Di: Ben Snaidero
Panoramica
In questa sezione tratteremo le cose che dovete sapere sugli indici non in cluster.
Che cos’è un indice non cluster
Un indice non cluster (o indice b-tree regolare) è un indice in cui l’ordine delle righe non corrisponde all’ordine fisico dei dati effettivi. È invece ordinato dalle colonne che compongono l’indice. In un indice non cluster, le pagine a foglio dell’indice non contengono dati effettivi, ma contengono invece puntatori per i dati effettivi. Questi puntatori punterebbero alla pagina dei dati dell’indice cluster in cui esistono i dati effettivi (o alla pagina heap se non esiste un indice cluster sulla tabella).
Perché creare indici non cluster
Il vantaggio principale di avere un indice non cluster su una tabella è che fornisce fastaccess ai dati. L’indice consente al motore di database di individuare rapidamente i datisenza dover eseguire la scansione dell’intera tabella. Poiché una tabella diventa più grande, è molto importante che gli indici corretti vengano aggiunti alla tabella, poiché senza le prestazioni della query di anyindexes diminuirà drasticamente.
Quando dovrebbero essere creati indici non cluster
Ci sono due casi in cui avere un indice non cluster su una tabella è vantaggioso. Innanzitutto, quando è presente più di un set di colonne utilizzate nelle query WHERE clauseof che accedono alla tabella. Un secondo indice (supponendo che ci sia già un indice cluster sulla colonna della chiave primaria) accelera i tempi di esecuzione e reduceIO per le altre query. In secondo luogo, se le tue query richiedono frequentemente che i dati vengano restituiti in un determinato ordine, avere un indice su queste colonne può ridurre l’importo della CPU e della memoria richiesta poiché non sarà necessario eseguire un ordinamento aggiuntivo poiché i dati nell’indice sono già ordinati.
L’esempio seguente mostra che non è necessaria alcuna scansione della tabella per recuperare i dati, solo una ricerca dell’indice non clusteredindex e una ricerca dell’indice clustered per ottenere i dati. Inoltre, si noti chenessuna sorta è richiesta in quanto i dati sono già nell’ordine corretto.
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

Come creare un indice non cluster
La creazione di un indice non cluster è fondamentalmente la stessa della creazione di un indice cluster,ma invece di specificare theCLUSTEREDclause specifichiamo Unclustered. Possiamo anche omettere questa clausola del tutto come un non-cluster è l’impostazione predefinita durante la creazioneun indice.
Il TSQL qui sotto mostra un esempio di ogni istruzione.
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
Che cos’è un indice di copertura
L’indice di copertura è un indice costituito da tutte (o più) le colonne richieste per soddisfare una query come colonne chiave dell’indice. Quando un indice di copertura può essere utilizzato per eseguire una query, sono necessarie meno operazioni IO poiché optimizerno deve più eseguire ricerche aggiuntive per recuperare i dati della tabella effettiva.
Di seguito è riportato un esempio del TSQL che è possibile utilizzare per creare un indice di copertura sulla tabella dei prodotti.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
La seguente query TSQL può ora essere eseguita accedendo solo al nuovo indexwe appena creato poiché tutte le colonne della query fanno parte dell’indice.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
Il piano followingEXPLAIN conferma che non è richiesta alcuna ricerca aggiuntiva per questa query.

Che cos’è un indice con colonne incluse
Un indice creato con colonne incluse è un indice non cluster che include anchecolonne non chiave nei nodi foglia dell’indice, simile a un indice cluster. Ci sono un paio di vantaggi nell’utilizzo delle colonne incluse. Per prima cosa ti dà la possibilità di includere tipi di colonne che non sono consentiti come chiavi di indice nel tuo indice. Inoltre, quando tutte le colonne nella query sono una chiave di indice o una colonna inclusa, la query non deve più eseguire una ricerca aggiuntiva per ottenere tutti i dati necessari per soddisfare la query che si traduce in un minor numero di operazioni su disco. Questo è simile all’indice di copertura menzionato in precedenza.
Utilizzando lo stesso examplefrom sopra il seguente TSQL creerà lo stesso indice tranne che con ProductNumber columnreferenced come colonna inclusa e non come colonna della chiave di indice.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
Utilizzando la stessa query di cui sopra, questo dovrebbe anche essere in grado di eseguire senza richiedere ulteriori ricerche.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
Il piano followingEXPLAIN conferma che non è richiesta alcuna ricerca aggiuntiva per questa query.

Non-clustered indexesrelation to clustered index
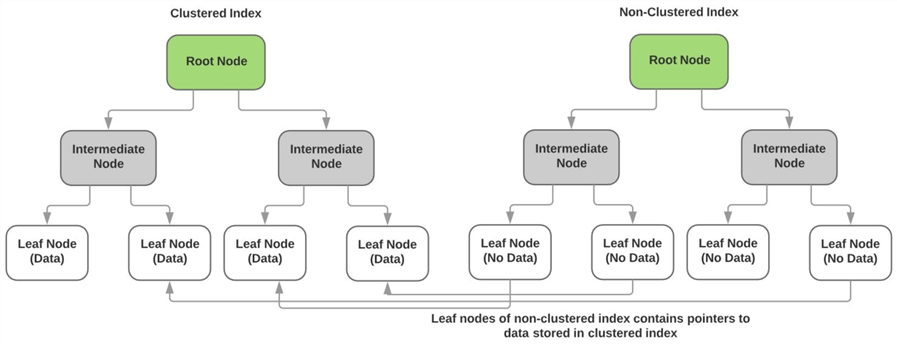
Come descritto sopra, l’indice clustered memorizza i dati effettivi dei non-keycolumns nei nodi foglia dell’indice. I nodi foglia di ogni non-clusteredindex non contengono dati e hanno invece puntatori alla pagina dati effettiva (o nodo foglia) dell’indice cluster. Lo schema seguente illustra questopunto.
Indici filtrati
Che cos’è?
Afiltered index è un tipo di indice speciale in cui viene indicizzata solo una certa parte delle righe della tabella. In base ai criteri di filtro applicati quando viene creato l’indice,vengono indicizzate solo le righe rimanenti che possono risparmiare spazio, migliorare le prestazioni delle query e ridurre il sovraccarico di manutenzione poiché l’indice è molto più piccolo.
Perché usarlo?
Gli indici filtrati sono utili quando si creano indici su tabelle in cui ci sono molti valori NULLI in determinate colonne o alcune colonne hanno una cardinalità molto bassa e si sta spesso interrogando un valore a bassa frequenza.
Come crearlo?
L’indice Afiltered viene creato semplicemente aggiungendo una clausola WHERE a qualsiasi istruzione di creazione non clusteredindex. Il seguente TSQL è un esempio della sintassi percreare un indice filtrato.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
Conferma l’utilizzo dell’indice
La seguente query dovrebbe utilizzare il nostro indice appena creato in quanto ci sono pochissimi wrecords nella tabella con ShipDate NULL. Ecco il TSQL.
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;