この記事では、例を使用して、SQL Serverの非クラスタ化インデックスを紹介します。
はじめに
前回の記事”SQL Serverクラスタ化インデックスの概要”では、SQL Serverのインデックスとクラスタ化インデックスの要件について説明しました。
先に進む前に、SQL Serverクラスター化インデックスの簡単な概要を見てみましょう:
- クラスター化インデックスキーに従ってデータを物理的にソートします
- テーブルごとにクラスター化インデックスを一つだけ持つことができます
- クラスター化インデックスのないテーブルはヒープであり、パフォーマンスの問題につながる可能性があります
- SQL Serverは主キー列のクラスター化インデックスを自動的に作成します
- クラスター化インデックスはbツリー形式で格納され、次のようになります。以下に示すように、リーフノード内のデータページ
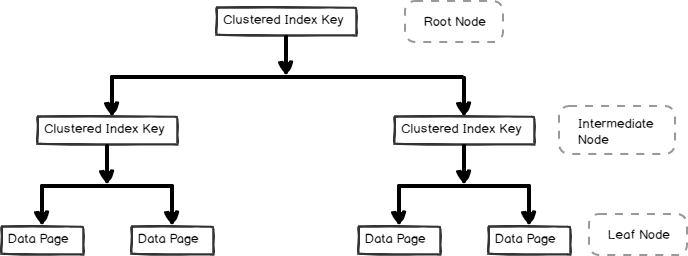
非クラスター化インデックス また、クエリのパフォーマンスとクエリのワークロードに応じた最適化にも役立ちます。 この記事では、クラスター化されていないインデックスとその内部について説明します。
SQL Serverの非クラスタ化インデックスの概要
非クラスタ化インデックスでは、リーフノードに実際のデータが含まれていません。 これは、実際のデータへのポインタで構成されています。
- テーブルにクラスター化インデックスが含まれている場合、リーフノードは実際のデータで構成されるクラスター化インデックスデータページを指します
- テーブルがヒープ(クラスター化インデックスなし)である場合、リーフノードはヒープページを指します
下の画像では、クラスター化インデックスのデータページを指す非クラスター化インデックスのリーフレベルを見ることができます。:
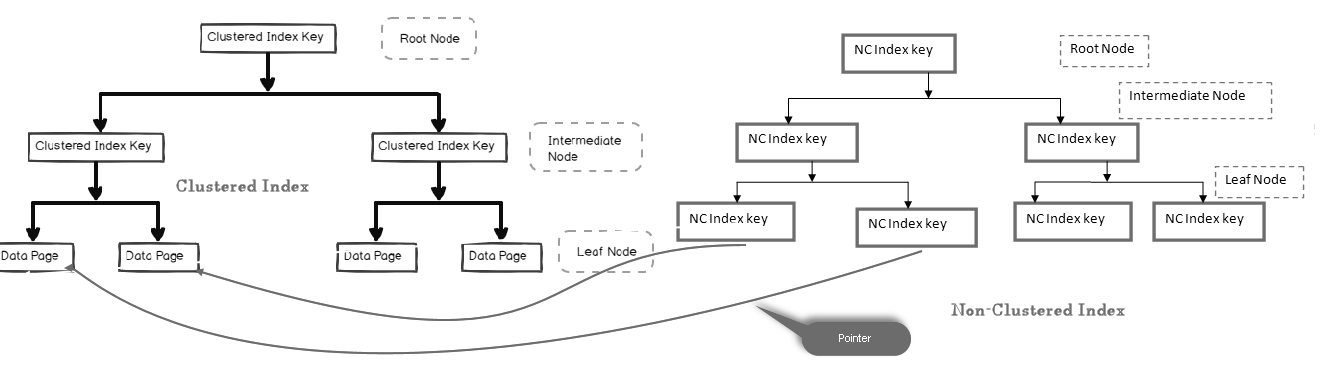
SQLテーブルには複数の非クラスタ化インデックスを含めることができます。
例を使用して、SQL Serverの非クラスタ化インデックスを理解しましょう。
-
索引なしでEmployee表を作成します
