Dieser Artikel enthält eine Einführung in den nicht gruppierten Index in SQL Server anhand von Beispielen.
Einführung
In einem früheren Artikel Übersicht über gruppierte SQL Server-Indizes haben wir die Anforderungen an einen Index und gruppierte Indizes in SQL Server untersucht.
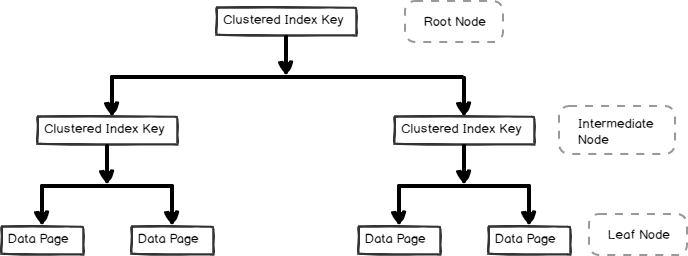
Bevor wir fortfahren, lassen Sie uns eine kurze Zusammenfassung des SQL Server Clustered Index:
- Es sortiert Daten physisch nach dem Clusterindexschlüssel
- Wir können nur einen Clusterindex pro Tabelle haben
- Eine Tabelle ohne Clusterindex ist ein Heap und kann zu Leistungsproblemen führen
- SQL Server erstellt automatisch einen Clusterindex für die Primärschlüsselspalte
- Ein Clusterindex für die Primärschlüsselspalte
Nicht gruppierte Indizes sind auch nützlich für die Abfrageleistung und -optimierung in Abhängigkeit von der Abfrageauslastung. In diesem Artikel untersuchen wir den nicht gruppierten Index und seine Interna.
Übersicht über den nicht gruppierten Index in SQL Server
In einem nicht gruppierten Index enthält der Blattknoten nicht die tatsächlichen Daten. Es besteht aus einem Zeiger auf die tatsächlichen Daten.
- Wenn die Tabelle einen gruppierten Index enthält, zeigt der Blattknoten auf die gruppierte Indexdatenseite, die aus tatsächlichen Daten besteht
- Wenn die Tabelle ein Heap ist (ohne gruppierten Index), zeigt der Blattknoten auf die Heapseite
Im folgenden Bild können wir die Blattebene des nicht gruppierten Index betrachten, die auf die Datenseite im gruppierten Index zeigt:
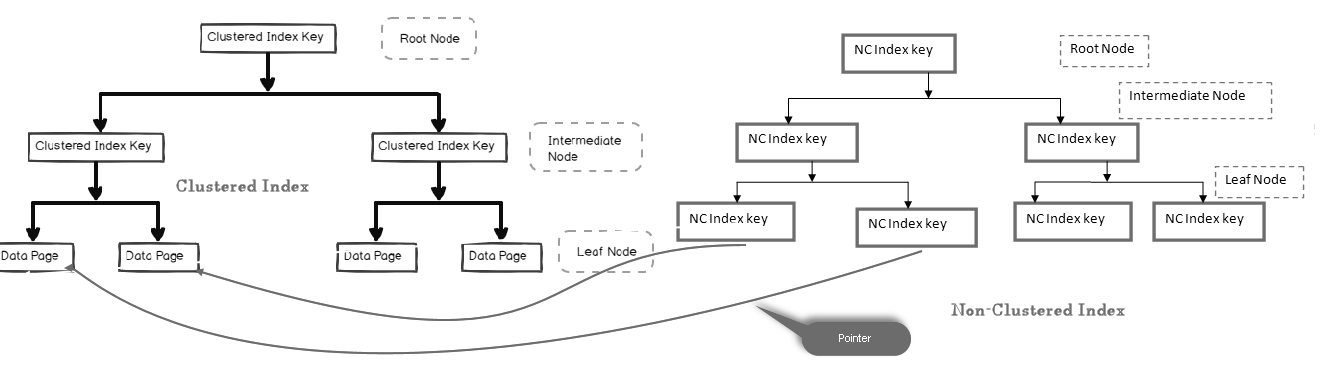
Wir können mehrere nicht gruppierte Indizes in SQL-Tabellen haben, da es sich um einen logischen Index handelt und Daten im Vergleich zum gruppierten Index nicht physisch sortiert werden.
