Questo articolo fornisce un’introduzione dell’indice non cluster in SQL Server utilizzando esempi.
Introduzione
In un precedente articolo Panoramica degli indici in cluster di SQL Server, abbiamo esplorato il requisito di un indice e indici in cluster in SQL Server.
Prima di procedere, facciamo un breve riassunto dell’indice cluster di SQL Server:
- fisicamente ordina i dati in base all’indice cluster tasto
- Possiamo avere solo un indice cluster, secondo la tabella
- di una tabella senza Un indice cluster è un heap, e potrebbe portare a problemi di prestazioni
- SQL Server crea automaticamente un indice cluster per la colonna chiave primaria
- Un indice cluster è memorizzato in un b-albero di formato e contiene i dati di pagine nel nodo foglia, come mostrato di seguito
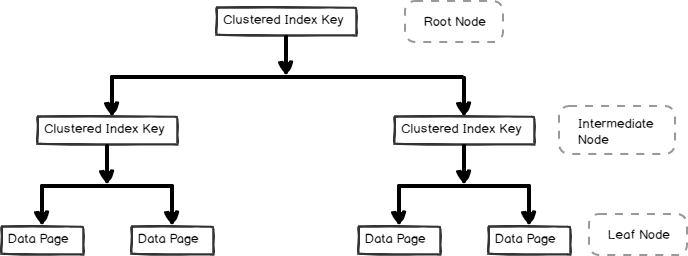
indici Non Cluster sono anche utili per le prestazioni e l’ottimizzazione delle query in base al carico di lavoro delle query. In questo articolo, esploriamo l’indice non cluster e i suoi interni.
Panoramica dell’indice non cluster in SQL Server
In un indice non cluster, il nodo leaf non contiene i dati effettivi. Consiste in un puntatore ai dati effettivi.
- Se la tabella contiene un indice cluster, nodo foglia punti per l’indice cluster pagina di dati che consiste di dati effettivi
- Se la tabella è un heap (senza un indice cluster), nodo foglia punti per l’heap di pagina
Nell’immagine qui sotto, siamo in grado di guardare al livello foglia dell’indice non cluster di puntamento verso la pagina di dati nell’indice non cluster:
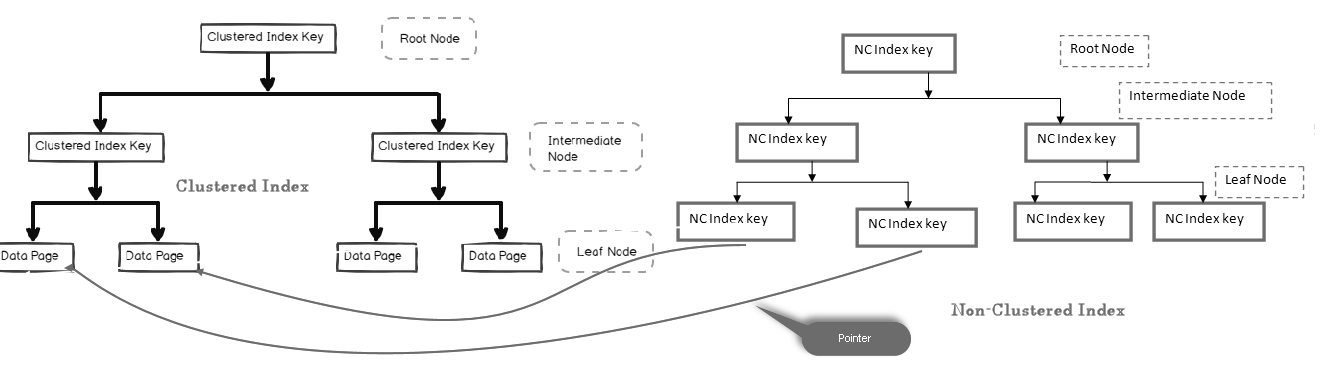
Possiamo avere più indici non cluster nelle tabelle SQL perché è un indice logico e non ordina fisicamente i dati rispetto all’indice cluster.
