dit artikel geeft een introductie van de niet-geclusterde index in SQL Server aan de hand van voorbeelden.
Inleiding
in een vorig artikel overzicht van geclusterde indexen van SQL Server, hebben we de vereiste van een index en geclusterde indexen in SQL Server onderzocht.
voordat we verder gaan, laten we een kort overzicht hebben van de SQL Server geclusterde index:
- Het fysiek soorten van gegevens op basis van de geclusterde index toets
- We hebben slechts één geclusterde index per tabel
- Een tabel zonder een geclusterde index is een hoop, en het kan leiden tot problemen met de prestaties
- SQL Server automatisch een geclusterde index voor de primary key kolom
- Een geclusterde index wordt opgeslagen in de b-boom-formaat en bevat de gegevens van pagina ‘ s in het blad knooppunt, zoals hieronder weergegeven
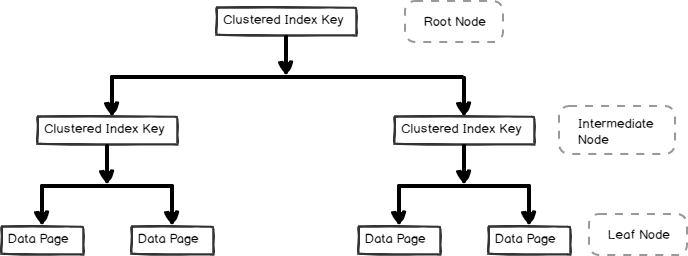
Non-Clustered indexen zijn ook nuttig voor query prestaties en optimalisatie afhankelijk van query workload. Laten we in dit artikel de niet-geclusterde index en de binnenkant ervan verkennen.
overzicht van de niet-geclusterde index in SQL Server
In een niet-geclusterde index bevat het bladknooppunt niet de werkelijke gegevens. Het bestaat uit een verwijzing naar de werkelijke gegevens.
- als de tabel Een geclusterde index bevat, wijst de bladknop naar de geclusterde indexgegevenspagina die bestaat uit werkelijke gegevens
- als de tabel een heap is (zonder geclusterde index), wijst de bladknop naar de heappagina
in de onderstaande afbeelding kunnen we kijken naar het bladniveau van de niet-geclusterde index die naar de gegevenspagina in de geclusterde index wijst:
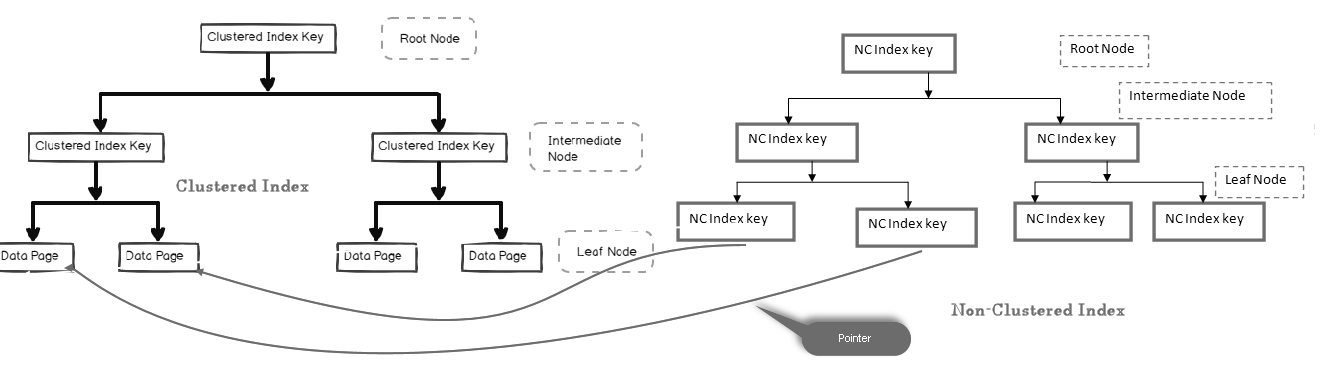
we kunnen meerdere niet-geclusterde indexen hebben in SQL-tabellen omdat het een logische index is en geen gegevens fysiek sorteert in vergelijking met de geclusterde index.
laten we de niet-geclusterde index in SQL Server begrijpen met behulp van een voorbeeld.
