Cet article donne une introduction de l’index non clusterisé dans SQL Server à l’aide d’exemples.
Introduction
Dans un article précédent Aperçu des index en cluster SQL Server, nous avons exploré l’exigence d’un index et d’index en cluster dans SQL Server.
Avant de continuer, nous allons avoir un résumé rapide de l’index en cluster SQL Server:
- Il trie physiquement les données en fonction de la clé d’index en cluster
- Nous ne pouvons avoir qu’un seul index en cluster par table
- Une table sans index en cluster est un tas, et cela peut entraîner des problèmes de performances
- SQL Server crée automatiquement un index en cluster pour la colonne de clé primaire
- Un index en cluster est stocké dans format b-tree et contient les pages de données dans le nœud feuille, comme indiqué ci-dessous
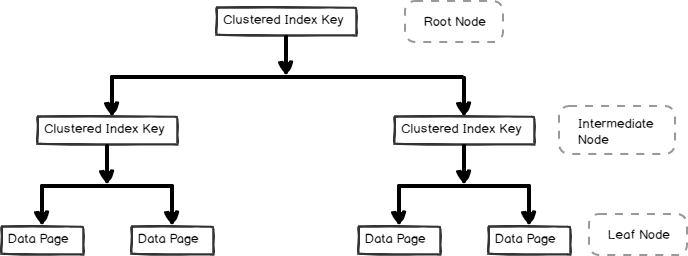
Index non en cluster sont également utiles pour les performances et l’optimisation des requêtes en fonction de la charge de travail des requêtes. Dans cet article, explorons l’index non clusterisé et ses éléments internes.
Aperçu de l’index non cluster dans SQL Server
Dans un index non cluster, le nœud feuille ne contient pas les données réelles. Il consiste en un pointeur vers les données réelles.
- Si la table contient un index en cluster, le nœud feuille pointe vers la page de données d’index en cluster qui se compose de données réelles
- Si la table est un tas (sans index en cluster), le nœud feuille pointe vers la page de tas
Dans l’image ci-dessous, nous pouvons regarder le niveau de feuille d’index non en cluster pointant vers la page de données dans l’index en cluster:
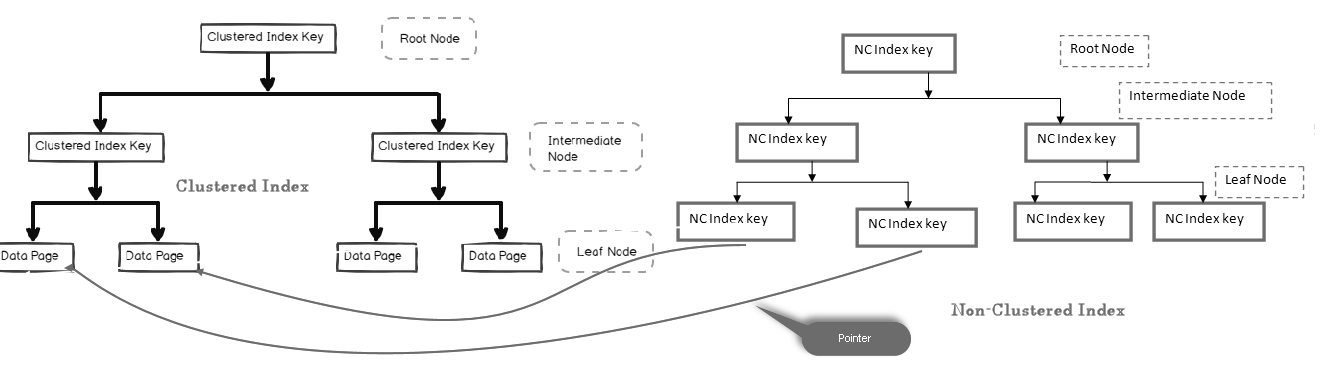
Nous pouvons avoir plusieurs index non clusterisés dans les tables SQL car il s’agit d’un index logique et ne trie pas physiquement les données par rapport à l’index clusterisé.
Comprenons l’index non clusterisé dans SQL Server à l’aide d’un exemple.
