By: Ben Snaidero
Overview
w tej sekcji omówimy rzeczy, które musisz wiedzieć o indeksach nieklastrowych.
co to jest indeks nieklastrowy
indeks nieklastrowy (lub regularny indeks drzewa b) jest indeksem, w którym kolejność wierszy nie odpowiada fizycznej kolejności rzeczywistych danych. Jest on zastępowany kolumnami składającymi się na indeks. W indeksie nieklastrowym strony indeksu nie zawierają żadnych rzeczywistych danych, ale zamiast tego zawierają wskaźniki do rzeczywistych danych. Wskaźniki te wskazywałyby na stronę danych z indeksem klastrowym, w której istnieją rzeczywiste dane (lub stronę sterty, jeśli w tabeli nie istnieje indeks klastrowy).
po co tworzyć indeksy nieklastrowe
główną zaletą posiadania indeksu nieklastrowego w tabeli jest szybki dostęp do danych. Indeks pozwala silnikowi bazy danych szybko zlokalizować dane bez konieczności skanowania całej tabeli. W miarę powiększania się tabeli bardzo ważne jest, aby do tabeli dodawane były poprawne indeksy, ponieważ wydajność zapytań indexes drastycznie spadnie.
kiedy należy tworzyć indeksy nieklastrowe
istnieją dwa przypadki, w których posiadanie indeksu nieklastrowego na stole jest korzystne. Po pierwsze, gdy istnieje więcej niż jeden zestaw kolumn, które są używane w zapytaniach gdzie clauseof, które uzyskują dostęp do tabeli. Drugi indeks (przy założeniu, że w kolumnie klucza głównego znajduje się już indeks klastrowy) przyspieszy czas wykonania i skróci czas realizacji pozostałych zapytań. Po drugie, jeśli Twoje zapytania często wymagają zwracania danych w określonej kolejności, posiadanie indeksu na tych kolumnach może zmniejszyć ilość procesora i pamięci, ponieważ dodatkowe sortowanie nie będzie konieczne, ponieważ dane w indeksie są już uporządkowane.
poniższy przykład pokażpokaż do pobrania danych nie jest wymagane skanowanie tabeli, wystarczy wyszukiwanie indeksu nieklusterowanego indeksu i wyszukiwanie indeksu klastrowego, aby uzyskać dane. Należy również pamiętać, że nie jest wymagane sortowanie, ponieważ dane są już we właściwej kolejności.
SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 750ORDER BY ProductID;

jak utworzyć indeks nieklastrowy
tworzenie indeksu nieklastrowego jest w zasadzie tym samym, co tworzenie indeksu klastrowego, ale zamiast określać clusteredclause określamy specifyNONCLUSTERED. Możemy również całkowicie pominąć tę klauzulę, ponieważ przy tworzeniu indeksu domyślne jest nieklastrowanie.
TSQL poniżej pokazuje przykład każdej instrukcji.
-- Adding non-clustered index CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);
Co to jest indeks pokrycia
indeks pokrycia to indeks, który składa się ze wszystkich (lub więcej) kolumn wymaganych do spełnienia zapytania jako kluczowych kolumn indeksu. W przypadku użycia indeksu pokrywającego do wykonania zapytania, wymagane jest mniej operacji IO, ponieważ optimizerno musi wykonywać dodatkowe wyszukiwanie, aby pobrać rzeczywiste dane tabeli.
poniżej znajduje się przykład TSQL, którego można użyć do utworzenia indeksu pokrycia w tabeli produktów.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC,ProductNumber ASC);
następujące zapytanie TSQL może być teraz wykonane przez dostęp tylko do nowego indeksu, który właśnie utworzono, ponieważ wszystkie kolumny w zapytaniu są częścią indeksu.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
poniższy plan Explain potwierdza, że nie jest wymagane dodatkowe wyszukiwanie dla tego zapytania.