Lassen Sie uns den nicht gruppierten Index in SQL Server anhand eines Beispiels verstehen.
-
Erstellen Sie eine Mitarbeitertabelle ohne Index
123456TABELLE dbo ERSTELLEN.Mitarbeiter(EmpID INT,EmpName VARCHAR(50),eMPAGE INT,EmpContactNumber VARCHAR(10)); -
Fügen Sie einige Datensätze ein
123In Mitarbeiterwerte einfügen (1, ‚Raj‘,32,8474563217)In Mitarbeiterwerte einfügen (2,’kusum‘,30,9874563210)In Mitarbeiterwerte einfügen (3, ‚Akshita‘,28,9632547120) -
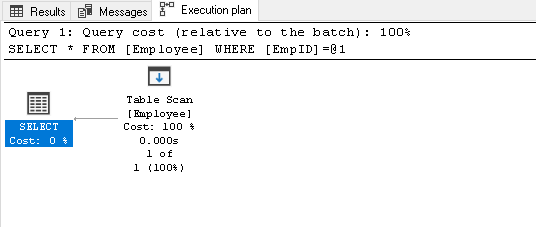
Suchen Sie nach dem EmpID 2 und suchen Sie nach dem tatsächlichen Ausführungsplan
1Wählen Sie * from Employee where EmpID=2Es führt einen Tabellenscan durch, da wir keinen Index für diese Tabelle haben:
-
Erstellen Sie einen eindeutigen Clusterindex für die EmpID-Spalte
1ERSTELLEN SIE EINEN EINDEUTIGEN CLUSTERINDEX IX_Clustered_Empployee AUF dbo.Mitarbeiter (EmpID); -
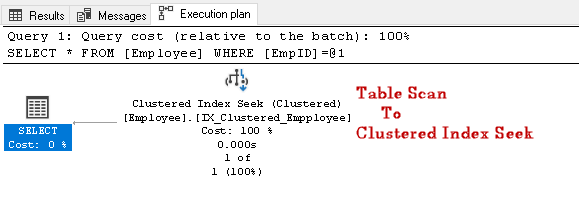
Suchen Sie nach dem EmpID 2 und suchen Sie nach dem tatsächlichen Ausführungsplan
In diesem Ausführungsplan können wir feststellen, dass sich der Tabellenscan in einen gruppierten Index ändert.:
Führen wir eine weitere SQL-Abfrage aus, um einen Mitarbeiter mit einer bestimmten Kontaktnummer zu suchen:
|
1
|
Wählen Sie * von Employee where EmpContactNumber=’9874563210′
|
Wir haben keinen Index für die Spalte EmpContactNumber, daher verwendet der Abfrageoptimierer den gruppierten Index, durchsucht jedoch den gesamten Index, um den Datensatz abzurufen:
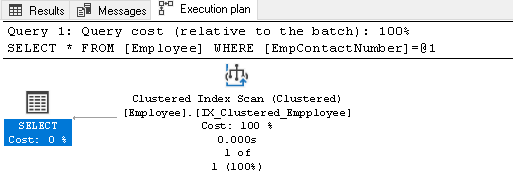
Klicken Sie mit der rechten Maustaste auf den Ausführungsplan und wählen Sie Ausführungsplan-XML anzeigen:
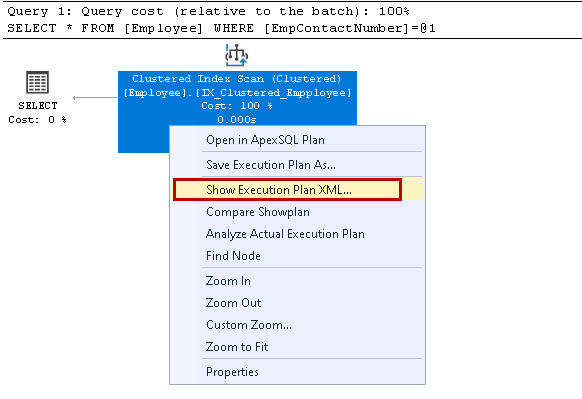
Es öffnet den XML-Ausführungsplan im neuen Abfragefenster. Hier stellen wir fest, dass der Clustered-Indexschlüssel verwendet und die einzelnen Zeilen zum Abrufen des Ergebnisses gelesen werden:

Fügen wir mit dem folgenden Skript einige weitere Datensätze in die Employee-Tabelle ein:
|
1
2
3
|
In Mitarbeiterwerte einfügen (4, ‚Manoj‘,38,7892145637)
In Mitarbeiterwerte einfügen (5,‘)‘,33,7900654123)
In Mitarbeiterwerte einfügen (6, ‚Priya‘,18,9603214569)
|
Wir haben sechs Mitarbeiterdatensätze in dieser Tabelle. Führen Sie nun die select-Anweisung erneut aus, um Mitarbeiterdatensätze mit einer bestimmten Kontaktnummer abzurufen:
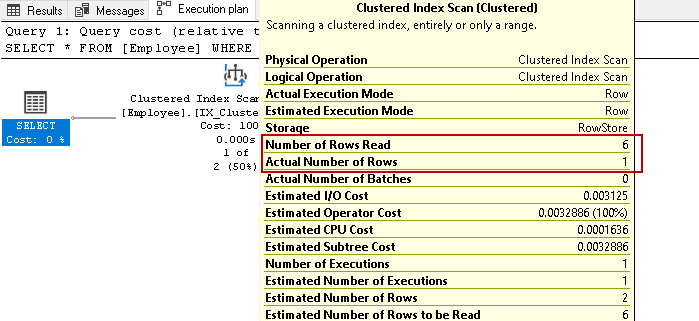
Es durchsucht erneut alle sechs Zeilen nach dem Ergebnis basierend auf der angegebenen Bedingung. Stellen Sie sich vor, wir haben Millionen von Datensätzen in der Tabelle. Wenn SQL Server alle Indexschlüsselzeilen lesen muss, wäre dies eine ressourcen- und zeitaufwändige Aufgabe.
Wir können den Clustered Index (nicht die tatsächliche Darstellung) im B-Tree-Format gemäß dem folgenden Bild darstellen:

In der vorherigen Abfrage liest SQL Server die Stammknotenseite und ruft jede Blattknotenseite und Zeile für den Datenabruf ab.