123456テーブルdboを作成します。従業員(EmpID INT,EMpName VARCHAR(50),EmpAge INT,EmpContactNumber VARCHAR(10)); -
その中にいくつかのレコードを挿入します
123従業員の値に挿入(1,’Raj’,32,8474563217)従業員の値に挿入(2,’kusum’,30,9874563210)従業員の値に挿入(3,’Akshita’,28,9632547120) -
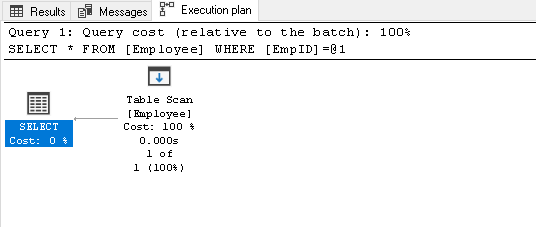
EmpID2を検索し、その実際の実行計画を探します
1Empidの従業員から*を選択します=2このテーブルにインデックスがないため、テーブルスキャンが実行されます:
-
EmpID列に一意のクラスタ化インデックスを作成する
1dboに一意のクラスタ化インデックスIx_Clustered_Empployeeを作成します。従業員(EmpID); -
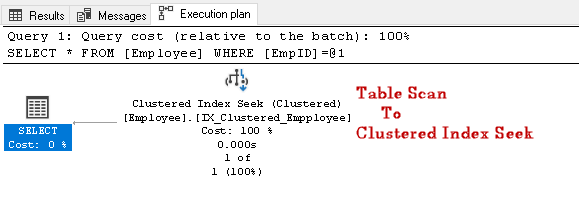
EmpID2を検索し、その実際の実行計画を探します
この実行計画では、テーブルスキャンがクラスタ化インデックスシークに変更されることがわかります:
特定の連絡先番号を持つ従業員を検索するための別のSQLクエリを実行しましょう:
|
1
|
Empcontactnumberの従業員から*を選択します=’9874563210′
|
EmpContactNumber列にインデックスがないため、クエリオプティマイザーはクラスタ化インデックスを使用しますが、インデックス全体をスキャンしてレコードを取:
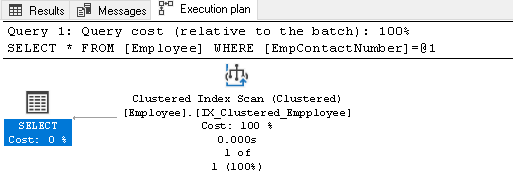
実行プランを右クリックし、実行プランXMLの表示を選択します:
新しいクエリウィンドウにXML実行プランが開きます。 ここでは、クラスター化インデックスキーを使用し、結果を取得するために個々の行を読み取ることに注意してください:

次のスクリプトを使用して、Employeeテーブルにさらにいくつかのレコードを挿入しましょう:
|
1
2
3
|
従業員の値に挿入(4,’Manoj’,38,7892145637)
従業員の値に挿入(5,’John’,33,7900654123)
従業員の値に挿入(6,’Priya’,18,9603214569)