Comprendiamo l’indice non cluster in SQL Server utilizzando un esempio.
-
Creare una tabella Dipendente, senza alcun indice
123456CREATE TABLE dbo.Employee(EmpID INT,EMpName VARCHAR(50),EmpAge INT,EmpContactNumber VARCHAR(10)); -
Inserire qualche record
123Insert into Impiegato values(1,’Raj’,32,8474563217)Insert into Impiegato values(2,’kusum’,30,9874563210)Insert into Impiegato values(3,’Akshita’,28,9632547120) -
Ricerca per il EmpID 2 e look per l’effettiva esecuzione del piano di
1Select * from Impiegato where EmpID=2fa una scansione della tabella, perché non abbiamo alcun indice in questa tabella:
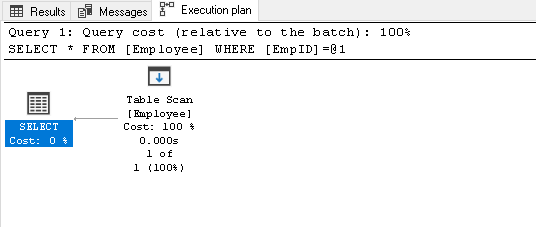
-
Creare un indice cluster univoco nella colonna EmpID
1CREARE un INDICE CLUSTER UNIVOCO IX_Clustered_Empployee SU dbo.Dipendente (EmpID); -
Ricerca per il EmpID 2 e look per l’effettiva esecuzione del piano di
In questo piano di esecuzione, si può notare che la scansione della tabella variazioni di un indice cluster cercare:
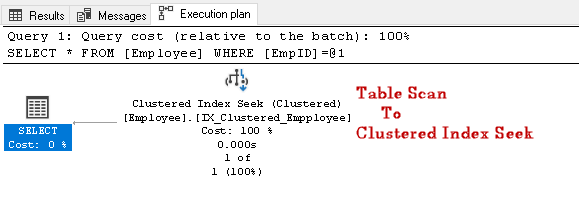
proviamo a eseguire un’altra query SQL per la ricerca Impiegato avere un contatto specifico numero:
|
1
|
Select * from Impiegato where EmpContactNumber=’9874563210′
|
non Abbiamo un indice di EmpContactNumber colonna, pertanto Query Optimizer utilizza l’indice cluster, ma si analizza l’intero indice per recuperare il record:
fare clic con il piano di esecuzione e selezionare Mostra l’Esecuzione del Piano di XML:
Apre il piano di esecuzione XML nella finestra nuova query. Qui, notiamo che utilizza la chiave di indice in cluster e legge le singole righe per recuperare il risultato:

Inseriamo alcuni altri record nella tabella Employee usando il seguente script:
|
1
2
3
|
Insert into Impiegato values(4,’Manoj’,38,7892145637)
Insert into Impiegato values(5,’Giovanni’,33,7900654123)
Insert into Impiegato values(6,’Priya’,18,9603214569)
|
Abbiamo sei dipendenti record in questa tabella. Ora, eseguire nuovamente l’istruzione select per recuperare i record dei dipendenti con un numero di contatto specifico:
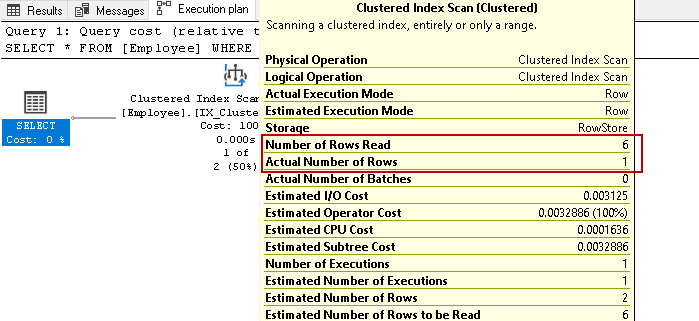
Esegue nuovamente la scansione di tutte e sei le righe per il risultato in base alla condizione specificata. Immagina di avere milioni di record nella tabella. Se SQL Server deve leggere tutte le righe delle chiavi di indice, sarebbe un’attività che richiede tempo e risorse.