Erstellen wir nun einen eindeutigen nicht gruppierten Index in SQL Server für die Tabelle Employee in der Spalte EmpContactNumber als Indexschlüssel:
|
1
|
ERSTELLEN SIE EINEN EINDEUTIGEN NICHT GRUPPIERTEN INDEX IX_NonClustered_Employee AUF dbo.Mitarbeiter (EmpContactNumber);
|
Bevor wir diesen Index erläutern, führen Sie die SELECT-Anweisung erneut aus und zeigen Sie den tatsächlichen Ausführungsplan an:
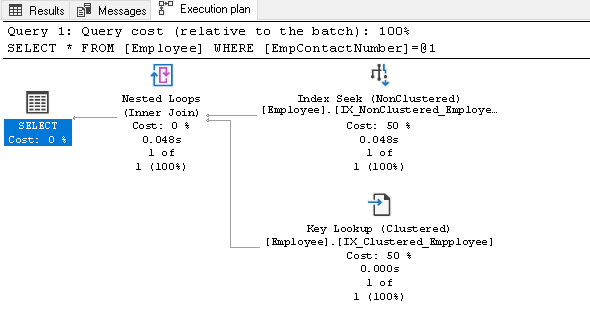
In diesem Ausführungsplan können wir zwei Komponenten sehen:
- Indexsuche (nicht gruppiert)
- Schlüsselsuche (gruppiert)
Um diese Komponenten zu verstehen, müssen wir einen nicht gruppierten Index im SQL Server-Design betrachten. Hier sehen Sie, dass der Blattknoten den nicht gruppierten Indexschlüssel (EmpContactNumber) und den gruppierten Indexschlüssel (EmpID) enthält):
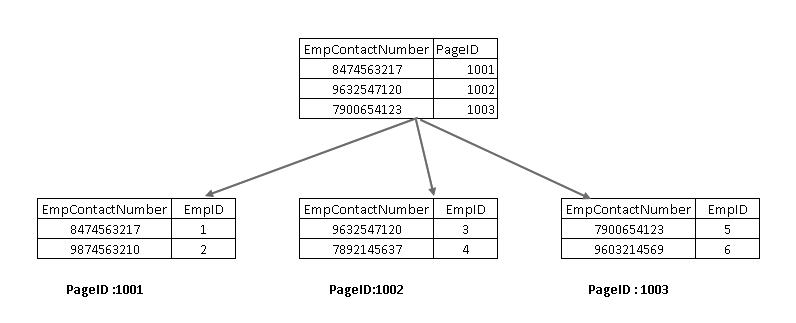
Wenn Sie nun die SELECT-Anweisung erneut ausführen, wird sie mit dem nicht gruppierten Indexschlüssel durchlaufen und zeigt auf eine Seite mit dem gruppierten Indexschlüssel:
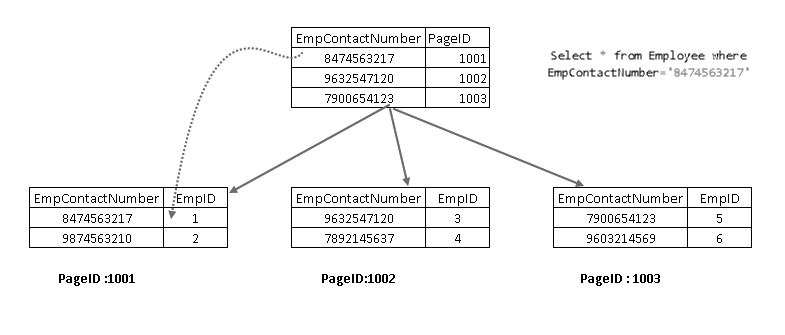
Es zeigt, dass es den Datensatz mit einer Kombination aus clustered Index key und non-clustered Index key abruft. Sie können die vollständige Logik für die SELECT-Anweisung wie unten gezeigt sehen:
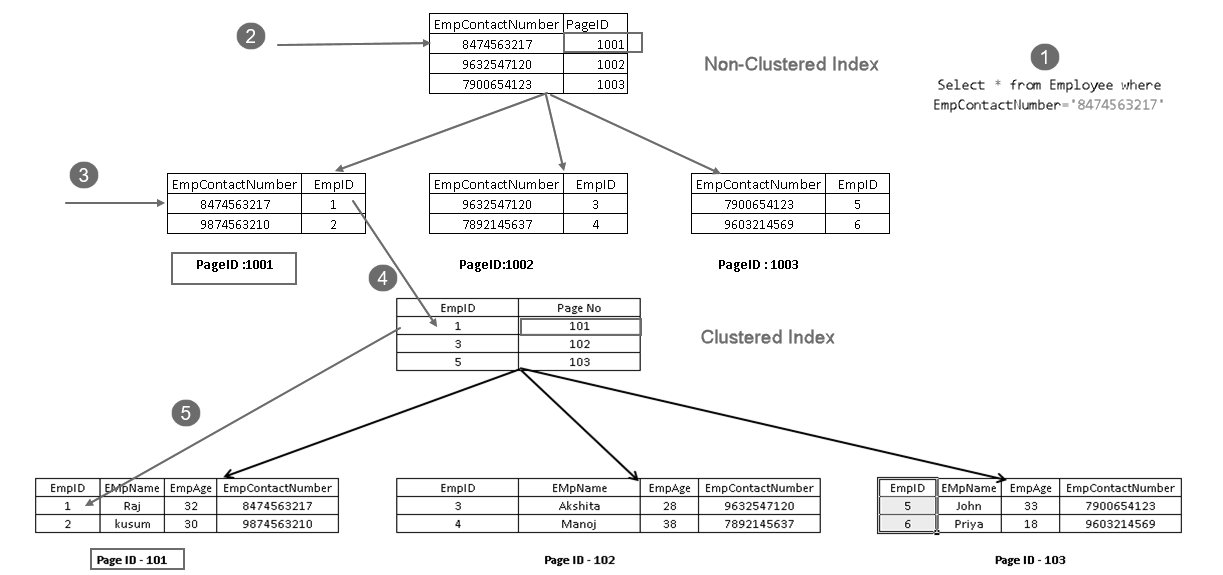
- Ein Benutzer führt eine select-Anweisung aus, um Mitarbeiterdatensätze zu finden, die mit einer angegebenen Kontaktnummer übereinstimmen
- Query Optimizer verwendet einen nicht gruppierten Indexschlüssel und ermittelt die Seitennummer 1001