|
この表には6人の従業員の記録があります。 次に、selectステートメントを再度実行して、特定の連絡先番号を持つ従業員レコードを取得します:
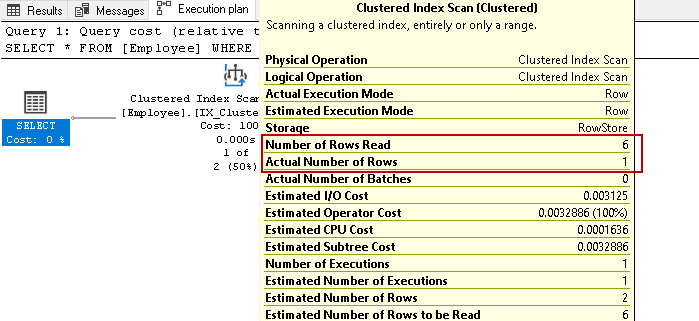
指定された条件に基づいて、6行すべての結果を再度スキャンします。 テーブルに何百万ものレコードがあるとします。 SQL Serverがすべてのインデックスキー行を読み取る必要がある場合は、リソースと時間のかかるタスクになります。
次の画像のように、クラスタ化インデックス(実際の表現ではありません)をBツリー形式で表すことができます:

前のクエリでは、sql Serverはルートノードページを読み取り、データ取得用に各リーフノードページと行を取得します。
今度は、EmpContactNumber列のEmployeeテーブルにインデックスキーとしてSQL Serverで一意の非クラスター化インデックスを作成しましょう:
|
1
|
dboに一意の非クラスター化インデックスIx_Nonclustered_Employeeを作成します。従業員(EmpContactNumber);
|
このインデックスを説明する前に、SELECTステートメントを再実行し、実際の実行プランを表示します:
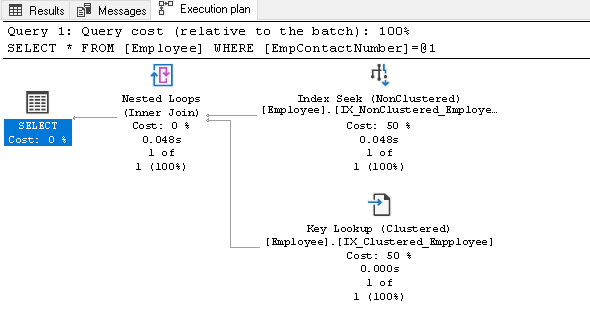
この実行プランでは、次の2つのコンポーネントが表示されます:
- インデックスシーク(非クラスター化)
- キー検索(クラスター化)
これらのコンポーネントを理解するには、SQL Serverの設計で非クラスタ化インデックスを確認する必要があります。 ここでは、リーフノードに非クラスタ化インデックスキー(EmpContactNumber)とクラスタ化インデックスキー(EmpID)が含まれていることがわかります):
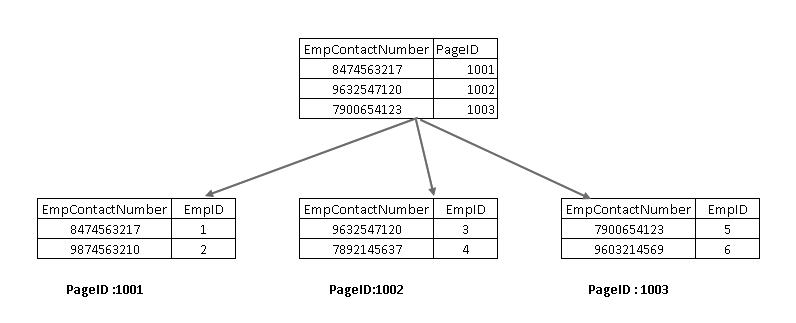
ここで、SELECTステートメントを再実行すると、非クラスタ化インデックスキーを使用してトラバースし、クラスタ化インデックスキーを持つページを指:
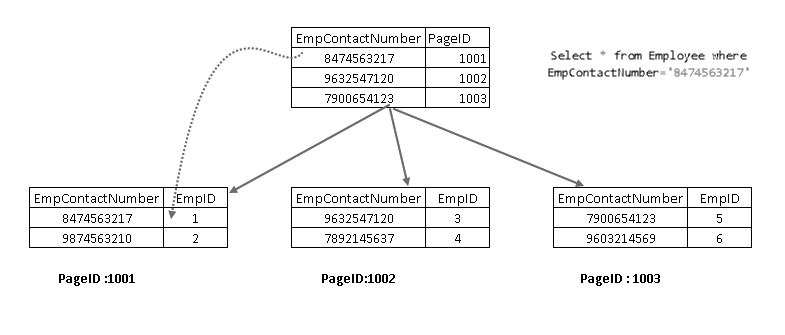