-
een Medewerkerstabel aanmaken zonder index erop
123456maak tabel dbo.Werknemer(EmpID int,EMpName VARCHAR(50),EmpAge int,Empcontactnummer VARCHAR(10)); -
Plaats enkele records in het
123Insert into Employee waarden(1,’Raj’,32,8474563217)Insert into Employee values(2,’kusum’,30,9874563210)Insert into Employee values(3,’Akshita’,28,9632547120) -
Zoeken naar de EmpID 2 en kijken voor de feitelijke uitvoering van het
1Select * from Werknemer where EmpID=2Het doet een tabel-scan omdat wij hebben geen index in deze tabel:
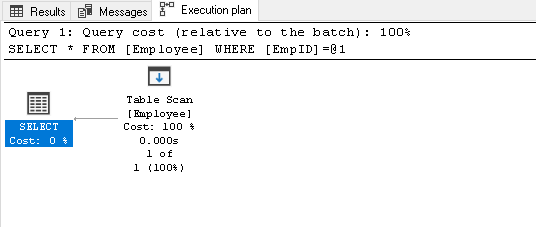
-
Maak een unieke geclusterde index op de EmpID kolom
1MAAK UNIEKE GECLUSTERDE INDEX IX_Clustered_Empployee OP dbo.Werknemer (EmpID); -
zoek naar de EmpID 2 en zoek naar het feitelijke uitvoeringsplan ervan
In dit uitvoeringsplan kunnen we zien dat de tabelscan verandert in een geclusterde index seek:
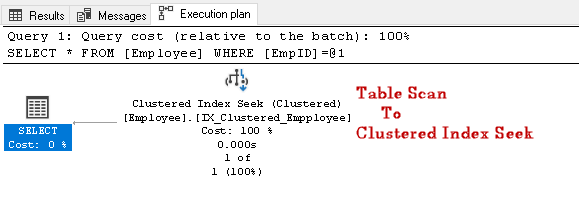
laten we een andere SQL-query uitvoeren voor het zoeken van een werknemer met een specifiek contactnummer:
|
1
|
Select * from Werknemer where EmpContactNumber=’9874563210′
|
We doen het niet hebben van een index op de EmpContactNumber kolom, dus Query Optimizer maakt gebruik van de geclusterde index maar het tast de hele index voor het ophalen van de record:
klik-Rechts op de uitvoering van het plan en selecteer Toon uitvoeringsplan XML:
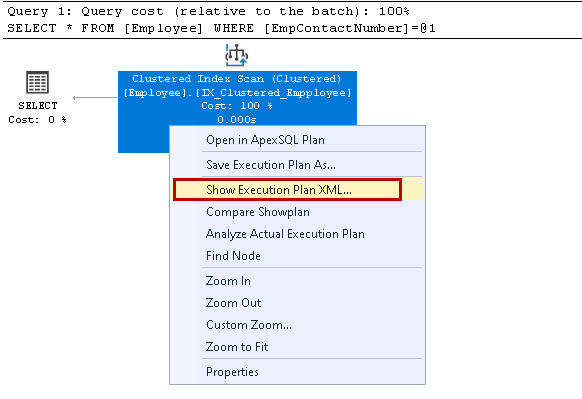
het opent het XML-uitvoeringsplan in het nieuwe query-venster. Hier merken we op dat het de geclusterde indexsleutel gebruikt en de afzonderlijke rijen leest voor het ophalen van het resultaat:

laten we nog een paar records invoegen in de Medewerkerstabel met behulp van het volgende script:
|
1
2
3
|
Insert into Employee values(4,’Manoj’,38,7892145637)
Insert into Employee values(5,’Johannes’,33,7900654123)
Insert into Employee values(6,’Priya’,18,9603214569)
|
We hebben zes medewerkers van records in deze tabel. Voer nu het SELECT-statement opnieuw uit voor het ophalen van werknemersrecords met een specifiek contactnummer:
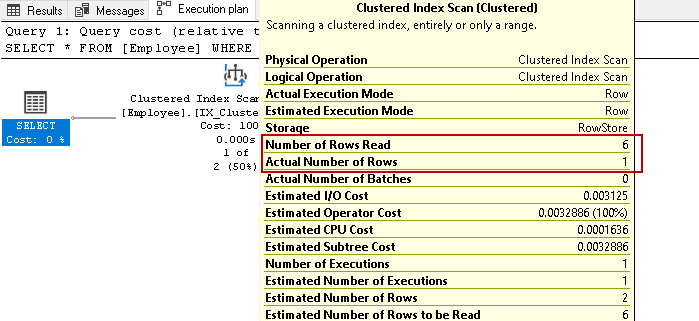
het scant opnieuw alle zes rijen voor het resultaat op basis van de opgegeven voorwaarde. Stel je voor dat we miljoenen records in de tabel hebben. Als SQL Server Alle index-toetsenrijen moet lezen, zou dit een bron en tijdrovende taak zijn.