- Diese Seite besteht aus einem gruppierten Indexschlüssel. Sie können EmpID 1 im obigen Bild sehen
- SQL Server ermittelt Seite 101, die aus EmpID 1-Datensätzen besteht, mithilfe des Clusterindexschlüssels
- Es liest die übereinstimmende Zeile und gibt die Ausgabe an den Benutzer zurück
Zuvor haben wir gesehen, dass es sechs Zeilen liest, um die übereinstimmende Zeile abzurufen, und eine Zeile in der Ausgabe zurückgibt. Schauen wir uns einen Ausführungsplan mit dem nicht gruppierten Index an:

Nicht eindeutiger nicht gruppierter Index in SQL Server
Wir können mehrere nicht gruppierte Indizes in einer SQL-Tabelle haben. Zuvor haben wir einen eindeutigen nicht gruppierten Index für die Spalte EmpContactNumber erstellt.
Führen Sie vor dem Erstellen des Index die folgende Abfrage aus, damit der Wert in der Spalte eMPAGE doppelt vorhanden ist:
|
1
2
3
|
Mitarbeitersatz aktualisieren eMPAGE = 32 where EmpID=2
Mitarbeitersatz aktualisieren eMPAGE=38 where EmpID=6
Mitarbeitersatz aktualisieren eMPAGE=38 where EmpID=3
|
Führen wir die folgende Abfrage für einen nicht eindeutigen nicht gruppierten Index aus. In der Abfragesyntax geben wir kein eindeutiges Schlüsselwort an und weisen SQL Server an, einen nicht eindeutigen Index zu erstellen:
|
1
|
ERSTELLEN SIE DEN NICHT GRUPPIERTEN INDEX NCIX_Employee_EmpAge AUF dbo.Mitarbeiter(eMPAGE);
|
Wie wir wissen, sollte der Schlüssel eines Index eindeutig sein. In diesem Fall möchten wir einen nicht eindeutigen Schlüssel hinzufügen. Es stellt sich die Frage: Wie wird SQL Server diesen Schlüssel als einzigartig machen?