-
Créez une table d’employés sans index dessus
123456CRÉER UNE TABLE dbo.Employé(EmpID INT,EMpName VARCHAR(50),EmpAge INT,Numéro d’EMPCONTACT VARCHAR(10)); -
Insérez-y quelques enregistrements
123Insérer dans les valeurs des employés (1, ‘Raj’,32,8474563217)Insérer dans les valeurs des employés (2, ‘kusum’,30,9874563210)Insérer dans les valeurs des employés (3, ‘Akshita’,28,9632547120) -
Recherchez l’EmpID 2 et recherchez le plan d’exécution réel de celui-ci
1Sélectionnez * de l’employé où EmpID=2Il effectue une analyse de table car nous n’avons aucun index sur cette table:
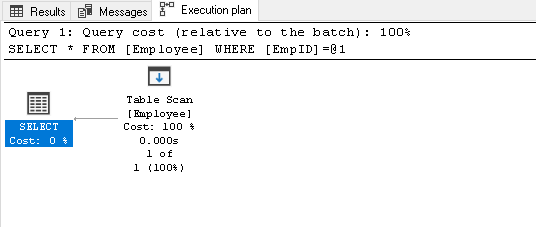
-
Créer un index clusterisé unique sur la colonne EmpID
1CRÉER UN INDEX CLUSTERED_EMPPLOYEE UNIQUE IX_Clustered_Empployee SUR dbo.Employé (EmpID); -
Recherchez l’EmpID 2 et recherchez le plan d’exécution réel de celui-ci
Dans ce plan d’exécution, nous pouvons remarquer que l’analyse de la table se transforme en recherche d’index en cluster:
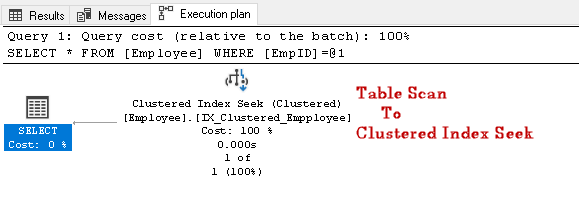
Exécutons une autre requête SQL pour rechercher un employé ayant un numéro de contact spécifique:
|
1
|
Sélectionnez * de l’employé où l’EmpContactNumber=’9874563210′
|
Nous n’avons pas d’index sur la colonne EmpContactNumber, donc Query Optimizer utilise l’index en cluster, mais il analyse l’index entier pour récupérer l’enregistrement:
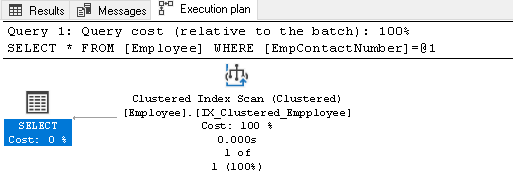
Cliquez avec le bouton droit sur le plan d’exécution et sélectionnez Afficher le plan d’exécution XML:
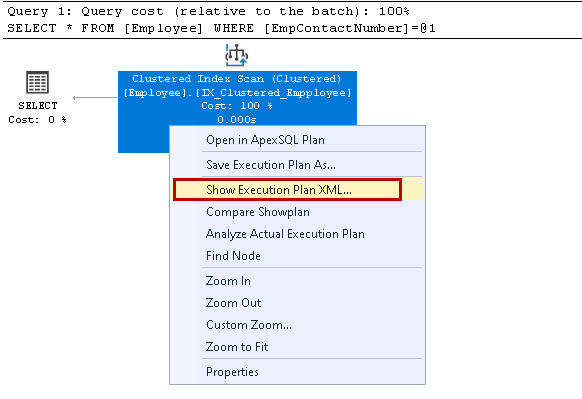
Il ouvre le plan d’exécution XML dans la nouvelle fenêtre de requête. Ici, nous remarquons qu’il utilise la clé d’index en cluster et lit les lignes individuelles pour récupérer le résultat:

Insérons quelques enregistrements supplémentaires dans la table des employés à l’aide du script suivant:
|
1
2
3
|
Insérer dans les valeurs des employés (4, ‘Manoj’,38,7892145637)
Insérer dans les valeurs des employés (5, ‘John’,33,7900654123)
Insérer dans les valeurs des employés (6, ‘Priya’,18,9603214569)
|
Nous avons les dossiers de six employés dans ce tableau. Maintenant, exécutez à nouveau l’instruction select pour récupérer les enregistrements des employés avec un numéro de contact spécifique:
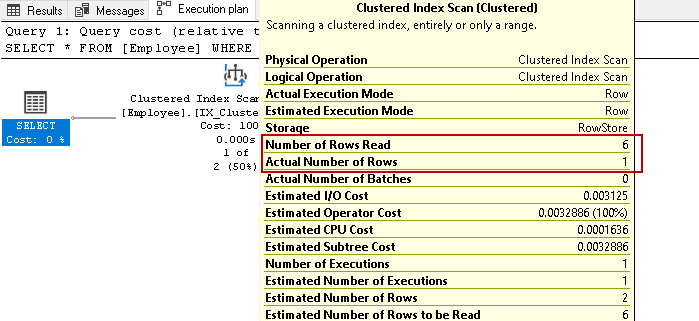
Il analyse à nouveau les six lignes pour le résultat en fonction de la condition spécifiée. Imaginez que nous ayons des millions d’enregistrements dans le tableau. Si SQL Server doit lire toutes les lignes de clés d’index, ce serait une tâche fastidieuse et fastidieuse.
Nous pouvons représenter l’index en cluster (pas la représentation réelle) dans le format de l’arbre B selon l’image suivante:

Dans la requête précédente, SQL Server lit la page du nœud racine et récupère chaque page et ligne de nœud feuille pour la récupération des données.
Créons maintenant un index unique non clusterisé dans SQL Server sur la table Employee de la colonne EmpContactNumber en tant que clé d’index:
|
1
|
CRÉEZ UN INDEX UNIQUE NON CLUSTERED_EMPLOYEE IX_NonClustered_Employee SUR dbo.Employé (Numéro de contact);
|
Avant d’expliquer cet index, réexécutez l’instruction SELECT et affichez le plan d’exécution réel:
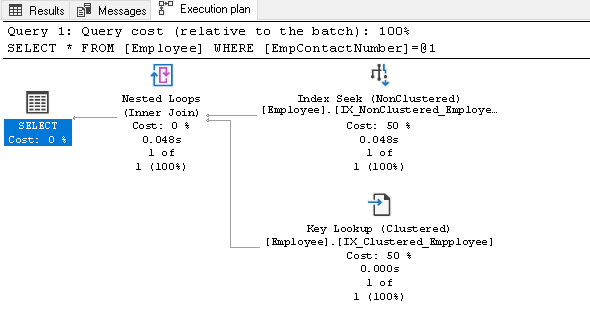
Dans ce plan d’exécution, nous pouvons voir deux composants:
- Recherche d’index (non groupée)
- Recherche de clé (Groupée)