we kunnen geclusterde index (geen werkelijke representatie) weergeven in het B-tree formaat volgens de volgende afbeelding:

In de vorige query leest SQL Server de root node pagina en haalt elke blad node pagina en rij voor het ophalen van gegevens.
laten we nu een unieke niet-geclusterde index maken in SQL Server op de Medewerkerstabel in de kolom Empcontact number als de indexsleutel:
|
1
|
maak unieke niet-geclusterde INDEX IX_NONCLUSTERED_EMPLOYEE op dbo.Medewerker (Empcontactnummer);
|
Voordat we dit verklaren index opnieuw op de SELECT-instructie en bekijk de daadwerkelijke uitvoering plan:
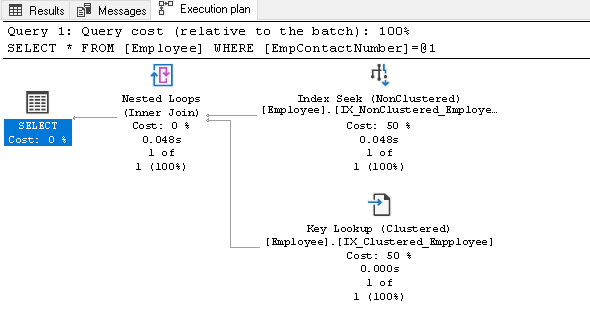
In dit uitvoeringsplan kunnen we zien twee componenten:
- Index Zoeken (Geclusterde)
- Key Lookup (Geclusterde)
Te begrijpen dat deze onderdelen te bekijken, moeten we op een niet-geclusterde index in SQL Server-ontwerp. Hier kunt u zien dat de leaf node bevat de niet-geclusterde index-toets (EmpContactNumber) en geclusterde index-toets (EmpID):
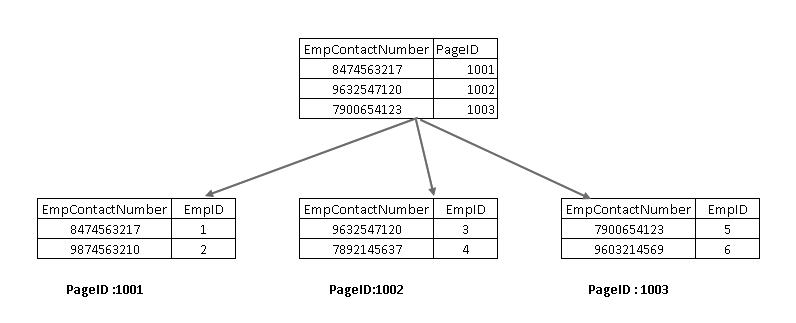
Nu, als opnieuw op de SELECT-instructie, het steekt met behulp van de niet-geclusterde index-toets en verwijst naar een pagina met sleutel geclusterde index:
