w tym artykule przedstawiono nieklastrowany indeks w SQL Server na przykładzie.
wprowadzenie
w poprzednim artykule omówienie indeksów klastrowych SQL Server zbadaliśmy wymagania indeksów i indeksów klastrowych w SQL Server.
zanim przejdziemy dalej, zróbmy krótkie podsumowanie indeksu klastrowego serwera SQL:
- fizycznie sortuje dane zgodnie z klastrowym kluczem indeksu
- możemy mieć tylko jeden klastrowy indeks na tabelę
- tabela bez klastrowego indeksu jest stertą i może prowadzić do problemów z wydajnością
- SQL Server automatycznie tworzy klastrowy indeks dla kolumny klucza podstawowego
- indeks klastrowy jest przechowywany w formacie B-tree i zawiera strony danych w węźle liści, jak pokazano poniżej
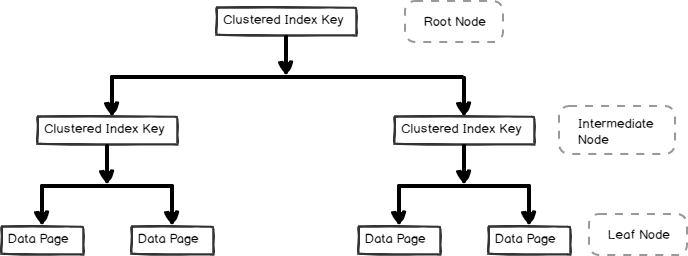
indeksy bez klastrów są również przydatne do wydajności i optymalizacji zapytań w zależności od obciążenia zapytań. W tym artykule przyjrzyjmy się indeksowi nieklastrowemu i jego wewnętrznym.
przegląd indeksu nieklastrowego w SQL Server
w indeksie nieklastrowym węzeł leaf nie zawiera rzeczywistych danych. Składa się ze wskaźnika do rzeczywistych danych.
- jeśli tabela zawiera indeks klastrowy, węzeł leaf wskazuje na stronę danych indeksu klastrowego, która składa się z rzeczywistych danych
- jeśli tabela jest stertą (bez indeksów klastrowych), węzeł leaf wskazuje na stronę sterty
na poniższym obrazku możemy spojrzeć na poziom liścia indeksu nieklastrowego wskazując Stronę danych w klastrze indeks:
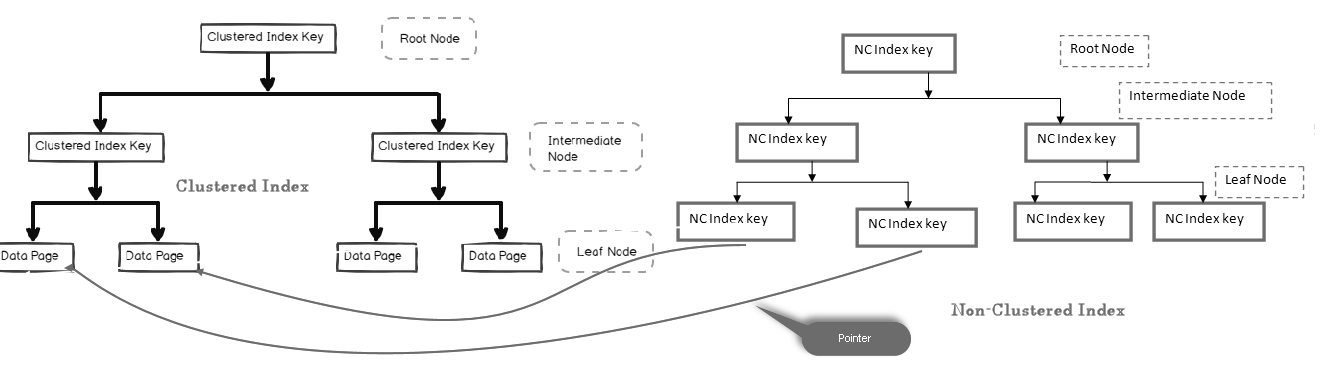
w tabelach SQL możemy mieć wiele indeksów nieklastrowych, ponieważ jest to indeks logiczny i nie sortuje danych fizycznie w porównaniu z indeksem klastrowym.
przyjrzyjmy się indeksowi nieklastrowemu w SQL Server na przykładzie.
