door: Ben Snaidero
overzicht
In deze sectie zullen we de dingen behandelen die u moet weten over niet-geclusterde indexen.
Wat is een niet-geclusterde index
een niet-geclusterde index (of reguliere B-boomindex) is een index waarbij de volgorde van de rijen niet overeenkomt met de fysieke volgorde van de werkelijke gegevens. Het wordt bevestigd door de kolommen die deel uitmaken van de index. In een niet-geclusterde index bevatten de pagina ‘ s van de index geen werkelijke gegevens, maar in plaats daarvan verwijzingen naar de werkelijke gegevens. Deze pointers zouden verwijzen naar de geclusterde index datapage waar de werkelijke gegevens bestaan (of de heap pagina als er geen geclusterde index bestaat op de tabel).
waarom niet-geclusterde indexen
het belangrijkste voordeel van het hebben van een niet-geclusterde index op een tabel is dat het snelle toegang tot gegevens biedt. Met de index kan de database-engine snel gegevens lokaliseren zonder de hele tabel te hoeven scannen. Naarmate een tabel groter wordt, is het erg belangrijk dat de juiste indexen aan de tabel worden toegevoegd, omdat zonder indexen de query-prestaties dramatisch zullen dalen.
Wanneer moeten niet-geclusterde indexen worden aangemaakt
er zijn twee gevallen waarin een niet-geclusterde index op een tabel voordelig is. Ten eerste, wanneer er meer dan één reeks kolommen die worden gebruikt in de waar clauseof queries die toegang tot de tabel. Een tweede index (ervan uitgaande dat er al een geclusterde index op de primaire sleutel kolom) zal versnellen uitvoertijden en reduceIO voor de andere queries. Ten tweede, als uw query ‘ s vaak gegevens vereisen om in een bepaalde volgorde te worden geretourneerd, kan het hebben van een index op deze kolommen de hoeveelheid CPU en geheugen verminderen die nodig is omdat extra sortering niet hoeft te worden gedaan, aangezien de gegevens in de index al zijn besteld.
het volgende voorbeeld toont dat er geen tabelscan nodig is om de gegevens op te halen, alleen een index zoeken van de niet-geclusterde index en een lookup van de geclusterde index om de gegevens te krijgen. Merk ook op dat er geen sortering vereist is omdat de gegevens al in de juiste volgorde staan.
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

Hoe maak je een niet-geclusterde index
het maken van een niet-geclusterde index is in principe hetzelfde als het maken van geclusterde index,maar in plaats van het specificeren van de geclusterde clause we specifyNONCLUSTERED. We kunnen deze clausule ook helemaal weglaten omdat een niet-geclusterde de standaard is bij het aanmaken van een index.
de TSQL hieronder toont een voorbeeld van elk statement.
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
Wat is een dekkingsindex
Acovering index is een index die bestaat uit alle (of meer) kolommen die nodig zijn om aan een query te voldoen als sleutelkolommen van de index. Wanneer een dekkingsindex kan worden gebruikt om een query uit te voeren, zijn minder Io-bewerkingen nodig omdat de optimizerno langer extra lookups moet uitvoeren om de werkelijke tabelgegevens op te halen.
Hieronder is een voorbeeld van de TSQL die u kunt gebruiken om een bovenliggende index aan te maken in de producttabel.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
de volgende TSQL query kan nu worden uitgevoerd door alleen toegang te krijgen tot de nieuwe indexwe zojuist gemaakt, omdat alle kolommen in de query deel uitmaken van de index.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
het volgende uitleg plan bevestigt dat er geen extra lookup vereist is voor deze query.

Wat is een index met opgenomen kolommen
een index gemaakt met opgenomen kolommen is een niet-geclusterde index die ook niet-sleutelkolommen in de bladknopen van de index bevat, vergelijkbaar met een geclusterde index. Er zijn een paar voordelen aan het gebruik van opgenomen kolommen. Eerst geeft het je de mogelijkheid om kolommen types die niet zijn toegestaan als index sleutels in yourindex op te nemen. Ook, wanneer alle kolommen in uw query zijn ofwel een indexsleutel of opgenomen kolom, de query niet langer hoeft te doen een extra lookup om alle gegevens die nodig zijn om te voldoen aan de query, wat resulteert in minder schijfbewerkingen. Dit is vergelijkbaar met de eerder genoemde dekkingsindex.
gebruikmakend van hetzelfde voorbeeld hierboven zal de volgende TSQL dezelfde index aanmaken, behalve met de kolom productnummer als een kolom opgenomen en niet een kolom met indexsleutel.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
met behulp van dezelfde query als hierboven zou dit ook in staat moeten zijn om uit te voeren zonder extra lookups te vereisen.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
de volgende uitleg plan bevestigt dat er geen extra lookup vereist voor deze query ook.

niet-geclusterde indexen relatie tot geclusterde index
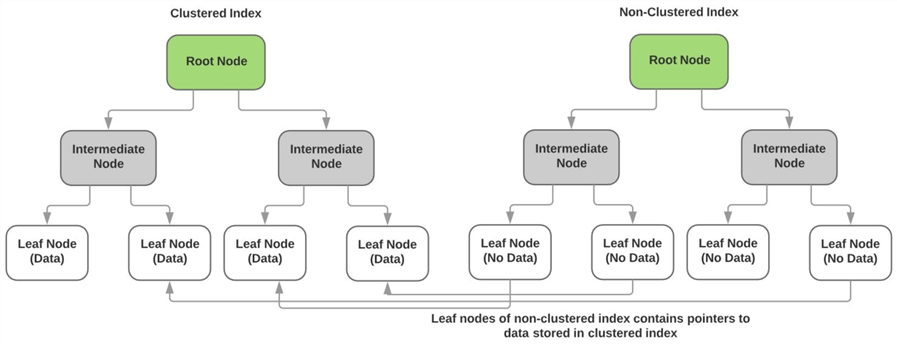
zoals hierboven beschreven, slaat de geclusterde index de werkelijke gegevens van de niet-toetskolommen op in de bladknopen van de index. De bladknopen van elke niet-geclusterde index bevatten geen gegevens en hebben in plaats daarvan verwijzingen naar de werkelijke gegevenspagina(of bladknoop) van de geclusterde index. Het diagram hieronder illustreert dit punt.
gefilterde indexen
Wat is het?
een gefilterde index is een speciaal indextype waarbij slechts een bepaald deel van de rijen van de tabel is geïndexeerd. Op basis van de filtercriteria die wordt toegepast wanneer de index wordt gemaakt,worden alleen de resterende rijen geïndexeerd, wat ruimte kan besparen, de query-prestaties kan verbeteren en onderhoudskosten kan verminderen omdat de index veel kleiner is.
waarom gebruiken?
gefilterde indexen zijn nuttig wanneer u indexen aanmaakt op tabellen waar er veel NULL-waarden in bepaalde kolommen zijn of bepaalde kolommen een zeer lage kardinaliteit hebben en u vaak een lage frequentiewaarde opvraagt.
Hoe maak je het aan?
een gefilterde index wordt gemaakt door simpelweg een WHERE-clausule toe te voegen aan een niet-geclusterde index creation statement. De volgende TSQL is een voorbeeld van de syntaxis om een gefilterde index te creëren.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
Confirm Index Usage
de volgende query zou onze nieuw aangemaakte index moeten gebruiken omdat er zeer weinig records in de tabel staan met ShipDate NULL. Hier is de TSQL.
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;