Possiamo rappresentare l’indice cluster (non la rappresentazione effettiva) nel formato B-tree come da immagine seguente:

Nella query precedente, SQL Server legge la pagina del nodo radice e recupera ogni pagina e riga del nodo foglia per il recupero dei dati.
Ora creiamo un indice univoco non cluster in SQL Server sulla tabella Employ nella colonna EmpContactNumber come chiave di indice:
|
1
|
CREARE UNICO INDICE NON CLUSTER IX_NonClustered_Employee SU dbo.Dipendente (EmpContactNumber);
|
Prima di spiegare questo indice, eseguire nuovamente l’istruzione SELECT e vista l’attuale piano di esecuzione:
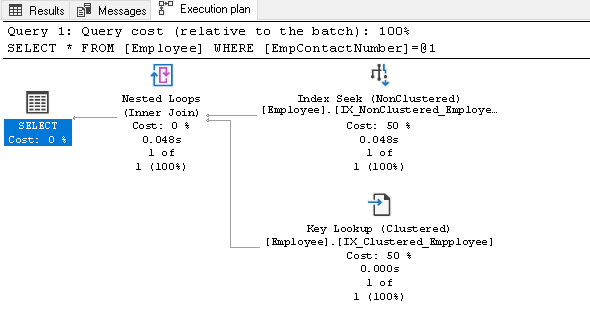
In questo piano di esecuzione, si possono vedere due componenti:
- Indice di ricerca (non cluster)
- Chiave di Ricerca (di Cluster)
Per comprendere queste componenti, abbiamo bisogno di guardare un indice non cluster di SQL Server di design. Qui, si può vedere che il nodo foglia contiene la chiave di indice non cluster (EmpContactNumber) e la chiave di indice cluster (EmpID):
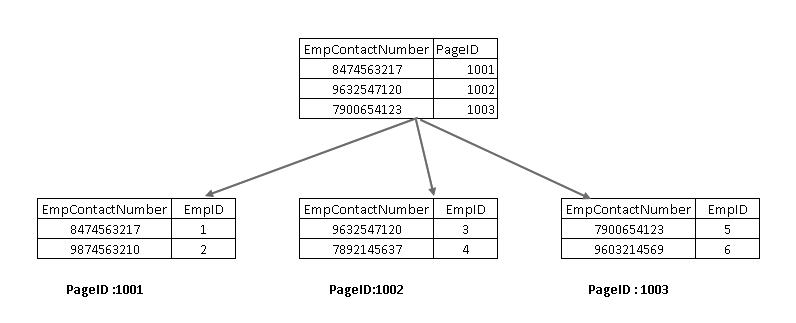
Ora, se eseguire nuovamente l’istruzione SELECT, attraversa utilizzando la chiave di indice non cluster e punta ad una pagina con la chiave di indice cluster:
