Par : Ben Snaidero
Aperçu
Dans cette section, nous aborderons les choses que vous devez savoir sur les index non clusterisés.
Qu’est-ce qu’un index non cluster
Un index non cluster (ou index régulier de l’arbre b) est un index où l’ordre des lignes ne correspond pas à l’ordre physique des données réelles. Il est insteadordered par les colonnes qui composent l’index. Dans un index non groupé, les pages de l’index ne contiennent aucune donnée réelle, mais contiennent plutôt des pointeurs vers les données réelles. Ces pointeurs pointeraient vers la page de données d’index en cluster où les données réelles existent (ou la page de tas si aucun index en cluster n’existe dans la table).
Pourquoi créer des index non clusterisés
Le principal avantage d’avoir un index non clusterisé sur une table est qu’il permet un accès rapide aux données. L’index permet au moteur de base de données de localiser les données rapidementsans avoir à parcourir la table entière. À mesure qu’une table s’agrandit, il est très important que les index corrects soient ajoutés à la table, car sans anyindexes, les performances des requêtes diminueront considérablement.
Quand faut-il créer des index non clusterisés
Il existe deux cas où avoir un index non clusterisé sur une table est bénéfique. Tout d’abord, lorsqu’il y a plus d’un ensemble de colonnes utilisées dans les requêtes WHERE clauseof qui accèdent à la table. Un deuxième index (en supposant qu’il existe déjà un index en cluster sur la colonne de clé primaire) accélérera les temps d’exécution et réduira le nombre de requêtes pour les autres requêtes. Deuxièmement, si vos requêtes nécessitent fréquemment que les données soient renvoyées dans un certain ordre, avoir un index sur ces colonnes peut réduire la quantité de CPU et de mémoire requise, car un tri supplémentaire n’aura pas besoin d’être effectué puisque les données de l’index sont déjà ordonnées.
L’exemple suivant montre qu’aucune analyse de table n’est nécessaire pour récupérer les données, juste une recherche d’index de l’index non clusteredindex et une recherche de l’index clusteredindex pour obtenir les données. Notez également qu’aucun tri n’est requis car les données sont déjà dans le bon ordre.
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

Comment créer un index non cluster
La création d’un index non cluster est fondamentalement la même chose que la création d’un index cluster, mais au lieu de spécifier theCLUSTEREDclause, nous spécifionsnonclustered. Nous pouvons également omettre complètement cette clause car un non-cluster est la valeur par défaut lors de la création d’un index.
Le TSQL ci-dessous montre un exemple de chaque instruction.
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
Qu’est-ce qu’un index de couverture
Un index de couverture est un index composé de toutes (ou plus) des columnsrequired pour satisfaire une requête en tant que colonnes clés de l’index. Lorsqu’un index couvrant peut être utilisé pour exécuter une requête, moins d’opérations d’E/S sont nécessaires car optimizerno longer doit effectuer des recherches supplémentaires pour récupérer les données de table réelles.
Voici un exemple de TSQL que vous pouvez utiliser pour créer un index de recouvrement sur la table de produits.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
La requête TSQL suivante peut maintenant être exécutée en accédant uniquement au nouvel index que nous venons de créer car toutes les colonnes de la requête font partie de l’index.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
Le plan d’explication suivant confirme qu’aucune recherche supplémentaire n’est requise pour cette requête.

Qu’est-ce qu’un index avec des colonnes incluses
Un index créé avec des colonnes incluses est un index non clusterisé qui inclut également des colonnes non clés dans les nœuds feuilles de l’index, similaire à un index clusterisé. Il y a quelques avantages à utiliser des colonnes incluses. Tout d’abord, il vous donne la possibilité d’inclure des types de colonnes qui ne sont pas autorisés en tant que clés d’index dans votre index. De plus, lorsque toutes les colonnes de votre requête sont une clé d’index ou une colonne incluse, la requête n’a plus besoin de faire une recherche supplémentaire afin d’obtenir toutes les données nécessaires pour satisfaire la requête, ce qui entraîne moins d’opérations sur le disque. Ceci est similaire à l’indice de couverture mentionné précédemment.
En utilisant le même exemple ci-dessus, le TSQL suivant créera le même index sauf avec la colonne ProductNumber référencée en tant que colonne incluse et non une colonne de clé d’index.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
En utilisant la même requête que ci-dessus, cela devrait également pouvoir s’exécuter sans nécessiter de recherches supplémentaires.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
Le plan followingEXPLAIN confirme qu’aucune recherche supplémentaire n’est également requise pour cette requête.

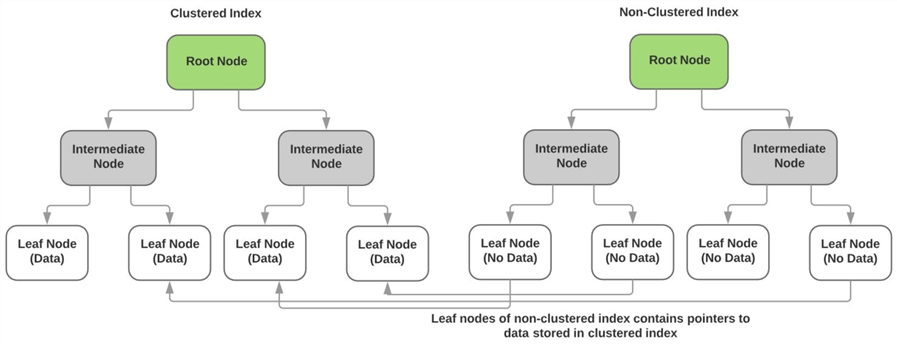
Index non groupésrelation à l’index groupé
Comme décrit ci-dessus, l’index groupé stocke les données réelles des colonnes non-clés dans les nœuds feuilles de l’index. Les nœuds feuilles de chaque index non clusteredindex ne contiennent aucune donnée et ont à la place des pointeurs vers la page de données réelle (ou nœud feuille) de l’index clusteredindex. Le diagramme ci-dessous illustre ce point.
Index filtrés
Qu’est-ce que c’est?
L’index filtré est un type d’index spécial où seule une certaine partie des lignes de la table sont indexées. Sur la base des critères de filtre appliqués lors de la création de l’index, seules les lignes restantes sont indexées, ce qui permet d’économiser de l’espace, d’améliorer les performances des requêtes et de réduire les frais de maintenance, car l’index est beaucoup plus petit.
Pourquoi l’utiliser?
Les index filtrés sont utiles lorsque vous créez des index sur des tables où il y a beaucoup de valeurs NULLES dans certaines colonnes ou certaines colonnes ont une cardinalité très faible et vous interrogez fréquemment une valeur basse fréquence.
Comment le créer ?
L’index Afiltered est créé simplement en ajoutant une clause WHERE à toute instruction de création non clusteredindex. Le TSQL suivant est un exemple de syntaxe pourcréer un index filtré.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
Confirmer l’utilisation de l’index
La requête suivante doit utiliser notre index nouvellement créé car il y a très peu de mots dans la table avec ShipDate NULL. Voici le TSQL.
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;