor erwähnten Deckungsindex.
Wenn Sie dasselbe Beispiel von oben verwenden, erstellt die folgende TSQL denselben Index, außer dass die Spalte ProductNumber als enthaltene Spalte und nicht als Indexschlüsselspalte referenziert wird.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
Wenn Sie dieselbe Abfrage wie oben verwenden, sollte dies auch ausgeführt werden können, ohne dass zusätzliche Suchvorgänge erforderlich sind.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
Der followingEXPLAIN-Plan bestätigt, dass auch für diese Abfrage keine zusätzliche Suche erforderlich ist.

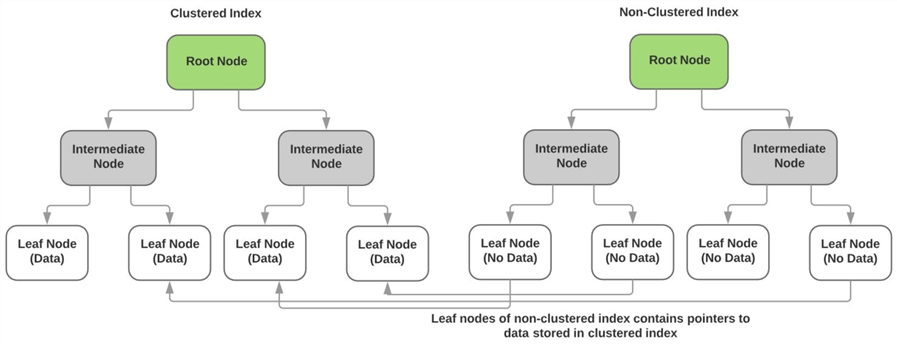
Nicht gruppierte Indexebeziehung zum gruppierten Index
Wie oben beschrieben, speichert der gruppierte Index die tatsächlichen Daten der Nicht-Schlüsselspalten in den Blattknoten des Index. Die Blattknoten jedes Nicht-clusteredindex enthalten keine Daten und weisen stattdessen Zeiger auf die tatsächliche Datenseite (oder den Blattknoten) des gruppierten Index auf. Das folgende Diagramm veranschaulicht diespunkt.
Gefilterte Indizes
Was ist das?
Eingefilterter Index ist ein spezieller Indextyp, bei dem nur ein bestimmter Teil der Zeilen der Tabelle indiziert wird. Basierend auf den Filterkriterien, die beim Erstellen des Index angewendet werden, werden nur die verbleibenden Zeilen indiziert, wodurch Speicherplatz gespart, die Abfrageleistung verbessert und der Wartungsaufwand verringert werden kann, da der Index viel kleiner ist.
Warum es verwenden?
Gefilterte Indizes sind nützlich, wenn Sie Indizes für Tabellen erstellen, in denen in bestimmten Spalten viele Nullwerte vorhanden sind oder bestimmte Spalten eine sehr geringe Kardinalität aufweisen und Sie häufig einen niedrigen Frequenzwert abfragen.
Wie erstelle ich es?
Ein gefilterter Index wird einfach durch Hinzufügen einer WHERE-Klausel zu einer Nicht-clusteredindex-Erstellungsanweisung erstellt. Die folgende TSQL ist ein Beispiel für die Syntax zum Erstellen eines gefilterten Index.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
Confirm Index Usage
Die folgende Abfrage sollte unseren neu erstellten Index verwenden, da nur sehr wenige Datensätze in der Tabelle mit ShipDate NULL . Hier ist die TSQL.
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;