Este artículo ofrece una introducción del índice no agrupado en SQL Server mediante ejemplos.
Introducción
En un artículo anterior, Descripción general de los índices agrupados de SQL Server, exploramos el requisito de un índice y de índices agrupados en SQL Server.
Antes de continuar, vamos a tener un resumen rápido del índice agrupado de SQL Server:
- Ordena físicamente los datos de acuerdo con la clave de índice en clúster
- Solo podemos tener un índice en clúster por tabla
- Una tabla sin un índice en clúster es un montón, y puede provocar problemas de rendimiento
- SQL Server crea automáticamente un índice en clúster para la columna de clave primaria
- formato de árbol b y contiene las páginas de datos en el nodo hoja, como se muestra a continuación
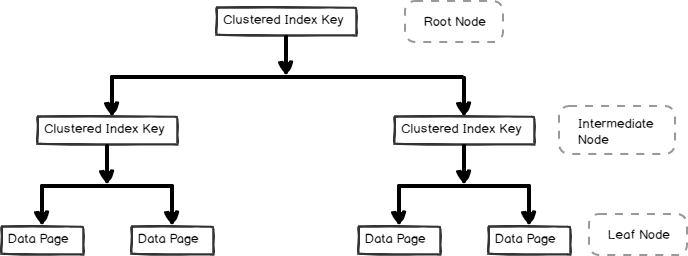
Índices no agrupados también son útiles para el rendimiento y la optimización de las consultas en función de la carga de trabajo de las consultas. En este artículo, exploremos el índice no agrupado y sus aspectos internos.
Descripción general del índice no agrupado en SQL Server
En un índice no agrupado, el nodo hoja no contiene los datos reales. Consiste en un puntero a los datos reales.
- Si la tabla contiene un índice agrupado, el nodo hoja apunta a la página de datos de índice agrupado que consiste en datos reales
- Si la tabla es un montón (sin un índice agrupado), el nodo hoja apunta a la página de montón
En la imagen de abajo, podemos ver el nivel de hoja del índice no agrupado apuntando hacia la página de datos en el índice agrupado:
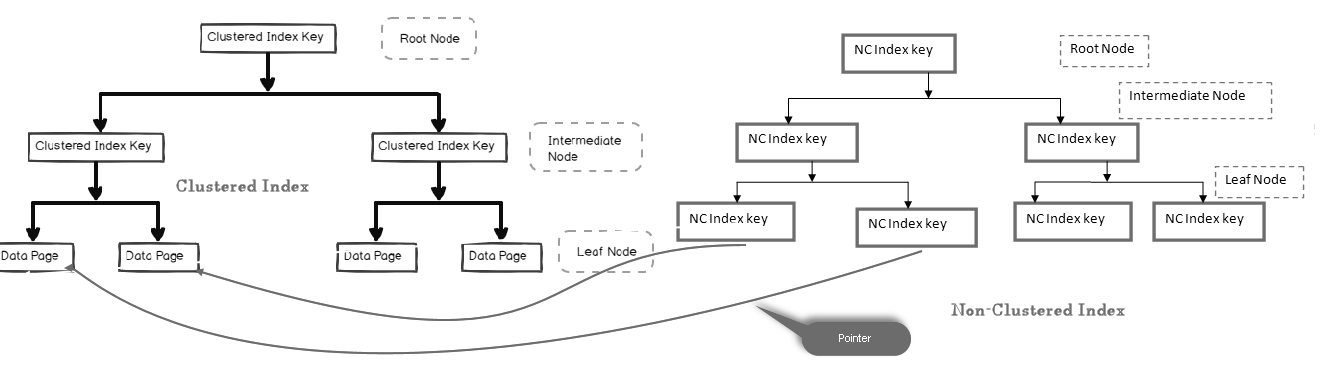
podemos tener varios índices no agrupados en tablas SQL porque es un índice lógico y no ordenar los datos físicamente en comparación con el índice agrupado.