を実行すると、クラスタ化インデックスキーと非クラスタ化インデックスキーの組み合わせでレコードを取得することが示されます。 以下に示すように、SELECT文の完全なロジックを見ることができます:
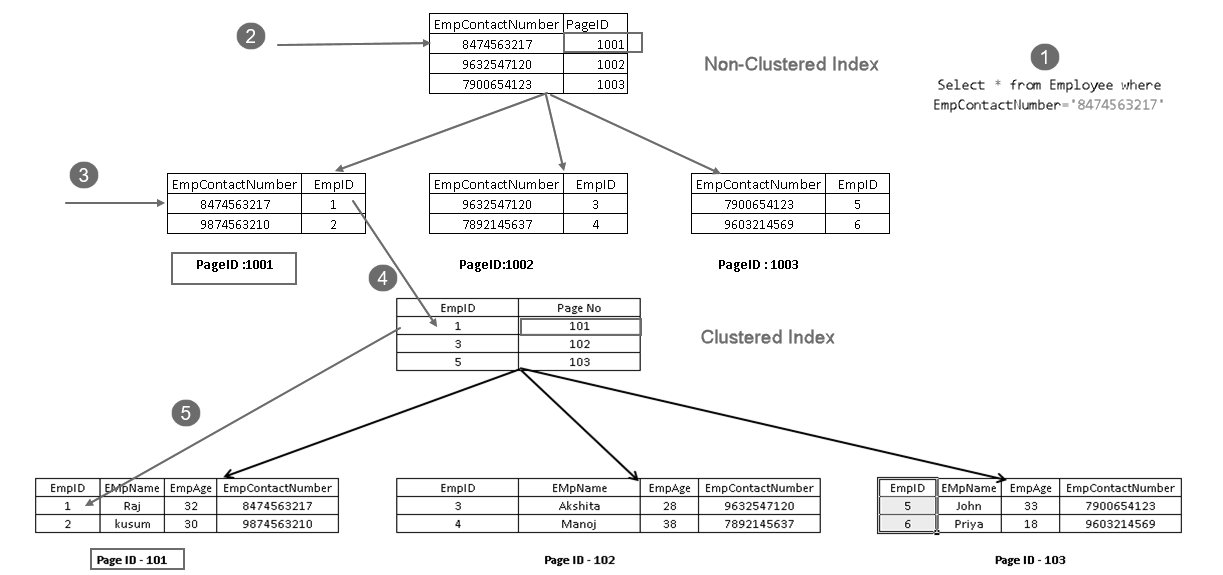
- ユーザーがselectステートメントを実行して、指定した連絡先番号
- と一致する従業員レコードを検索し、クエリオプティマイザは非クラスタ化インデックスキーを使用し、ページ番号1001
- このページはクラスタ化インデックスキーで構成されています。 上の画像にEmpID1が表示されます
- SQL Serverは、クラスター化インデックスキー
- を使用してEmpID1レコードで構成されるページno101を検出します
以前は、一致する行を読み取り、出力をユーザーに返します
以前は、一致する行を取得するために六つの行を読み取り、出力に一つの行を返すことがわかりました。 クラスター化されていないインデックスを使用した実行プランを見てみましょう:

非一意の非クラスタ化インデックスSQL Server
SQLテーブルに複数の非クラスタ化インデックスを持つことができます。 以前は、EmpContactNumber列に一意の非クラスター化インデックスを作成しました。
インデックスを作成する前に、次のクエリを実行して、EmpAge列に重複した値があるようにします:
|
1
2
3
|
更新従業員セットEmpAge=32ここでEmpID=2
更新従業員セットEmpAge=38ここでEmpID=6
更新従業員セットEmpAge=38ここでEmpID=3
|
一意でない非クラスター化インデックスに対して次のクエリを実行しましょう。 クエリ構文では、一意のキーワードを指定せず、一意でないインデックスを作成するようにSQL Serverに指示します:
|
1
|
dboに非クラスタ化インデックスNcix_Employee_Empageを作成します。Empage(エンパージュ));
|
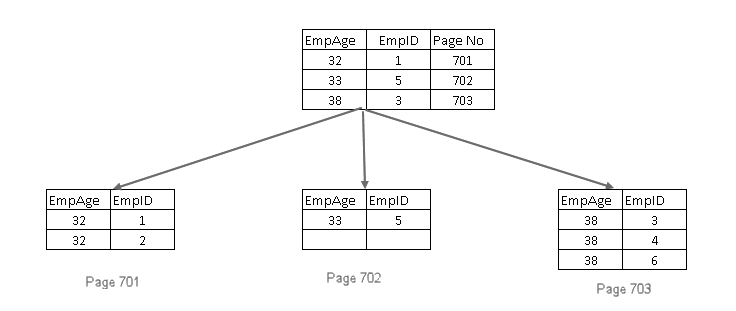
私たちが知っているように、インデックスのキーは一意でなければなりません。 この場合、一意でないキーを追加します。 質問が発生します:SQL Serverはこのキーをどのように一意にしますか?