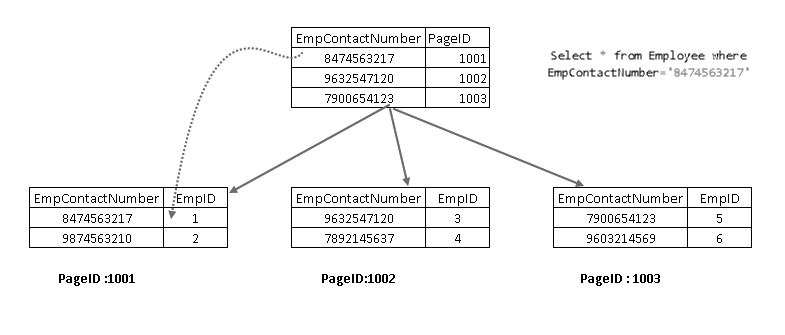
mostra che recupera il record con una combinazione di indice cluster chiave e chiave di indice non cluster. Si può vedere la logica completo per l’istruzione SELECT, come illustrato di seguito:
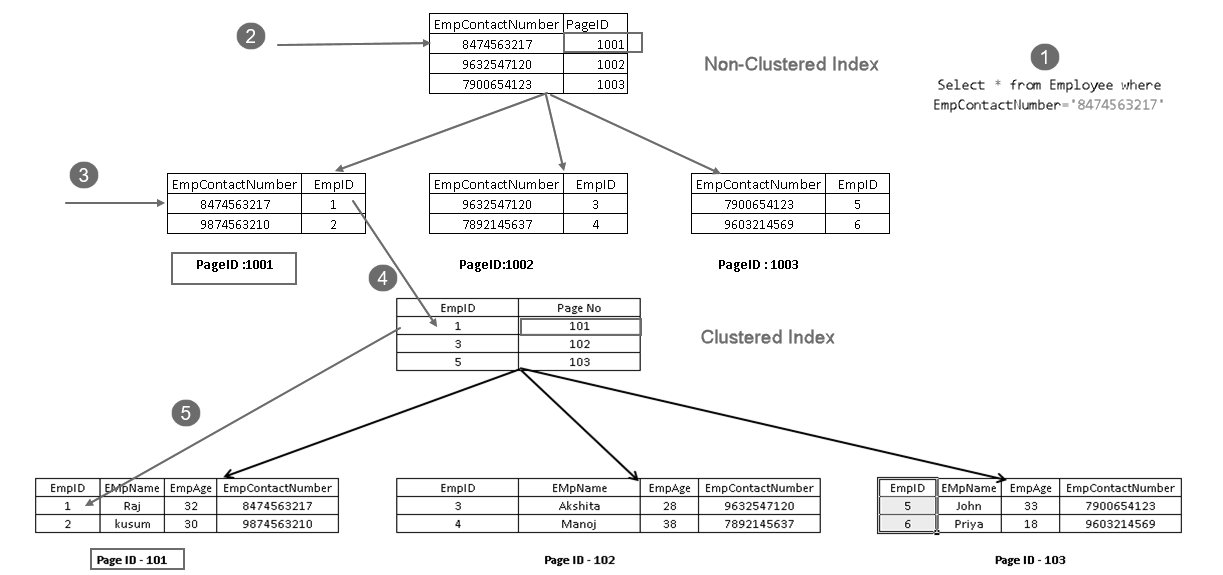
- Un utente esegue un’istruzione select per trovare i record dei dipendenti di corrispondenza con un determinato numero di contatto
- Query Optimizer utilizza una chiave di indice non cluster, e trova il numero di pagina 1001
- Questa pagina è composta da una chiave di indice cluster. Si può vedere EmpID 1 nell’immagine sopra
- SQL Server scopre pagina n. 101, che consiste di un EmpID 1 record utilizzando la chiave di indice cluster
- legge la riga corrispondente e restituisce l’output per l’utente
in Precedenza, abbiamo visto che la legge sei righe per recuperare la riga corrispondente e restituisce una riga in uscita. Diamo un’occhiata a un piano di esecuzione utilizzando l’indice non cluster:

Indice non univoco non cluster in SQL Server
Possiamo avere più indici non cluster in una tabella SQL. In precedenza, è stato creato un indice non cluster univoco nella colonna EmpContactNumber.