Entendamos el índice no agrupado en SQL Server con un ejemplo.
-
Crear una tabla de Empleados sin ningún tipo de índice en ella
123456CREAR la TABLA dbo.Empleado(EmpID INT,empName VARCHAR(50),eMPAGE INT,EmpContactNumber VARCHAR(10)); -
Insertar algunos registros
123Insert into Empleado values(1,’Raj’,32,8474563217)Insert into Empleado values(2,’kusum’,30,9874563210)Insert into Empleado values(3,’Akshita’,28,9632547120) -
la Búsqueda de la EmpID 2 y busque el plan de ejecución real de la misma
1Select * from Empleado donde EmpID=2Se hace un examen de la tabla porque no tenemos ningún índice en esta tabla:
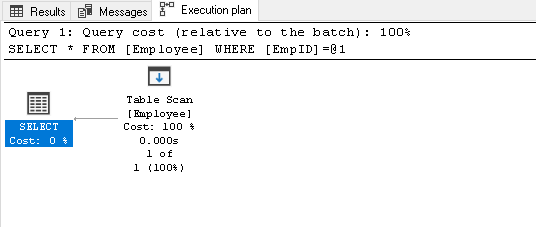
-
Crear un índice agrupado único en la columna EmpID
1CREAR ÍNDICE AGRUPADO ÚNICO IX_Clustered_Empployee EN dbo.Empleado (EmpID); -
Busque el EmpID 2 y busque el plan de ejecución real del mismo
En este plan de ejecución, podemos observar que el escaneo de tabla cambia a una búsqueda de índice en clúster:
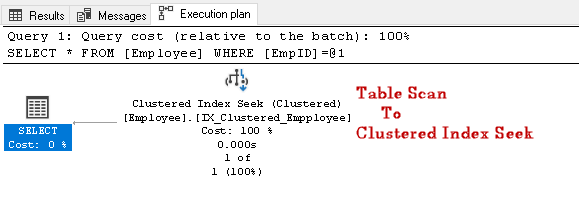
Ejecutemos otra consulta SQL para buscar Empleados que tengan un número de contacto específico:
|
1
|
Seleccione * del Empleado donde EmpContactNumber=’9874563210′
|
No tenemos un índice en la columna EmpContactNumber, por lo tanto, el Optimizador de consultas usa el índice agrupado, pero escanea todo el índice para recuperar el registro:
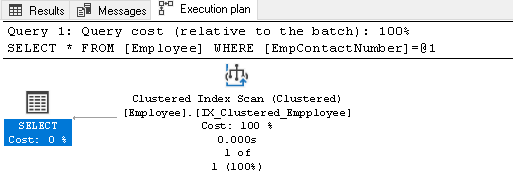
Haga clic con el botón derecho en el plan de ejecución y seleccione Mostrar XML del plan de ejecución:
Abre el plan de ejecución XML en la ventana nueva consulta. Aquí, notamos que utiliza la clave de índice agrupada y lee las filas individuales para recuperar el resultado:

Insertemos algunos registros más en la tabla de empleados con el siguiente script:
|
1
2
3
|
Insert into Empleado values(4,’Manoj’,38,7892145637)
Insert into Empleado values(5,’Juan’,33,7900654123)
Insert into Empleado values(6,’Priya’,18,9603214569)
|
Tenemos seis empleados de registros en esta tabla. Ahora, ejecute de nuevo la instrucción select para recuperar los registros de los empleados con un número de contacto específico:
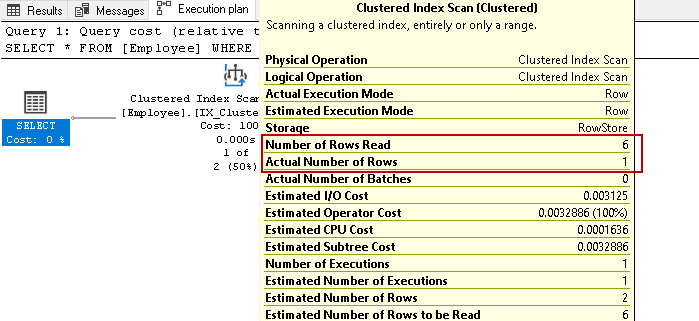
otra vez escaneados todos los seis filas para el resultado basado en la condición especificada. Imagina que tenemos millones de registros en la mesa. Si SQL Server tiene que leer todas las filas de claves de índice, sería una tarea que requeriría mucho tiempo y recursos.