SQL Server führt die folgenden Schritte aus:
- Fügt den gruppierten Indexschlüssel auf den Blatt- und Nichtblattseiten des nicht eindeutigen nicht gruppierten Indexes hinzu
- Wenn der gruppierte Indexschlüssel ebenfalls nicht eindeutig ist, wird ein 4-Byte-Uniquifier hinzugefügt, sodass der Indexschlüssel eindeutig ist
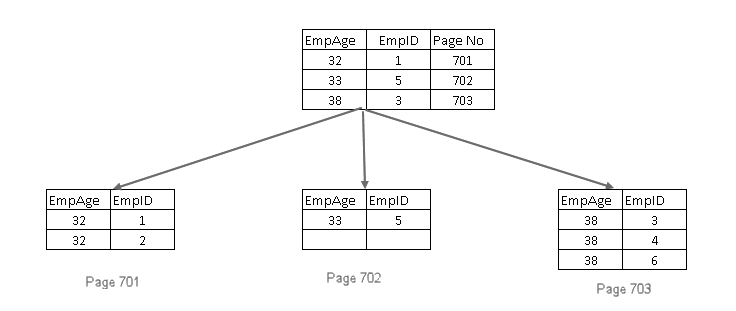
Nicht-Schlüsselspalten in nicht gruppierten Index in SQL Server einschließen
Schauen wir uns den folgenden tatsächlichen Ausführungsplan der folgenden Abfrage noch einmal an:
|
1
2
|
Wählen Sie * aus Mitarbeiter
where EmpContactNumber=’8474563217′
|
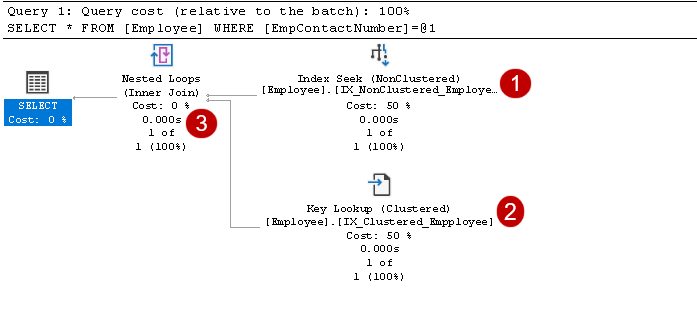
Es enthält Indexsuch- und Schlüsselsuchoperatoren, wie im obigen Bild gezeigt:
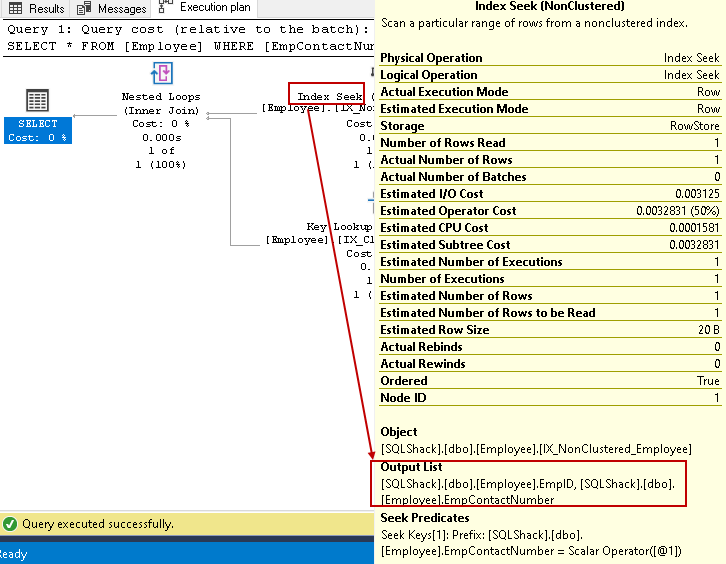
- Der Index sucht: SQL Query Optimizer verwendet eine Indexsuche für den nicht gruppierten Index und ruft die Spalten EmpID, EmpContactNumber
-
abIn diesem Schritt verwendet Query Optimizer die Schlüsselsuche für den gruppierten Index und ruft Werte für die Spalten EmpName und eMPAGE ab
