By:Ben Snaidero
概要
このセクションでは、非クラスタ化インデックスについて知っておく必要があることを説明します。
非クラスタ化インデックスとは
非クラスタ化インデックス(または通常のbツリーインデックス)は、行の順序が実際のデータの物理的な順序と一致しない これは、インデックスを構成する列によって順序付けされています。 クラスター化されていないインデックスでは、インデックスのリーフページには実際のデータは含まれず、代わりに実際のデータのポイントが含まれます。 これらのポインターは、実際のデータが存在するクラスタ化インデックスdatapage(またはテーブルにクラスタ化インデックスが存在しない場合はヒープページ)を指
非クラスタ化インデックスを作成する理由
非クラスタ化インデックスをテーブルに持つ主な利点は、データへのfastaccessを提供することです。 インデックスを使用すると、データベースエンジンはテーブル全体をスキャンすることなくデータを迅速に検索できます。 テーブルが大きくなるにつれて、anyindexesクエリのパフォーマンスが劇的に低下するため、正しいインデックスがテーブルに追加されることが非常に重要です。
非クラスタ化インデックスを作成する必要がある場合
テーブルに非クラスタ化インデックスを持つことが有益な場合が二つあります。 まず、テーブルにアクセスするWHERE clauseofクエリで使用される列のセットが複数ある場合。 第二のインデックス(主キー列に既にクラスタ化されたインデックスがあると仮定)は、実行時間を短縮し、他のクエリのreduceIOを削減します。 第二に、クエリで頻繁にdatatoが特定の順序で返される必要がある場合、これらの列にインデックスを持つことで、インデックス内のデータがすでに順序付けされているため、追加の並べ替えを行う必要がないため、必要なCPUとメモリの量を減らすことができます。
次の例では、データをフェッチするためにテーブルスキャンは必要なく、非clusteredindexのインデックスシークと、データを取得するためのクラスター化インデックスの また、データがすでに正しい順序になっているため、ソートは必要ありません。
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

非クラスタ化インデックスの作成方法
非クラスタ化インデックスの作成は、基本的にクラスタ化インデックスの作成と同じですが、clusteredclauseを指定するのではなく、nonclusteredを指定します。 また、インデックスを作成するときには、非クラスタ化がデフォルトであるため、この句を完全に省略することもできます。
以下のTSQLは、各ステートメントの例を示しています。
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
covering indexとは
Acovering indexは、インデックスのキー列としてクエリを満たすために必要な列のすべて(またはそれ以上)で構成されるインデックスです。 カバーインデックスを使用してクエリを実行できる場合、optimizernoは実際のテーブルデータを取得するために余分なルックアップを実行する必要があるため、必要なIO操作が少なくなります。
以下は、Productテーブルにacoveringインデックスを作成するために使用できるTSQLの例です。
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
次のTSQLクエリは、クエリ内のすべての列がインデックスの一部であるため、作成したばかりの新しいindexweにアクセスするだけで実行できます。
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
followingEXPLAINプランは、このクエリに必要な追加の参照がないことを確認します。

included columnsを持つインデックスとは
included columnsを持つインデックスは、クラスター化インデックスと同様に、インデックスのリーフノードに非キー列も含まれる非クラスター化インデックスです。 インクルードされた列を使用することには、いくつかの利点があります。 まず、yourindexにインデックスキーとして許可されていない列型を含める機能が提供されます。 また、クエリ内のすべての列がインデックスキーまたは挿入された列のいずれかである場合、クエリを満たすために必要なすべてのデータを取得するた これは前述のカバー指数に似ています。
次のTSQLの上の同じ例を使用すると、ProductNumber columnreferencedがインデックスキー列ではなくインクルード列として参照されている以外は、同じインデックスが作成されます。
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
上記と同じクエリを使用すると、余分なルックアップを必要とせずに実行することもできます。
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
followingEXPLAINプランでは、このクエリにも追加の参照が必要ないことが確認されています。

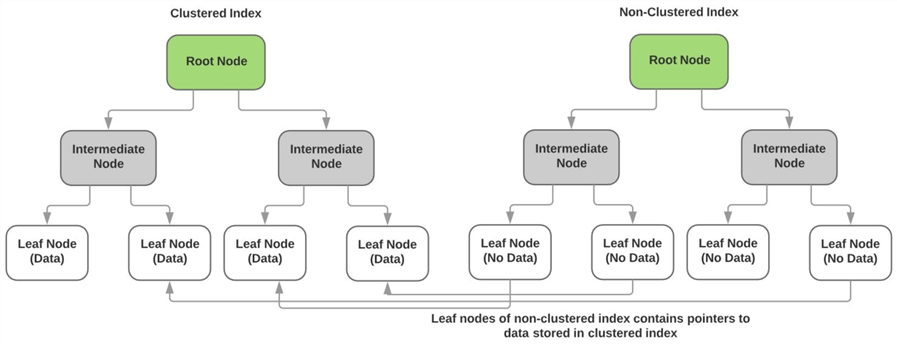
非クラスター化インデックスクラスター化インデックスとの関係
上記のように、クラスター化インデックスは、非keycolumnsの実際のデータをインデックスのリーフノードに格納します。 各非clusteredindexのリーフノードにはデータが含まれておらず、代わりにクラスター化インデックスの実際のデータページ(またはリーフノード)へのポインターがあります。 以下の図は、この点を示しています。
フィルタリングされたインデックス
それは何ですか?
Afiltered indexは、テーブルの行の特定の部分のみが索引付けされる特殊な索引タイプです。 インデックスが作成されたときに適用されるフィルタ基準に基づいて、残りの行のみがインデックス化され、スペースを節約し、クエリのパフォーマンスを向上させ、インデックスがmuchsmallerであるため、メンテナンスのオーバーヘッドを削減できます。
なぜそれを使うのですか?
フィルター処理されたインデックスは、特定の列に多くのNULL値があるテーブルや、特定の列の基数が非常に低いテーブルにインデックスを作成し、低頻度の値を頻繁に照会する場合に便利です。
どのようにそれを作成するには?
Afiltered indexは、clusteredindex以外の作成ステートメントにWHERE句を追加するだけで作成されます。 次のTSQLは、フィルター処理されたインデックスを作成する構文の例です。
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
インデックス使用の確認
次のクエリは、ShipDate NULLのテーブルには非常に少ないレコードがあるため、新しく作成されたインデックスを使用する必要があります。 ここにTSQLがあります。
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;