Podemos representar el índice agrupado (no la representación real) en el formato de árbol B según la siguiente imagen:

En la consulta anterior, SQL Server lee la página del nodo raíz y recupera cada página y fila del nodo hoja para la recuperación de datos.
Ahora vamos a crear un índice único no agrupado en SQL Server en la tabla de empleados de la columna EmpContactNumber como clave de índice:
|
1
|
CREE UN ÍNDICE ÚNICO NO AGRUPADO IX_NonClustered_Employee EN dbo.Empleado (Número de contacto de EMPC);
|
Antes de explicar este índice, vuelva a ejecutar la instrucción SELECT y vea el plan de ejecución real:
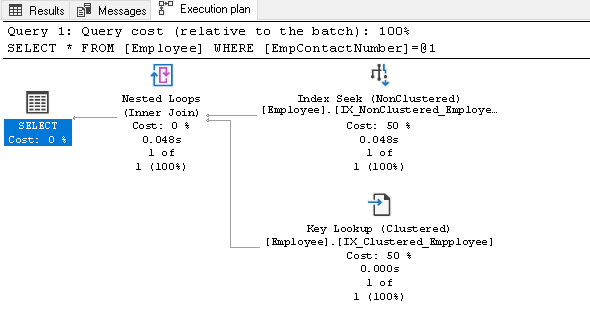
En este plan de ejecución, podemos ver dos componentes:
- Búsqueda de índices (no agrupada)
- Búsqueda de claves (Agrupada)
Para entender estos componentes, necesitamos mirar un índice no agrupado en el diseño de SQL Server. Aquí, puede ver que el nodo hoja contiene la clave de índice no agrupada (EmpContactNumber) y la clave de índice agrupada (EmpID):
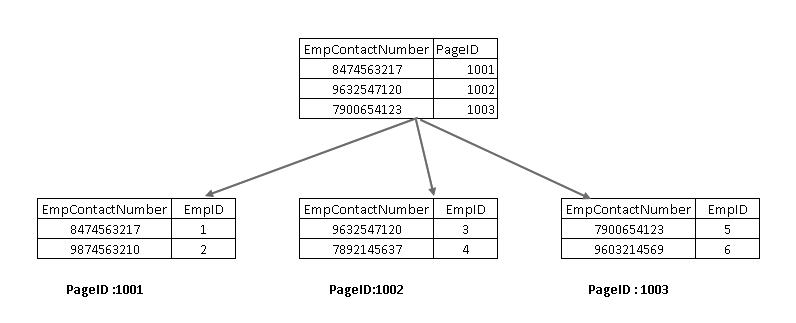
Ahora, si vuelve a ejecutar la instrucción SELECT, atraviesa utilizando la clave de índice no agrupada y apunta a una página con clave de índice agrupada:
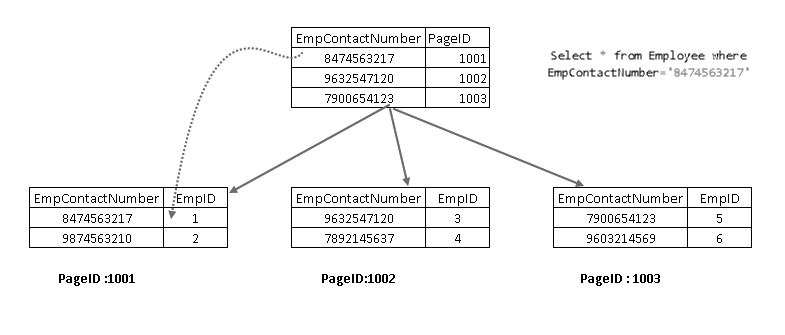
Muestra que recupera el registro con una combinación de clave de índice agrupada y clave de índice no agrupada. Puede ver la lógica completa de la instrucción SELECT como se muestra a continuación:
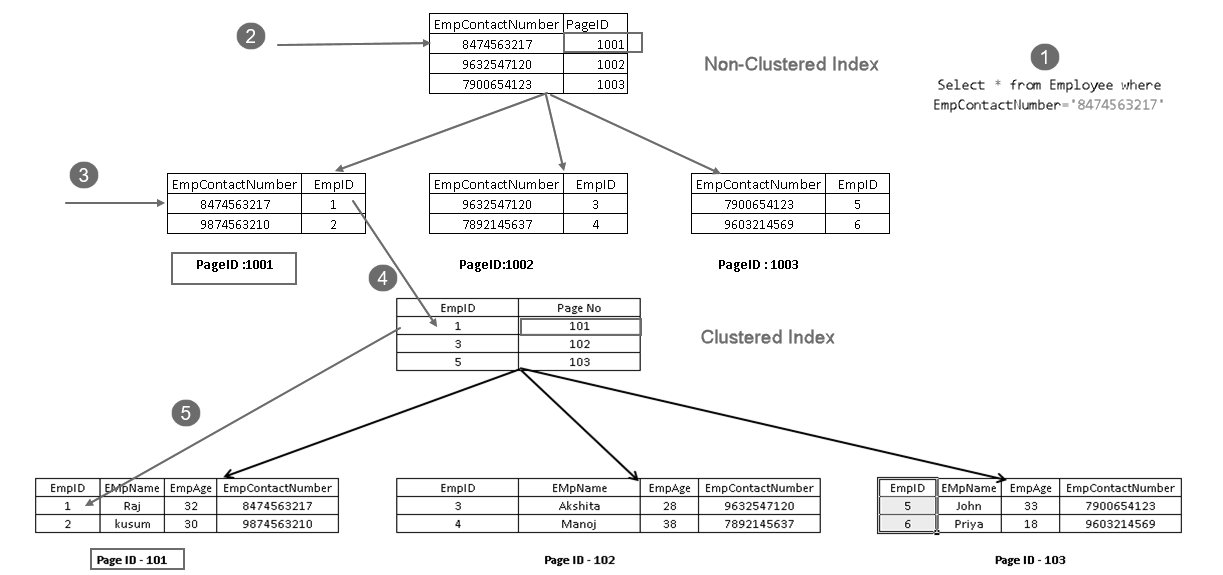
- Un usuario ejecuta una instrucción select para encontrar registros de empleados que coincidan con un número de contacto especificado
- El optimizador de consultas utiliza una clave de índice no agrupada y descubre el número de página 1001
- Esta página consta de una clave de índice agrupada. Puede ver EmpID 1 en la imagen anterior
- SQL Server encuentra la página no 101 que consiste en registros EmpID 1 utilizando la clave de índice agrupada
- Lee la fila coincidente y devuelve la salida al usuario
Anteriormente, vimos que lee seis filas para recuperar la fila coincidente y devuelve una fila en la salida. Veamos un plan de ejecución utilizando el índice no agrupado:

Índice no único no agrupado en SQL Server
Podemos tener varios índices no agrupados en una tabla SQL. Anteriormente, creábamos un índice único no agrupado en la columna EmpContactNumber.