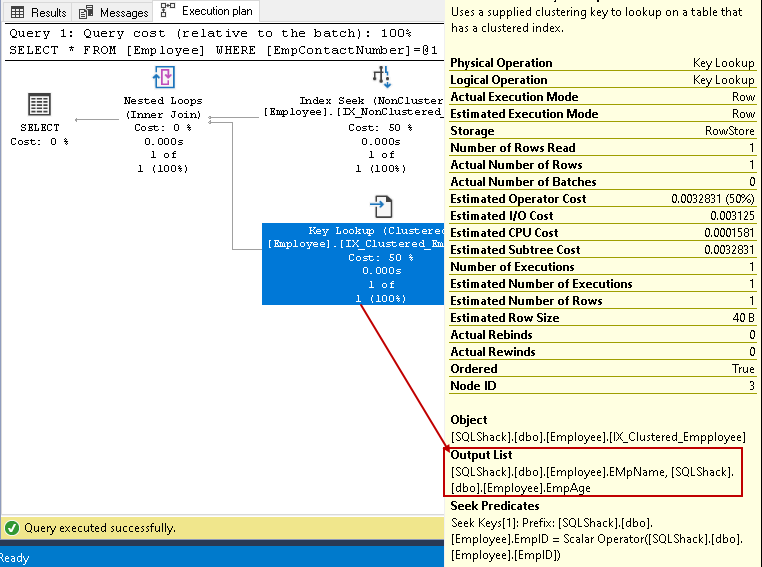
-
In diesem Schritt verwendet der Abfrageoptimierer die verschachtelten Schleifen für jede Zeilenausgabe aus dem nicht gruppierten Index zum Abgleich mit dem gruppierten Index Zeile
Die verschachtelte Schleife kann ein kostspieliger Operator für große Tabellen sein. Wir können die Kosten reduzieren, indem wir die Nicht-Clustered-Index-Nicht-Key-Spalten verwenden. Wir geben die Non-Key-Spalte im nicht gruppierten Index mithilfe der index-Klausel an.
Lassen Sie uns den nicht gruppierten Index in SQL Server mithilfe der enthaltenen Spalten löschen und erstellen:
|
1
2
3
4
5
6
7
|
DROP-INDEX AUF .
GEHEN SIE ZU
ERSTELLEN SIE EINEN EINDEUTIGEN NICHT GRUPPIERTEN INDEX .
(
ASC
)
INCLUDE(emname,eMPAGE)
|
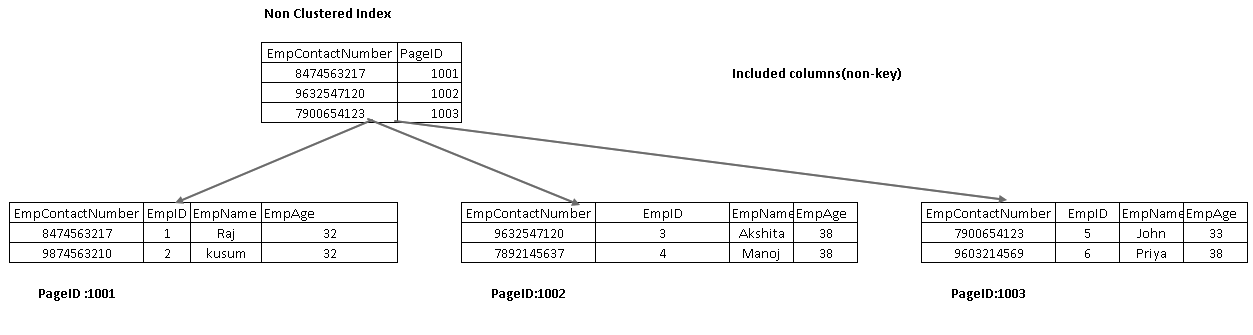
Enthaltene Spalten sind Teil des Blattknotens in einem Indexbaum. Es hilft, die Daten aus dem Index selbst abzurufen, anstatt sie zum Datenabruf weiter zu durchlaufen.