SQL Serverは次のことを行います:
- 一意でない非クラスタ化インデックス
- クラスタ化インデックスキーも一意でない場合は、インデックスキーが一意になるように4バイトのuniquifierを追
SQL Serverの非クラスタ化インデックスに非キー列を含める
次のクエリの実際の実行計画をもう一度見てみましょう:
|
1
2
|
Select*from Employee
where EmpContactNumber=’8474563217′
|
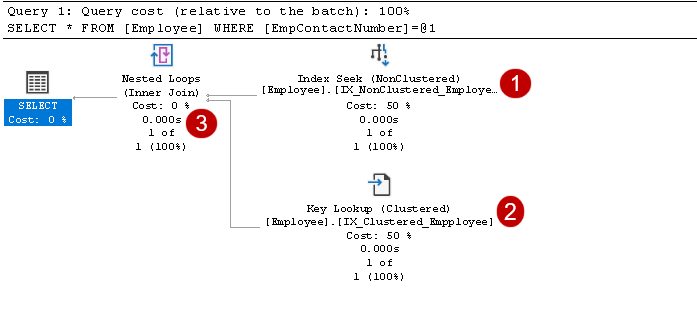
に非キー列を含める上の図に示すように、インデックスシーク演算子とキー検索演算子が含まれます:
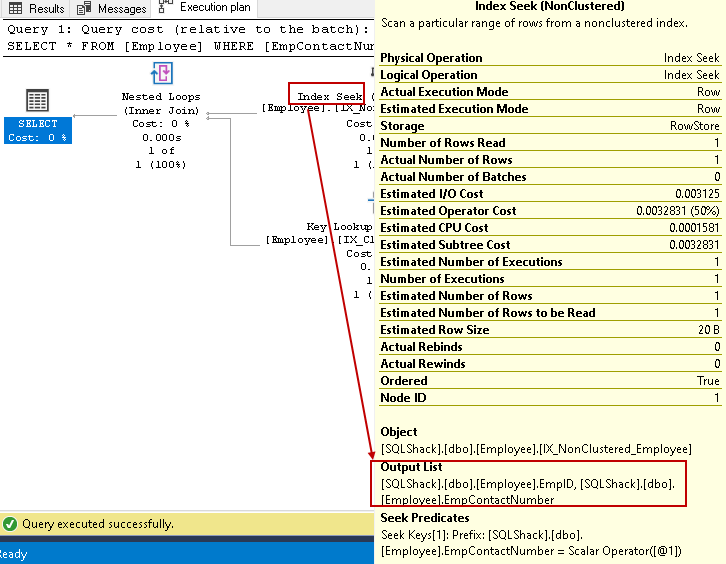
- インデックスは、次のように求めます: SQLクエリオプティマイザは、非クラスタ化インデックスに対してインデックスシークを使用し、EmpID、EmpContactNumber列をフェッチします
-
この手順では、クエリオプティマイザは、クラスター化インデックスに対してキールックアップを使用し、EmpName列とEmpAge列の値をフェッチします
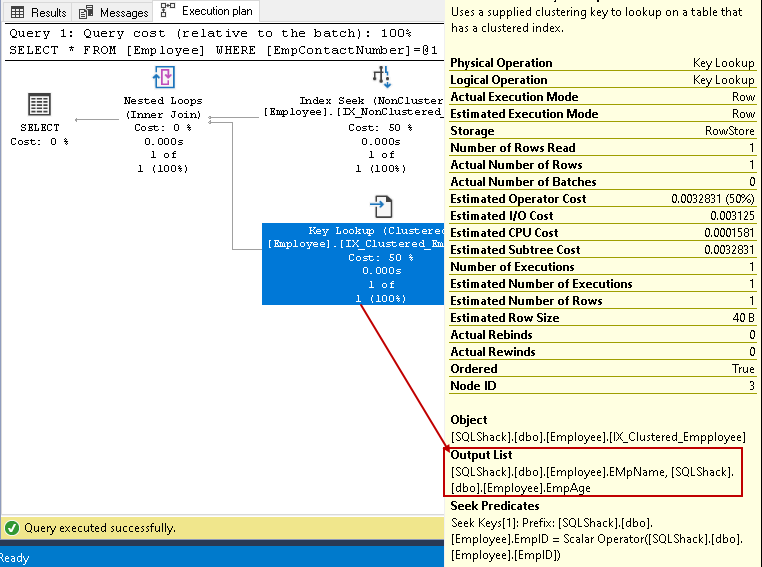
-
この手順では、クエリオプティマイザは、非クラスタ化インデックスからの各行出力に対してネストされたループを使用して、クラスタ化インデックス行
ネストされたループは、大きなテーブルの場合はコストのかかる演算子になる可能性があります。 非クラスター化インデックス非キー列を使用すると、コストを削減できます。 非クラスター化インデックスでは、index句を使用して非キー列を指定します。
含まれている列を使用して、SQL Serverで非クラスタ化インデックスを削除して作成しましょう:
|
1
2
3
4
5
6
7
|
インデックスをドロップします。
GO
ONに一意の非クラスタ化インデックスを作成します。
(
ASC
)
INCLUDE(EmpName,EmpAge)
|
インクルードされる列は、インデックスツリーのリーフノードの一部です。 これは、データ取得のためにさらに走査するのではなく、インデックス自体からデータをフェッチするのに役立ちます。