Prima di creare l’indice, eseguire la seguente query in modo da avere un valore duplicato nella colonna EmpAge:
|
1
2
3
|
Update Impiegato set EmpAge=32 dove EmpID=2
Update Impiegato set EmpAge=38, dove EmpID=6
Update Impiegato set EmpAge=38, dove EmpID=3
|
proviamo a eseguire la query seguente per una non univoca indice non cluster. Nella sintassi della query, non specifichiamo una parola chiave univoca e indica a SQL Server di creare un indice non univoco:
|
1
|
CREA INDICE NON CLUSTER NCIX_Employee_EmpAge SU dbo.Dipendente (EmpAge);
|
Come sappiamo, la chiave di un indice dovrebbe essere unica. In questo caso, vogliamo aggiungere una chiave non univoca. La domanda sorge spontanea: in che modo SQL Server renderà questa chiave unica?
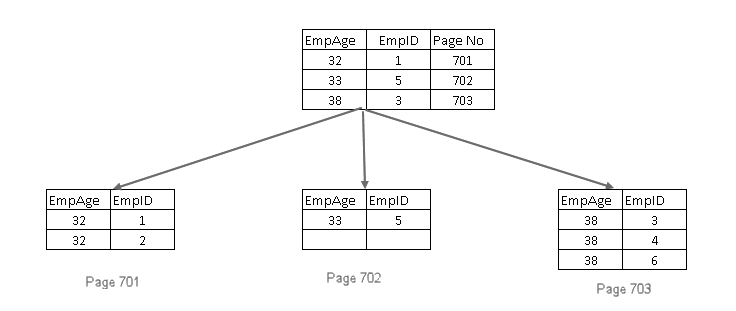
SQL Server esegue le seguenti operazioni:
- aggiunge la chiave di indice cluster in foglia e foglia non pagine di il non univoco indice non cluster
- Se la chiave di indice cluster non è unica, si aggiunge un 4 byte uniquifier in modo che l’indice chiave è unica
Includere colonne non chiave nell’indice non cluster di SQL Server
diamo un’occhiata al il seguente piano di esecuzione effettivo di nuovo la query riportata di seguito:
|
1
2
|
Select * from Dipendenti
dove EmpContactNumber=’8474563217′
|
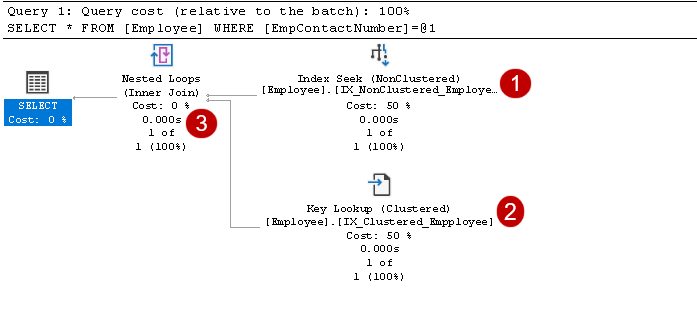