Im folgenden Bild erhalten wir beide enthaltenen Spalten EmpName und eMPAGE als Teil des Blattknotens:
Führen Sie die SELECT-Anweisung erneut aus und zeigen Sie jetzt den tatsächlichen Ausführungsplan an. Wir haben keine Schlüsselsuche und verschachtelte Schleife in diesem Ausführungsplan:

Bewegen wir den Mauszeiger über den Index und zeigen die Liste der Ausgabespalten an. SQL Server kann alle Spalten mit diesem nicht gruppierten Index finden.:
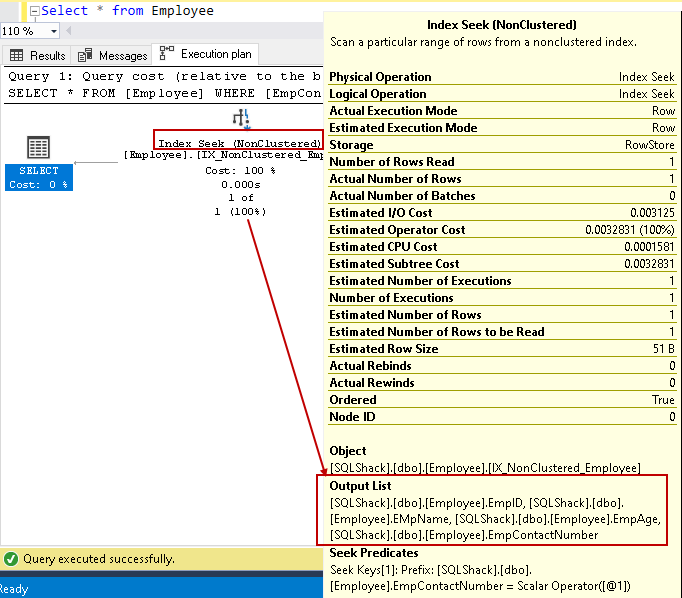
Wir können die Abfrageleistung mithilfe des covering Index mithilfe der enthaltenen Nicht-Schlüsselspalten verbessern. Dies bedeutet jedoch nicht, dass wir alle Nicht-Schlüsselspalten in der Indexdefinition haben sollten. Wir sollten beim Indexdesign vorsichtig sein und das Indexverhalten vor der Bereitstellung in der Produktionsumgebung testen.
Fazit
In diesem Artikel haben wir den nicht gruppierten Index in SQL Server und seine Verwendung in Kombination mit dem gruppierten Index untersucht. Wir sollten den Index sorgfältig gemäß der Arbeitslast und dem Abfrageverhalten entwerfen.
- Autor
- Neueste Beiträge

Er ist der Schöpfer einer der größten kostenlosen Online-Sammlungen von Artikeln zu einem einzigen Thema, mit seiner 50-teiligen Serie über SQL Server Always On Availability Groups. Basierend auf seinem Beitrag zur SQL Server-Community wurde er 2020 und 2021 bei SQLShack mit verschiedenen Auszeichnungen ausgezeichnet, darunter dem renommierten „Best author of the year“.
Raj ist immer an neuen Herausforderungen interessiert, wenn Sie also Beratungshilfe zu einem Thema benötigen, das in seinen Schriften behandelt wird, kann er unter Rajendra erreicht [email protected]
Alle Beiträge von Rajendra Gupta anzeigen
- Verwenden von ARM-Vorlagen zum Bereitstellen von Azure-Containerinstanzen mit SQL Server Linux-Images – 21. Dezember 2021
- Remotedesktopzugriff für AWS RDS SQL Server mit Amazon RDS Custom – 14. Dezember 2021
- Speichern von SQL Server-Dateien im persistenten Speicher für Azure-Containerinstanzen – Dezember 10, 2021