次の画像では、リーフノードの一部としてempnameとEmpAgeの両方の列が含まれています:
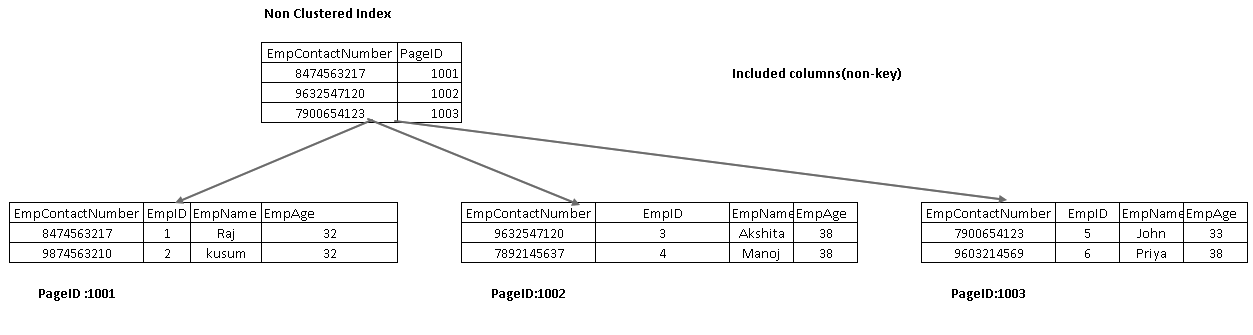
SELECTステートメントを再実行し、実際の実行計画を今すぐ表示します。 この実行計画にはキー検索とネストされたループはありません:

インデックスシークの上にカーソルを置き、出力列リストを表示しましょう。 SQL Serverでは、この非クラスター化インデックスシークを使用してすべての列を検索できます:
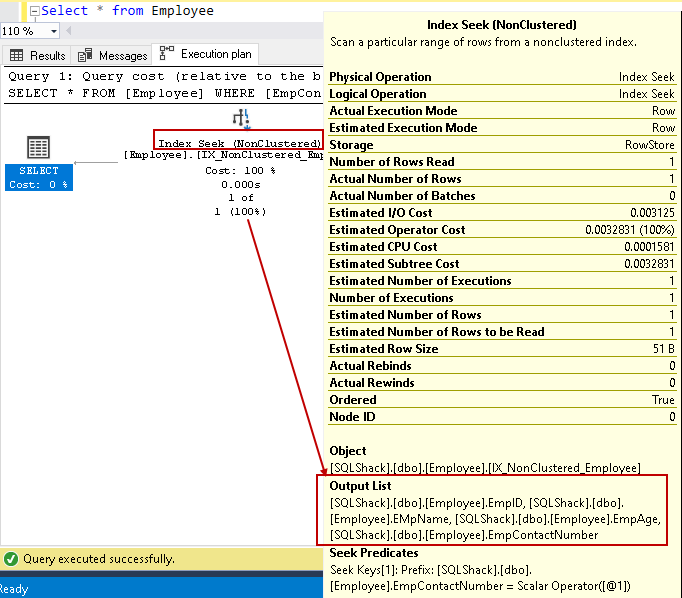
インクルードされた非キー列の助けを借りて、カバーインデックスを使用してクエリのパフォーマンスを向上させることができます。 ただし、インデックス定義内のすべての非キー列が必要であるという意味ではありません。 インデックスの設計には注意が必要であり、運用環境に配置する前にインデックスの動作をテストする必要があります。
結論
この記事では、SQL Serverの非クラスタ化インデックスと、クラスタ化インデックスとの組み合わせでの使用方法について説明しました。 ワークロードとクエリの動作に応じてインデックスを慎重に設計する必要があります。
- 著者
- 最近の投稿

彼は、単一のトピックに関する記事の最大の無料オンラインコレクションの一つの作成者であり、SQL Server Always On Availability Groupsに関する50部のシリーズを持っています。 SQL Serverコミュニティへの貢献に基づいて、彼はSQLShackで2020年と2021年に連続して権威ある「best author of the year」を含むさまざまな賞を受賞しています。
ラージは常に新たな挑戦に興味を持っているので、彼の著作でカバーされているテーマについて相談する必要がある場合は、ラージンドラに連絡することが[email protected]
Rajendra Guptaによるすべての投稿を表示
- ARMテンプレートを使用してSql Server Linuxイメージを使用してAzureコンテナインスタンスをデプロイする-2021年12月21日
- AWS RDS SQL ServerとAmazon Rdsのリモートデスクトップア10, 2021