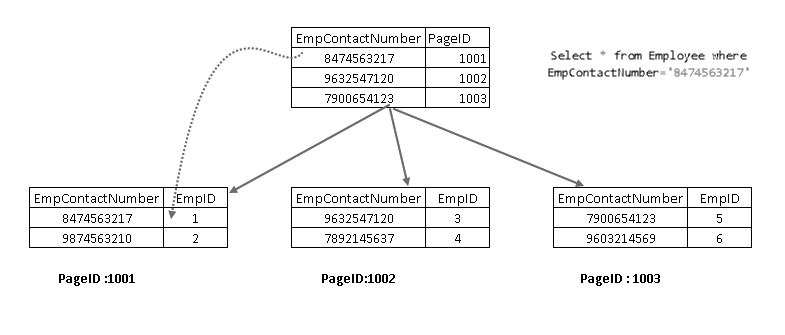
Het toont aan dat het haalt het record met een combinatie van geclusterde index in de sleutel en niet-geclusterde index-toets. U kunt de volledige logica voor het SELECT statement zien zoals hieronder getoond:
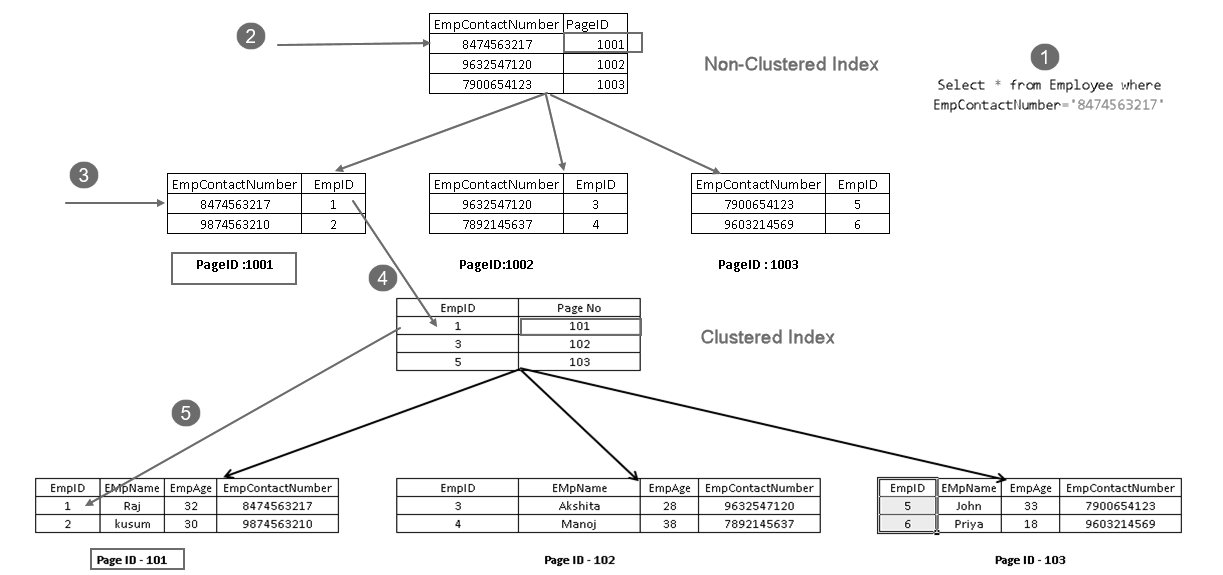
- een gebruiker voert een SELECT statement uit om werknemersrecords te vinden die overeenkomen met een opgegeven contactnummer
- Query Optimizer gebruikt een niet-geclusterde indexsleutel en vindt het paginanummer 1001
- deze pagina bestaat uit een geclusterde indexsleutel. U kunt EmpID 1 zien in de bovenstaande afbeelding
- SQL Server ontdekt pagina nr. 101 die bestaat uit EmpID 1-records met behulp van de geclusterde indexsleutel
- het leest de overeenkomende rij en geeft de uitvoer terug aan de gebruiker
eerder zagen we dat het zes rijen leest om de overeenkomende rij op te halen en retourneert een rij in de uitvoer. Laten we eens kijken naar een uitvoeringsplan met behulp van de niet-geclusterde index:

niet-Unieke niet-geclusterde index in SQL Server
we kunnen meerdere niet-geclusterde indexen hebben in een SQL-tabel. Eerder maakten we een unieke niet-geclusterde index op de kolom Empcontact number.