include indice di ricerca e di ricerca della chiave di operatori, come mostrato nell’immagine sopra:
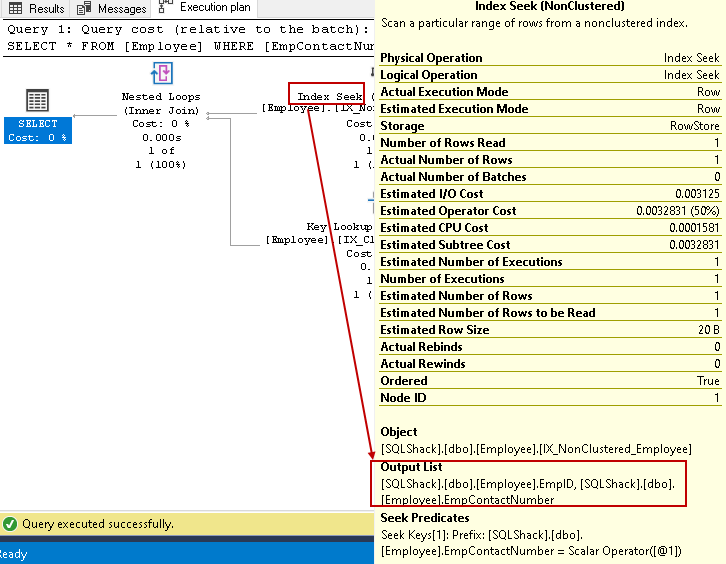
- L’indice mira: Query Optimizer di SQL utilizza la ricerca di un indice non cluster indice e recupera EmpID, EmpContactNumber colonne
-
In questo passaggio, Query Optimizer utilizza la ricerca della chiave di indice cluster e recupera i valori per EmpName e EmpAge colonne
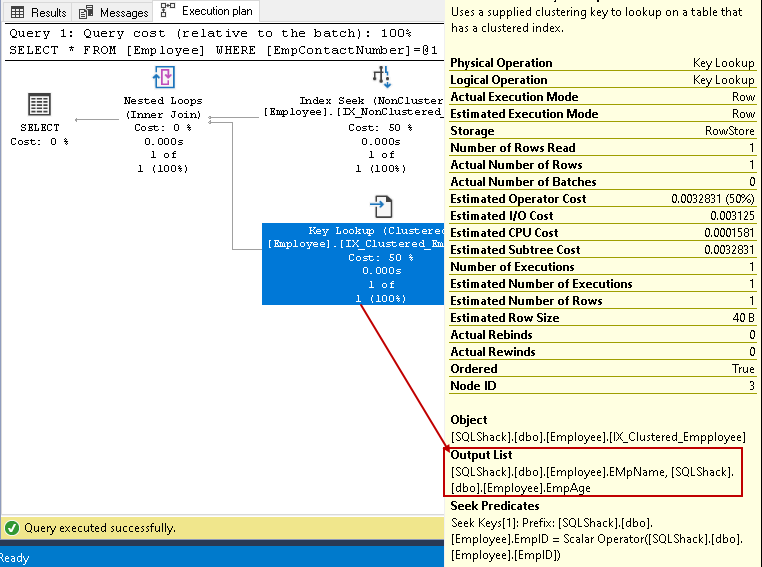
-
In questo passaggio, Query Optimizer utilizza i cicli nidificati per ogni riga di output dall’indice non cluster per la corrispondenza con l’indice cluster riga
Il ciclo nidificato potrebbe essere un operatore costoso per tabelle di grandi dimensioni. Possiamo ridurre il costo utilizzando le colonne non chiave dell’indice non cluster. Specifichiamo la colonna non chiave nell’indice non cluster utilizzando la clausola index.
Lasciate perdere e creato l’indice non cluster di SQL Server utilizzando le colonne incluse:
|
1
2
3
4
5
6
7
|
GOCCIA INDICE .
VAI
CREA UN INDICE NON CLUSTER UNIVOCO SU .
(
ASC
)
INCLUDE (EmpName, EmpAge)
|
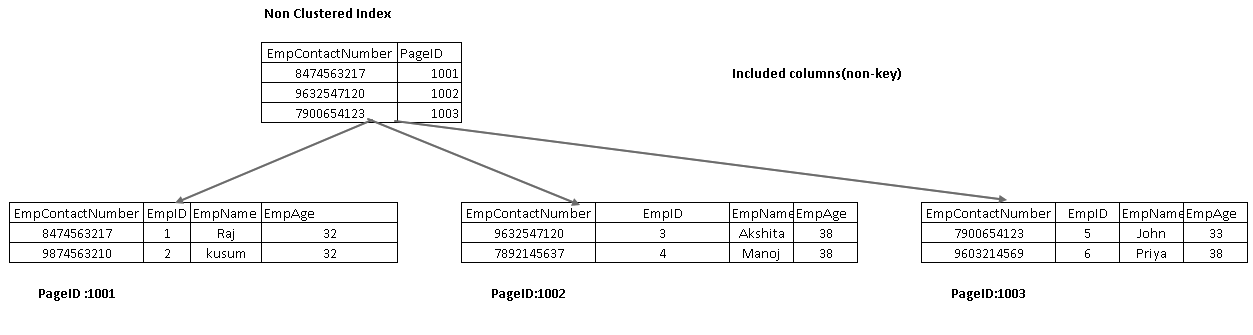
Le colonne incluse fanno parte del nodo foglia in un albero indice. Aiuta a recuperare i dati dall’indice stesso invece di attraversare ulteriormente per il recupero dei dati.