Antes de crear el índice, ejecute la siguiente consulta para que tengamos un valor duplicado en la columna eMPAGE:
|
1
2
3
|
Update Empleado set EmpAge=32 donde EmpID=2
Update Empleado set EmpAge=38 donde EmpID=6
Update Empleado set EmpAge=38 donde EmpID=3
|
Vamos a ejecutar la consulta siguiente para no único índice no agrupado. En la sintaxis de consulta, no especificamos una palabra clave única, y le indica a SQL Server que cree un índice no único:
|
1
|
CREAR ÍNDICE no agrupado NCIX_Employee_EmpAge EN dbo.Empleado(EmpAge);
|
Como sabemos, la clave de un índice debe ser único. En este caso, queremos agregar una clave no única. Surge la pregunta: ¿Cómo hará SQL Server que esta clave sea única?
SQL Server hace lo siguiente:
- Agrega la clave de índice agrupada en las páginas hoja y no hoja del índice no agrupado no único
- Si la clave de índice agrupada tampoco es única, agrega un uniquificador de 4 bytes para que la clave de índice sea única
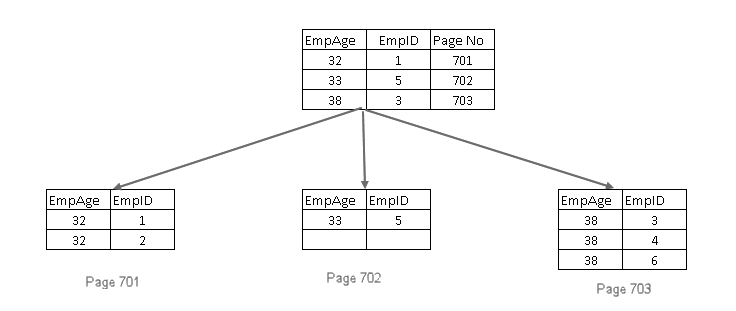
Incluir columnas sin clave en índice no agrupado en SQL Server
Veamos de nuevo el siguiente plan de ejecución real de la siguiente consulta:
|
1
2
|
Seleccione * de Empleado
donde EmpContactNumber=’8474563217′
|
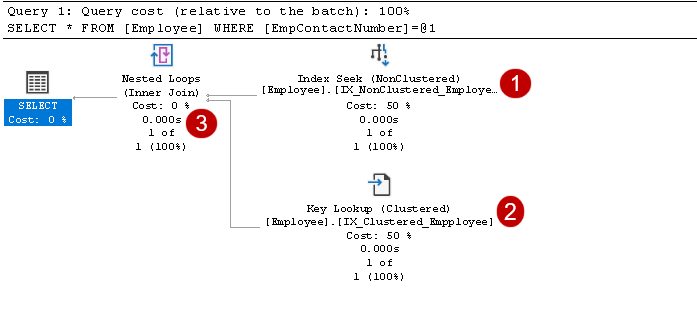