voordat u de index maakt, voert u de volgende query uit zodat we een dubbele waarde hebben in de EmpAge-kolom:
|
1
2
3
|
Update Werknemer set EmpAge=32 waar EmpID=2
Update Werknemer set EmpAge=38, waar EmpID=6
Update Werknemer set EmpAge=38, waar EmpID=3
|
Laten we uitvoeren de volgende query voor een niet-unieke, niet-geclusterde index. In de query-syntaxis geven we geen uniek trefwoord op, en het vertelt SQL Server om een niet-unieke index te maken:
|
1
|
maak niet-geclusterde INDEX NCIX_Employee_EmpAge op dbo.Werknemer (EmpAge);
|
zoals we weten, moet de sleutel van een index uniek zijn. In dit geval willen we een niet-unieke sleutel toevoegen. De vraag rijst: Hoe zal SQL Server Deze sleutel zo uniek maken?
SQL Server doet de volgende dingen voor het:
- voegt de sleutel geclusterde index in het blad en niet-leaf-pagina ‘ s van de niet-unieke, niet-geclusterde index
- Als de geclusterde index-toets is ook niet uniek, het voegt een 4-byte uniquifier zodat de index toets is uniek
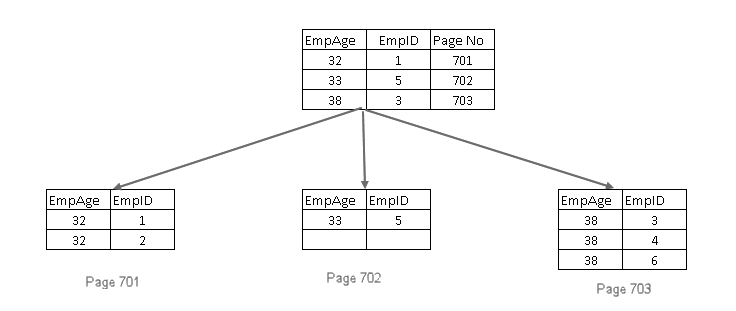
niet-sleutelkolommen in een niet-geclusterde index in SQL Server
Laten we eens kijken naar de volgende feitelijke uitvoering plan weer van de volgende query:
|
1
2
|
Select * from Werknemer
waar EmpContactNumber=’8474563217′
|
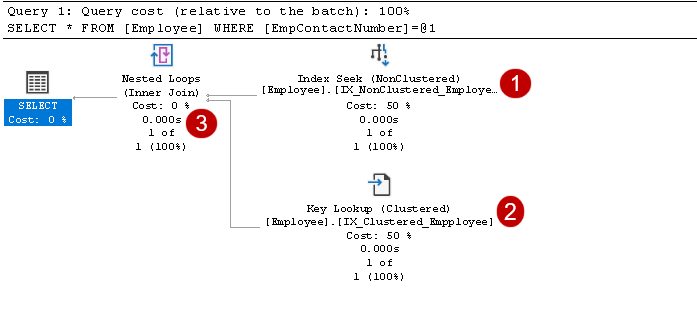