Nell’immagine seguente, otteniamo entrambe le colonne EmpName e EmpAge inclusi come parte del nodo foglia:
Rieseguire l’istruzione SELECT e visualizzare ora il piano di esecuzione effettivo. Non abbiamo ricerca chiave e ciclo nidificato in questo piano di esecuzione:

Passiamo il cursore sopra la ricerca dell’indice e visualizziamo l’elenco delle colonne di output. SQL Server può trovare tutte le colonne utilizzando questa ricerca di indici non in cluster:
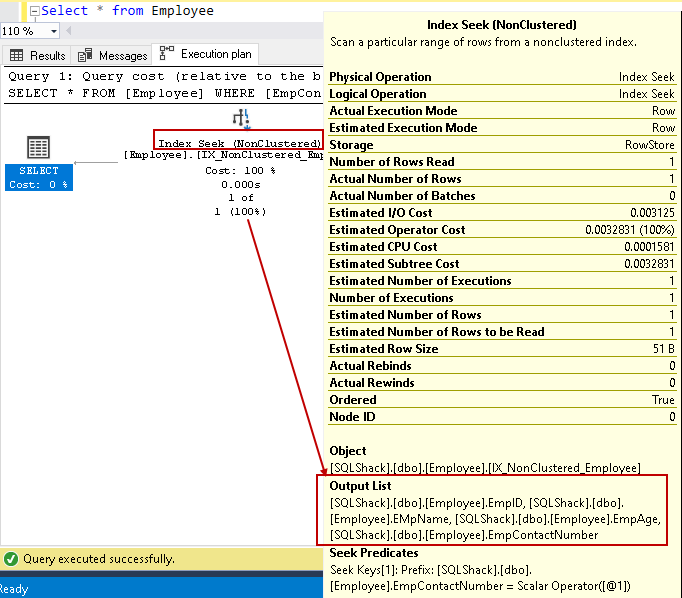
Possiamo migliorare le prestazioni delle query utilizzando l’indice di copertura con l’aiuto di colonne non chiave incluse. Tuttavia, ciò non significa che dovremmo tutte le colonne non chiave nella definizione dell’indice. Dovremmo fare attenzione nella progettazione dell’indice e testare il comportamento dell’indice prima della distribuzione nell’ambiente di produzione.
Conclusione
In questo articolo, abbiamo esplorato l’indice non cluster in SQL Server e il suo utilizzo in combinazione con l’indice cluster. Dovremmo progettare attentamente l’indice in base al carico di lavoro e al comportamento della query.
- Autore
- Post Recenti

È il creatore di una delle più grandi collezioni online gratuite di articoli su un singolo argomento, con la sua serie di 50 parti su SQL Server Always On Availability Groups. Sulla base del suo contributo alla comunità SQL Server, è stato riconosciuto con vari premi tra cui il prestigioso “Best author of the year” ininterrottamente nel 2020 e 2021 a SQLShack.
Raj è sempre interessato a nuove sfide, quindi se hai bisogno di consulenza su qualsiasi argomento trattato nei suoi scritti, può essere raggiunto a rajendra.gupta16 @ gmail.com
Visualizza tutti i messaggi di Rajendra Gupta
- Utilizzare il BRACCIO di modelli per distribuire Azure contenitore di istanze di SQL Server Linux immagini – 21 dicembre, 2021
- accesso Remoto al desktop per AWS RDS SQL Server con Amazon RDS Personalizzato – dicembre 14, 2021
- Memorizzare i file di SQL Server Persistente di Archiviazione di Azure Contenitore di Istanze di dicembre 10, 2021