Pour comprendre ces composants, nous devons examiner un index non clusterisé dans la conception de SQL Server. Ici, vous pouvez voir que le nœud feuille contient la clé d’index non en cluster (EmpContactNumber) et la clé d’index en cluster (EmpID):
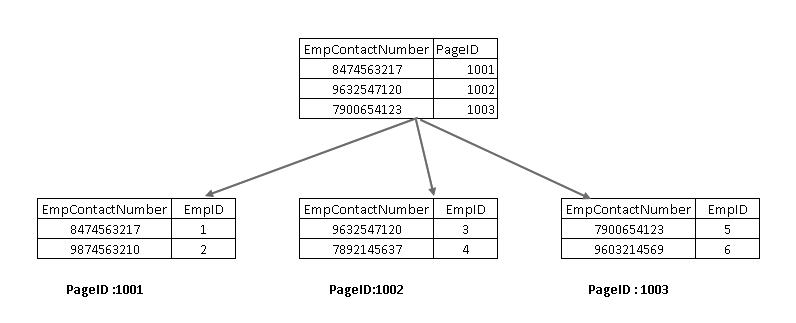
Maintenant, si vous réexécutez l’instruction SELECT, elle traverse à l’aide de la clé d’index non clusterisée et pointe vers une page avec une clé d’index clusterisée:
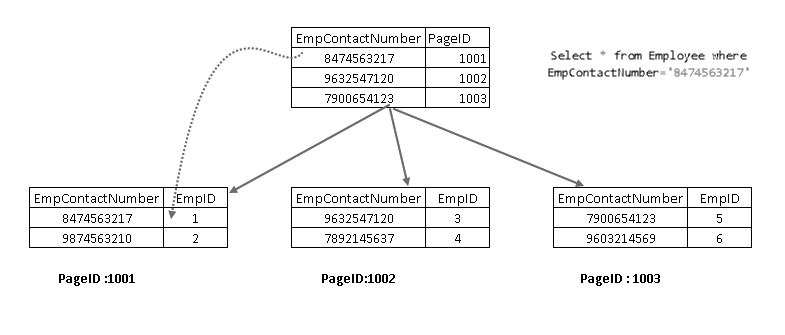
Elle montre qu’elle récupère l’enregistrement avec une combinaison de clé d’index en cluster et de clé d’index non en cluster. Vous pouvez voir la logique complète de l’instruction SELECT comme indiqué ci-dessous:
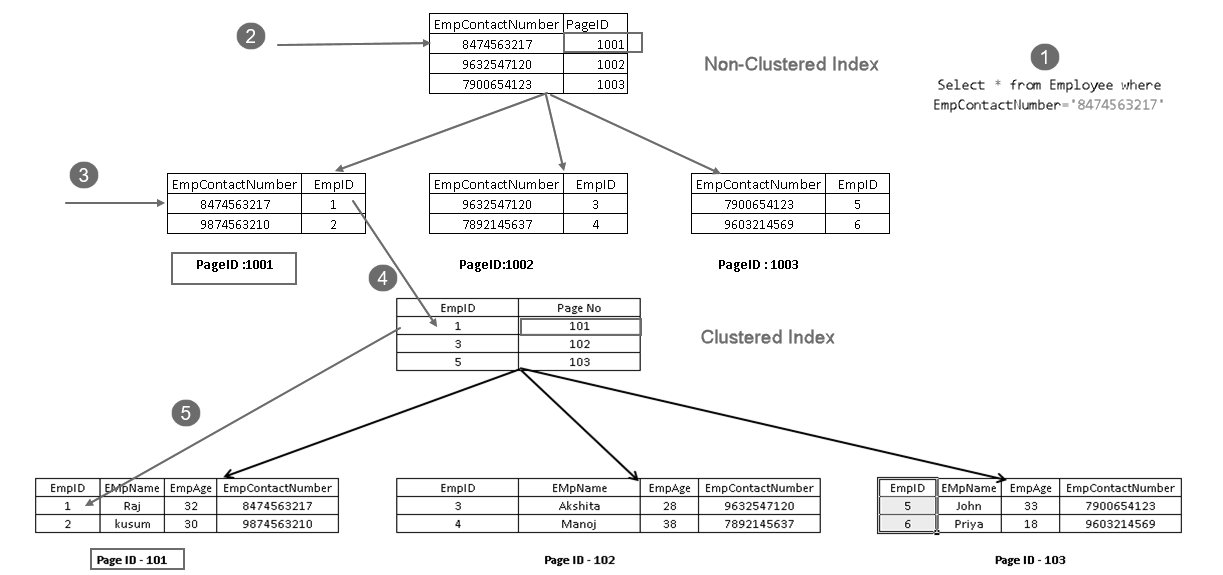
- Un utilisateur exécute une instruction select pour rechercher des enregistrements d’employés correspondant à un numéro de contact spécifié
- L’optimiseur de requêtes utilise une clé d’index non groupée et découvre le numéro de page 1001
- Cette page se compose d’une clé d’index groupée. Vous pouvez voir EmpID 1 dans l’image ci-dessus
- SQL Server découvre la page n ° 101 qui se compose d’enregistrements EmpID 1 en utilisant la clé d’index en cluster
- Il lit la ligne correspondante et renvoie la sortie à l’utilisateur
Précédemment, nous avons vu qu’il lit six lignes pour récupérer la ligne correspondante et renvoie une ligne dans la sortie. Regardons un plan d’exécution utilisant l’index non clusterisé:

Index non unique non clusterisé dans SQL Server
Nous pouvons avoir plusieurs index non clusterisés dans une table SQL. Auparavant, nous avons créé un index unique non clusterisé sur la colonne EmpContactNumber.