Incluye operadores de búsqueda de índices y búsqueda de claves, como se muestra en la imagen de arriba:
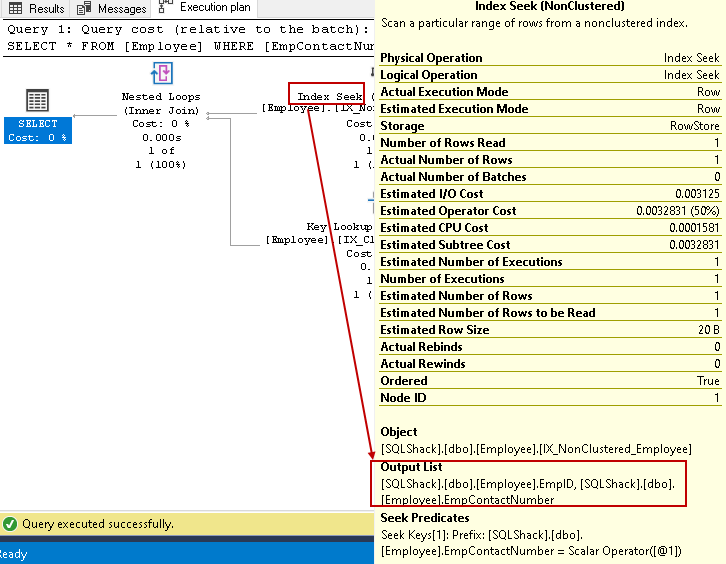
- El índice busca: El optimizador de consultas SQL utiliza una búsqueda de índice en el índice no agrupado y obtiene columnas EmpID, EmpContactNumber
-
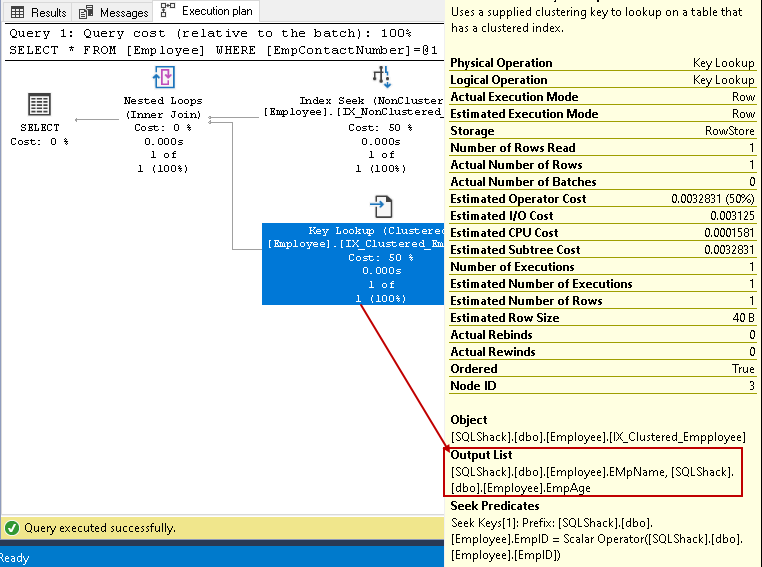
En este paso, el Optimizador de consultas utiliza la búsqueda de claves en el índice agrupado y obtiene valores para columnas empName y eMPAGE
-
En este paso, el Optimizador de consultas utiliza los bucles anidados para cada salida de fila del índice no agrupado para coincidir con la fila de índice agrupado
El bucle anidado puede ser un operador costoso para mesas grandes. Podemos reducir el costo utilizando las columnas no clave de índice no agrupadas. Especificamos la columna sin clave en el índice no agrupado usando la cláusula index.
Vamos a soltar y creó el índice no agrupado en SQL Server utilizando las columnas incluidas:
|
1
2
3
4
5
6
7
|
DROP INDEX EN .
IR
CREAR ÍNDICE ÚNICO NO AGRUPADO ACTIVADO .
(
ASC
)
INCLUYEN(EmpName,EmpAge)
|
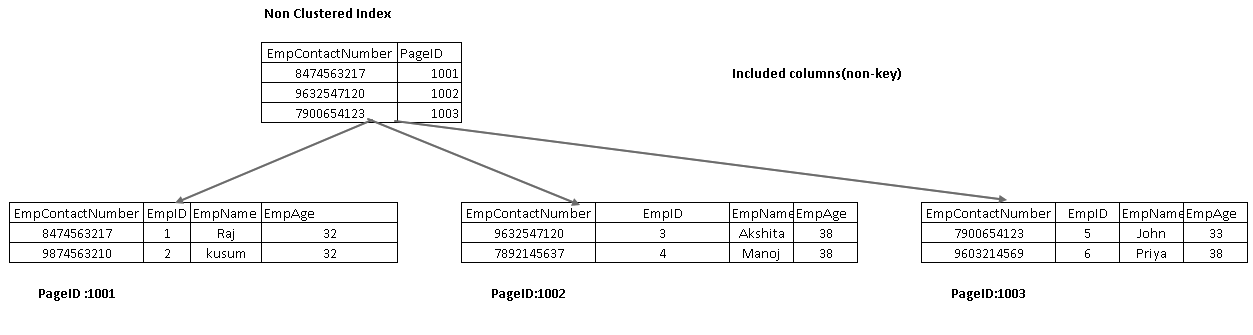
Incluye columnas son parte de la hoja de nodo en un árbol índice. Ayuda a obtener los datos del propio índice en lugar de recorrer más para la recuperación de datos.