Het bevat de index zoeken en toets opzoekoperatoren, zoals weergegeven in de bovenstaande afbeelding:
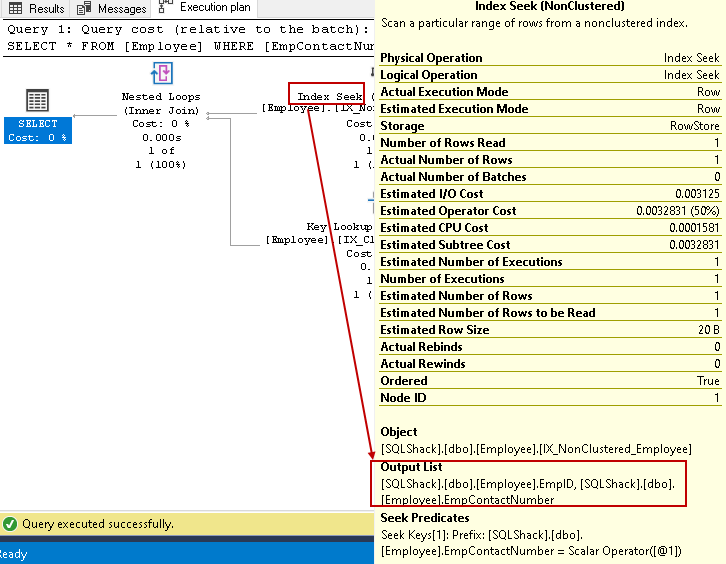
- De index wil: SQL-Query Optimizer maakt gebruik van een index zoeken op de niet-geclusterde index en haalt EmpID, EmpContactNumber kolommen
-
In deze stap Query Optimizer maakt gebruik van key lookup op de geclusterde index en haalt waarden voor EmpName en EmpAge kolommen
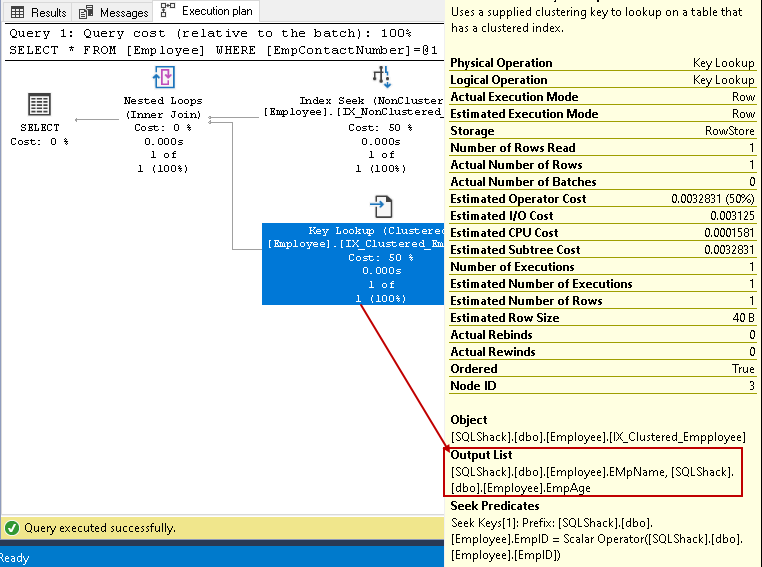
-
In deze stap, Query Optimizer gebruikt geneste lussen voor elke rij van de uitvoer van de niet-geclusterde index voor het afstemmen met de geclusterde index rij
de geneste lus kan een dure operator zijn voor grote tafels. We kunnen de kosten verlagen met behulp van de niet-geclusterde index-niet-sleutelkolommen. We specificeren de niet-sleutelkolom in de niet-geclusterde index met behulp van de indexclausule.
Laten we gemaakt en de niet-geclusterde index in SQL Server met behulp van de kolommen opgenomen:
|
1
2
3
4
5
6
7
|
DROP INDEX OP .
GO
MAAK UNIEKE NIET-GECLUSTERDE INDEX AAN .
(
ASC
)
INCLUDE (EmpName,EmpAge)
|
meegeleverde kolommen maken deel uit van de bladknoop in een indexboom. Het helpt om de gegevens van de index zelf op te halen in plaats van verder te gaan voor het ophalen van gegevens.