Avant de créer l’index, exécutez la requête suivante afin que nous ayons une valeur en double dans la colonne EmpAge:
|
1
2
3
|
Mettre à jour l’ensemble des employés EmpAge = 32 où EmpID = 2
Mettre à jour l’ensemble des employés EmpAge=38 où EmpID = 6
Mettre à jour l’ensemble des employés EmpAge=38 où EmpID=3
|
Exécutons la requête suivante pour un index non unique non clusterisé. Dans la syntaxe de la requête, nous ne spécifions pas de mot-clé unique et il indique à SQL Server de créer un index non unique:
|
1
|
CRÉER UN INDEX NCIX_Employee_EmpAge NON GROUPÉ SUR dbo.Employé (EmpAge);
|
Comme nous le savons, la clé d’un index doit être unique. Dans ce cas, nous voulons ajouter une clé non unique. La question se pose : Comment SQL Server rendra-t-il cette clé unique ?
SQL Server effectue les opérations suivantes:
- Il ajoute la clé d’index clusterisée dans les pages feuille et non feuille de l’index non-clusterisé non-unique
- Si la clé d’index clusterisée est également non-unique, il ajoute un uniquifieur de 4 octets de sorte que la clé d’index est unique
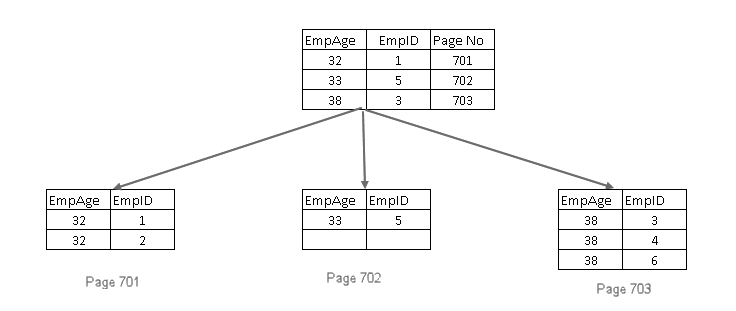
Inclure des colonnes non-clés dans l’index non-clusterisé dans SQL Server
Examinons à nouveau le plan d’exécution réel suivant de la requête suivante:
|
1
2
|
Sélectionnez * de l’employé
où Numéro de contact de l’EMP=’8474563217′
|
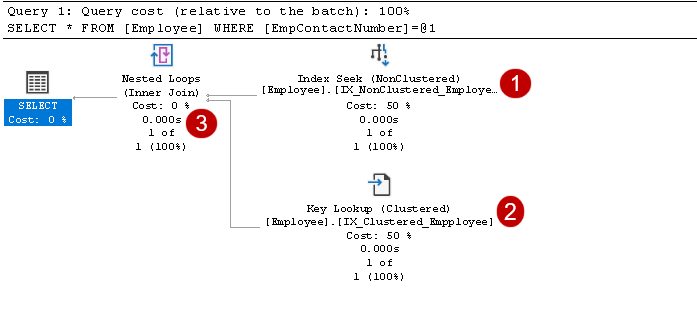