co to jest indeks z dołączonymi kolumnami
indeks utworzony z dołączonymi kolumnami jest indeksem nieklastrowym, który zawiera również kolumny bez klucza w węzłach liści indeksu, podobnie jak indeks klastrowy. Istnieje kilka korzyści z korzystania z dołączonych kolumn. Po pierwsze daje Ci możliwość włączenia typów kolumn, które nie są dozwolone jako klucze indeksowe w yourindex. Ponadto, gdy wszystkie kolumny w zapytaniu są albo kluczem indeksowym, albo dołączoną kolumną, zapytanie nie musi już wykonywać dodatkowego wyszukiwania, aby uzyskać wszystkie dane potrzebne do spełnienia zapytania, co skutkuje mniejszą liczbą operacji na dysku. Jest to podobne do wspomnianego wcześniej indeksu pokrywającego.
używając tego samego przykładu z powyższego, następujący TSQL utworzy ten sam indeks, z wyjątkiem kolumny Productnumberreferenced jako kolumny dołączonej, a nie kolumny klucza indeksu.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name ON Production.Product (Name ASC) INCLUDE (ProductNumber);
przy użyciu tego samego zapytania, co powyżej, powinno to być również w stanie wykonać bez wymagania dodatkowych wyszukiwań.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';
poniższy plan Explain potwierdza, że nie jest wymagane dodatkowe wyszukiwanie dla tego zapytania.

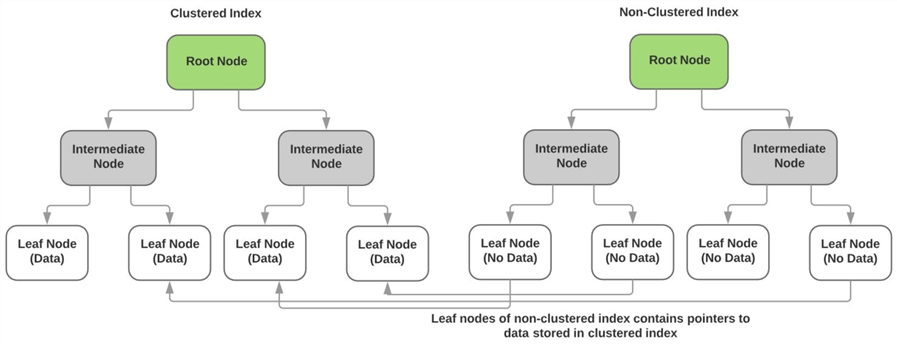
indeksy Nieklasterowezwiązanie z indeksem klastrowym
jak opisano powyżej, indeks klastrowy przechowuje rzeczywiste dane liczb nieklastrowych w węzłach liści indeksu. Węzły leaf każdego nie-clusteredindex nie zawierają żadnych danych, a zamiast tego mają wskaźniki do rzeczywistej strony danych (lub węzła leaf) indeksu clustered. Poniższy diagram ilustruje ten punkt.
indeksy filtrowane
co to jest?
indeks filtrowany jest specjalnym typem indeksu, w którym indeksowana jest tylko pewna część wierszy tabeli. W oparciu o kryteria filtra, które są stosowane, gdy indeks jest tworzony, indeksowane są tylko pozostałe wiersze, co może zaoszczędzić miejsce, poprawić wydajność zapytań i zmniejszyć koszty konserwacji, ponieważ indeks jest znacznie mniejszy.
po co go używać?
przefiltrowane indeksy są przydatne, gdy tworzysz indeksy w tabelach, w których istnieje wiele wartości NULL w niektórych kolumnach lub niektóre kolumny mają bardzo niską cardinalityi często pytasz o wartość niskiej częstotliwości.
jak go stworzyć?
indeks filtrowany jest tworzony po prostu przez dodanie klauzuli WHERE do dowolnej instrukcji tworzenia nieklusteredindex. Poniższy TSQL jest przykładem składni tworzenia przefiltrowanego indeksu.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader(OrderDate ASC) WHERE ShipDate IS NULL;
Confirm Index Usage
poniższe zapytanie powinno używać naszego nowo utworzonego indeksu, ponieważ w tabeli jest bardzo kilka rekordów z SHIPDATE NULL. Oto TSQL.
SELECT OrderDate FROM Sales.SalesOrderHeader WHERE ShipDate IS NULLORDER BY OrderDate ASC;