in de volgende afbeelding krijgen we beide meegeleverde kolommen EmpName en EmpAge als onderdeel van de bladknoop:
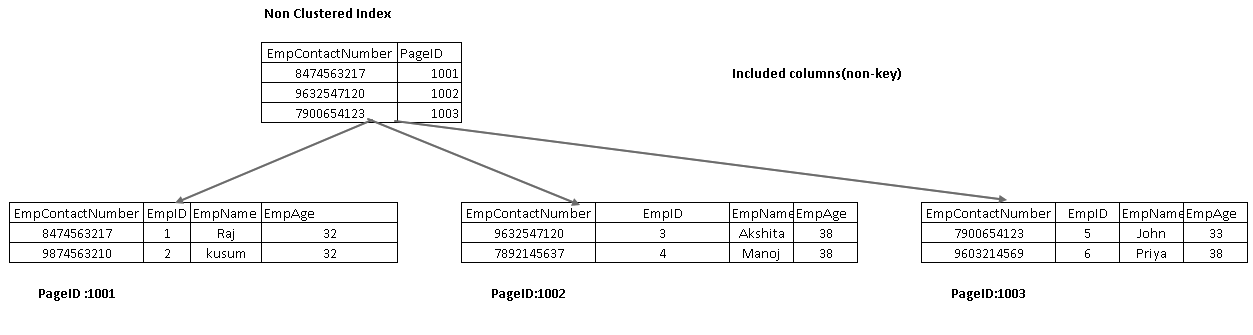
voer het SELECT statement opnieuw uit en bekijk nu het feitelijke uitvoeringsplan. We hebben geen key lookup en geneste lus in dit uitvoeringsplan:

laat de cursor boven de index zoeken en bekijk de lijst met uitvoerkolommen. SQL Server kan alle kolommen vinden met behulp van deze niet-geclusterde index seek:
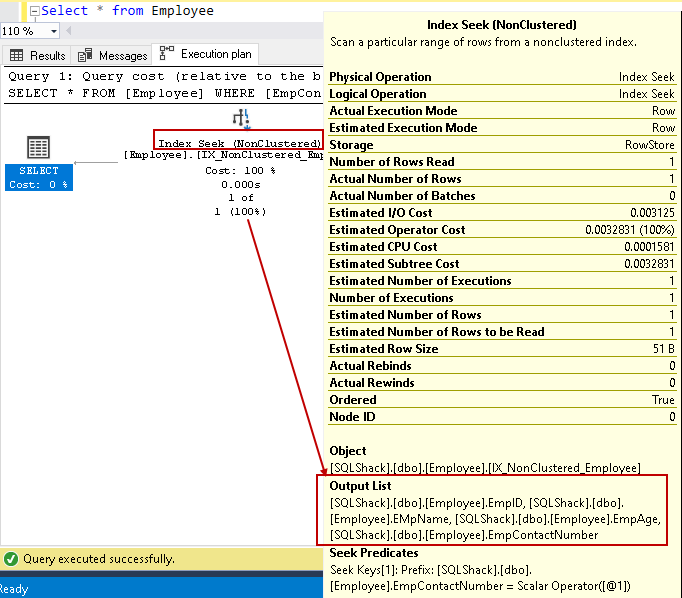
we kunnen de query-prestaties verbeteren met behulp van de dekkingsindex met behulp van meegeleverde niet-sleutelkolommen. Het betekent echter niet dat we alle niet-belangrijke kolommen in de indexdefinitie moeten hebben. We moeten voorzichtig zijn in het indexontwerp en het indexgedrag testen voor implementatie in de productieomgeving.
conclusie
In dit artikel hebben we de niet-geclusterde index in SQL Server onderzocht en het gebruik ervan in combinatie met de geclusterde index. We moeten zorgvuldig het ontwerp van de index volgens de werklast en query gedrag.
- auteur
- recente berichten

hij is de maker van een van de grootste gratis online collecties artikelen over een enkel onderwerp, met zijn 50-delige serie op SQL Server Always On Availability Groups. Op basis van zijn bijdrage aan de SQL Server community, werd hij in 2020 en 2021 bij SQLShack onderscheiden met verschillende prijzen, waaronder de prestigieuze “beste auteur van het jaar”.Raj is altijd geïnteresseerd in nieuwe uitdagingen, dus als je advies nodig hebt over een onderwerp dat in zijn geschriften wordt behandeld, kan hij worden bereikt in [email protected]
Bekijk alle berichten van Rajendra Gupta
- Gebruik de ARM templates te implementeren Azure container exemplaren met SQL Server Linux images – December 21, 2021
- bureaublad op Afstand toegang voor AWS RDS SQL Server met Amazon RDS-Aangepaste – December 14, 2021
- het Opslaan van SQL Server bestanden in Permanente Opslag voor Azure Container Gevallen – December 10, 2021