Il inclut des opérateurs de recherche d’index et de recherche de clés, comme indiqué dans l’image ci-dessus:
- L’indice cherche: L’optimiseur de requêtes SQL utilise une recherche d’index sur l’index non en cluster et récupère les colonnes EmpID, EmpContactNumber
-
Dans cette étape, l’optimiseur de requêtes utilise la recherche de clés sur l’index en cluster et récupère les valeurs des colonnes EmpName et EmpAge
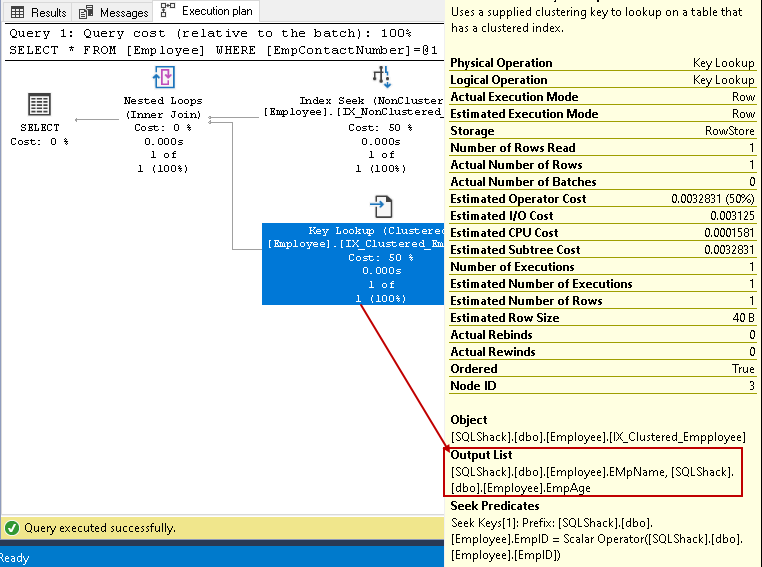
-
Dans cette étape, l’optimiseur de requêtes utilise les boucles imbriquées pour chaque ligne sortie de l’index non clusterisé pour la correspondance avec la ligne d’index clusterisé
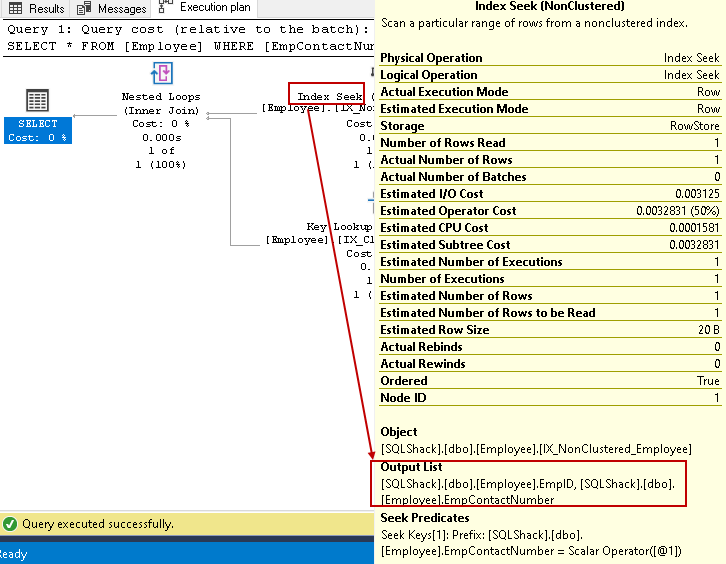
La boucle imbriquée peut être un opérateur coûteux pour les grandes tables. Nous pouvons réduire le coût en utilisant les colonnes non clés d’index non clusterisées. Nous spécifions la colonne non clé dans l’index non clusterisé à l’aide de la clause index.
Laissons tomber et créons l’index non clusterisé dans SQL Server en utilisant les colonnes incluses:
|
1
2
3
4
5
6
7
|
BAISSE DE L’INDEX.
ALLER
CRÉER UN INDEX UNIQUE NON REGROUPÉ SUR.
(
ASC
)
INCLURE (EmpName, EmpAge)
|
Les colonnes incluses font partie du nœud feuille d’un arbre d’index. Cela aide à récupérer les données de l’index lui-même au lieu de parcourir plus loin pour la récupération des données.