En la siguiente imagen, obtenemos las dos columnas incluidas empName y eMPAGE como parte del nodo hoja:
Vuelva a ejecutar la instrucción SELECT y vea el plan de ejecución real ahora. No tenemos búsqueda de claves ni bucle anidado en este plan de ejecución:

Pasemos el cursor sobre la búsqueda de índice y veamos la lista de columnas de salida. SQL Server puede encontrar todas las columnas utilizando esta búsqueda de índice no agrupada:
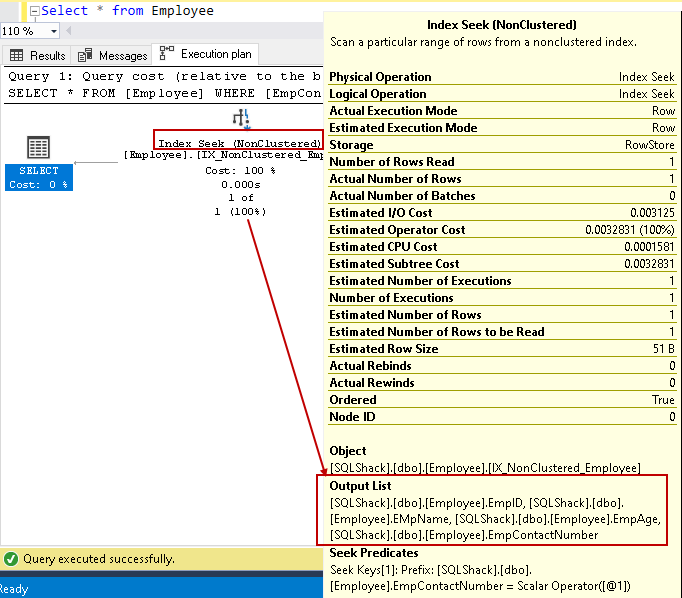
Podemos mejorar el rendimiento de las consultas utilizando el índice de cobertura con la ayuda de columnas no clave incluidas. Sin embargo, esto no significa que debamos incluir todas las columnas no clave en la definición del índice. Debemos tener cuidado en el diseño del índice y probar el comportamiento del índice antes de la implementación en el entorno de producción.
Conclusión
En este artículo, exploramos el índice no agrupado en SQL Server y su uso en combinación con el índice agrupado. Debemos diseñar cuidadosamente el índice según la carga de trabajo y el comportamiento de la consulta.
- Autor
- Publicaciones recientes

Es el creador de una de las mayores colecciones gratuitas en línea de artículos sobre un solo tema, con su serie de 50 partes en grupos de disponibilidad Always On de SQL Server. En base a su contribución a la comunidad de SQL Server, ha sido reconocido con varios premios, incluido el prestigioso «Mejor autor del año» de forma continua en 2020 y 2021 en SQLShack.
Raj siempre está interesado en nuevos desafíos, por lo que si necesita ayuda de consultoría sobre cualquier tema cubierto en sus escritos, puede comunicarse con él en rajendra.gupta16 @ gmail.com
Ver todos los mensajes de Rajendra Gupta
- Usar plantillas ARM para implementar instancias de contenedores de Azure con imágenes de SQL Server Linux – 21 de diciembre de 2021
- Acceso a escritorio remoto para AWS RDS SQL Server con Amazon RDS Personalizado – 14 de diciembre de 2021
- Almacenar archivos de SQL Server en Almacenamiento persistente para Instancias de contenedores de Azure-Diciembre 10, 2021