te gebruiken In deze gids zal ik uitleggen wat de standaard foutformule is en hoe deze te gebruiken om de standaard fout uit te werken door middel van een voorbeeld.
Wat is de standaardfout?
de standaardfout (SE), soms aangeduid als de standaardfout van het gemiddelde (SEM), is een statistiek die overeenkomt met de standaardafwijking van een steekproefverdeling ten opzichte van de gemiddelde waarde. Maar wat is dat eigenlijk?
geef aan dat u geïnteresseerd bent in de gemiddelde leeftijd waarop mensen in het Verenigd Koninkrijk de ziekte van Alzheimer hebben. Het is niet haalbaar om dit voor iedereen in het Verenigd Koninkrijk te bepalen, daarom nemen onderzoekers een steekproefpopulatie om een algemeen cijfer te generaliseren. Bijvoorbeeld, 10.000 Britse mensen met de ziekte kunnen worden geanalyseerd en zal worden gebruikt om de gemiddelde leeftijd van de diagnose te genereren. Als u dit doet op een willekeurige steekproef van 5.000 patiënten, kunt u een gemiddelde leeftijd van de diagnose van 61,5 jaar krijgen. Echter, als u de steekproef analyse op een aparte willekeurige steekproef van 10.000 andere patiënten, kunt u een gemiddelde leeftijd van 62,3 jaar krijgen. Laten we zeggen, hypothetisch gesproken natuurlijk, dat als je in staat zou zijn om alle mensen in het Verenigd Koninkrijk die de ziekte van Alzheimer hebben te analyseren om het werkelijke cijfer te krijgen, je zou kunnen eindigen met 64,3 jaar. U kunt zien dat de cijfers verkregen uit de steekproef populaties (61,5 en 62,3 jaar) verschilt van de werkelijke cijfer (64,3 jaar). Deze variatie in gemiddelde waarden wordt verwacht, en als je het aantal mensen in uw steekproefpopulatie verhoogt, krijg je een waarde die dichter bij het werkelijke cijfer ligt. Dit is precies wat de standaardfout vertegenwoordigt. De standaardfout betekent deze variatie in de gemiddelde waarden tussen de steekproefpopulaties.
voor meer informatie stel ik voor dat u de korte Statistieknota van de professoren Douglas Altman en Martin Bland, gepubliceerd in het British Medical Journal, leest. Het is een nuttig inzicht in wat de standaardfout is en wat het verschil is met de standaarddeviatie.
de standaardfoutformule
om de standaardfout te berekenen, moet u over twee informatie beschikken: de standaardafwijking en het aantal monsters in de gegevensverzameling. De standaardfout wordt berekend door de standaarddeviatie te delen door de vierkantswortel van het aantal monsters.
hier is de volledige geannoteerde standaard foutformule:
voorbeeld
om de standaard foutformule beter te begrijpen, kan het helpen om door een voorbeeld te gaan. Stel dat we een bevolking van 80 mensen en we zijn geïnteresseerd in hun lengte. We meten hun hoogte en berekenen de standaardafwijking als 30,6 cm. We moeten deze waarden nu in onze vergelijking stoppen:
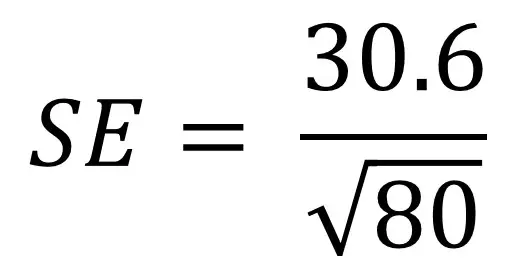 Als u zich ongemakkelijk voelt bij het invoeren van vergelijkingen in rekenmachines, kunt u de formule opsplitsen in beheersbare brokken. Hier zijn de stappen die u kunt nemen.
Als u zich ongemakkelijk voelt bij het invoeren van vergelijkingen in rekenmachines, kunt u de formule opsplitsen in beheersbare brokken. Hier zijn de stappen die u kunt nemen.
- bereken eerst de vierkantswortel van het aantal monsters (n). In dit geval is n 80. De vierkantswortel van 80 is 8,94.
- deel vervolgens de standaarddeviatie (30.6) door de vierkantswortel van 80 (8.94). Dit geeft een waarde van 3,42.
- daarom is de standaardfout in onze populatie voor lengte 3,42 cm.