Dans l’image suivante, nous obtenons les deux colonnes incluses EmpName et EmpAge dans le cadre du nœud feuille:
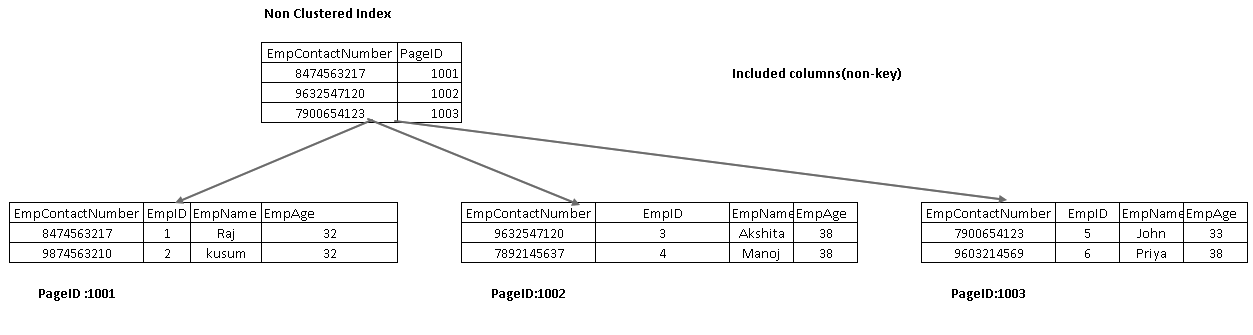
Ré-exécutez l’instruction SELECT et affichez maintenant le plan d’exécution réel. Nous n’avons pas de recherche de clé et de boucle imbriquée dans ce plan d’exécution:

Survolons la recherche d’index et affichons la liste des colonnes de sortie. SQL Server peut trouver toutes les colonnes à l’aide de cette recherche d’index non en cluster:
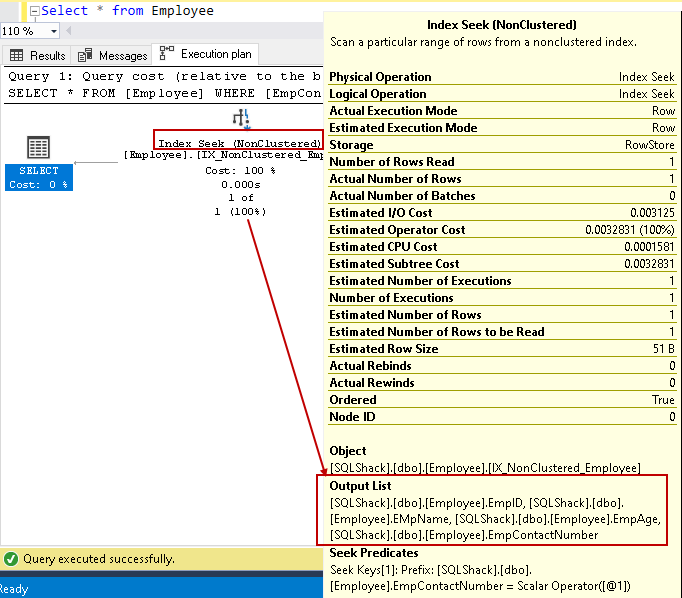
Nous pouvons améliorer les performances des requêtes en utilisant l’index de couverture à l’aide de colonnes non clés incluses. Cependant, cela ne signifie pas que nous devrions toutes les colonnes non clés dans la définition de l’index. Nous devons être prudents dans la conception de l’index et tester le comportement de l’index avant le déploiement dans l’environnement de production.
Conclusion
Dans cet article, nous avons exploré l’index non clusterisé dans SQL Server et son utilisation en combinaison avec l’index clusterisé. Nous devons soigneusement concevoir l’index en fonction du comportement de la charge de travail et de la requête.
- Auteur
- Messages récents

Il est le créateur de l’une des plus grandes collections en ligne gratuites d’articles sur un seul sujet, avec sa série de 50 parties sur SQL Server Always On Availability Groups. Sur la base de sa contribution à la communauté SQL Server, il a été récompensé par divers prix dont le prestigieux « Meilleur auteur de l’année » en 2020 et 2021 à SQLShack.
Raj est toujours intéressé par les nouveaux défis, donc si vous avez besoin d’aide sur n’importe quel sujet couvert dans ses écrits, il peut être joint à rajendra.gupta 16 @ gmail.com
Voir tous les messages de Rajendra Gupta
- Utiliser des modèles ARM pour déployer des instances de conteneur Azure avec des images Linux SQL Server – 21 décembre 2021
- Accès bureau à distance pour AWS RDS SQL Server avec Amazon RDS Custom – 14 décembre 2021
- Stocker des fichiers SQL Server dans un stockage Persistant pour les instances de conteneur Azure – Décembre 10, 2021