-
Utwórz tabelę pracowników bez indeksu na niej
123456Utwórz tabelę DBO.Pracownik(EmpID INT,EMpName VARCHAR(50),EmpAge INT,EmpContactNumber VARCHAR(10)); -
wstawić do niego kilka rekordów
123Insert into employee values(1, 'Raj’,32,8474563217)Insert into employee values (2,’kusum’,30,9874563210)Insert into employee values (3, 'Akshita’,28,9632547120) -
wyszukaj EmpID 2 i poszukaj rzeczywistego planu jego wykonania
1Select * from Employee where EmpID=2skanuje tabelę, ponieważ nie mamy żadnego indeksu w tej tabeli:
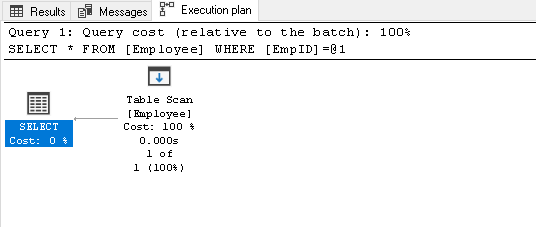
-
Utwórz unikalny indeks klastrowy w kolumnie EmpID
1Utwórz unikalny indeks klastrowy Ix_clustered_employee w dbo.Pracownik (EmpID); -
wyszukaj EmpID 2 i poszukaj rzeczywistego planu jego wykonania
w tym planie wykonania możemy zauważyć, że skanowanie tabeli zmienia się w grupowe wyszukiwanie indeksu:
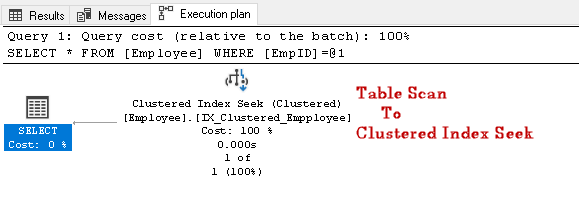
wykonajmy kolejne zapytanie SQL do wyszukiwania pracownika o określonym numerze kontaktowym:
|
1
|
Select * from Employee where EmpContactNumber=’9874563210′
|
nie mamy indeksu w kolumnie EmpContactNumber, dlatego Query Optimizer wykorzystuje indeks klastrowy, ale skanuje cały indeks w celu pobrania rekordu:
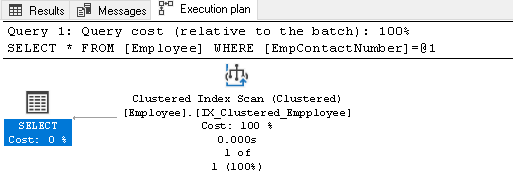
kliknij prawym przyciskiem myszy plan wykonania i wybierz Pokaż plan wykonania XML:
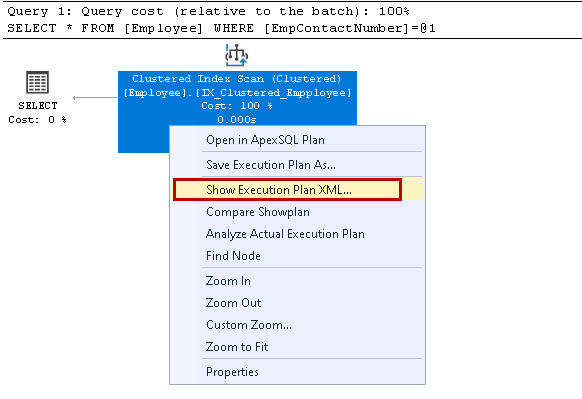
otwiera plan wykonania XML w nowym oknie zapytania. W tym miejscu zauważamy, że używa klastrowego klucza indeksu i odczytuje poszczególne wiersze w celu pobrania wyniku:

wstawmy jeszcze kilka rekordów do tabeli pracowników za pomocą następującego skryptu:
|
1
2
3
|
Insert into employee values (4, 'Manoj’,38,7892145637)
Insert into employee values (5, 'John’,33,7900654123)
Insert into employee values (6, 'Priya’,18,9603214569)
|
w tej tabeli mamy akta sześciu pracowników. Teraz ponownie wykonaj polecenie select, aby pobrać rekordy pracowników z określonym numerem kontaktowym:
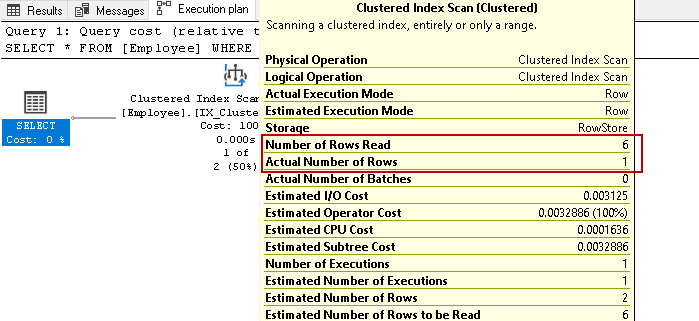
ponownie skanuje wszystkie sześć wierszy w poszukiwaniu wyniku na podstawie określonego warunku. Wyobraź sobie, że mamy miliony rekordów w tabeli. Jeśli SQL Server musi odczytać wszystkie wiersze klucza indeksu, będzie to zadanie zasobowe i czasochłonne.
możemy reprezentować indeks klastrowy (nie rzeczywisty) w formacie B-tree, jak na poniższym obrazku:

w poprzednim zapytaniu SQL Server odczytuje stronę węzła głównego i pobiera każdą stronę węzła liści i wiersz w celu pobrania danych.
teraz stwórzmy unikalny indeks nieklastrowy w SQL Server na tablicy pracowników w kolumnie EmpContactNumber jako klucz indeksu:
|
1
|
tworzenie unikalnego indeksu NIEKLUSTEROWANEGO IX_NonClustered_Employee w dbo.Pracownik (EmpContactNumber);
|
zanim wyjaśnimy ten indeks, uruchom ponownie instrukcję SELECT i zobacz rzeczywisty plan wykonania:
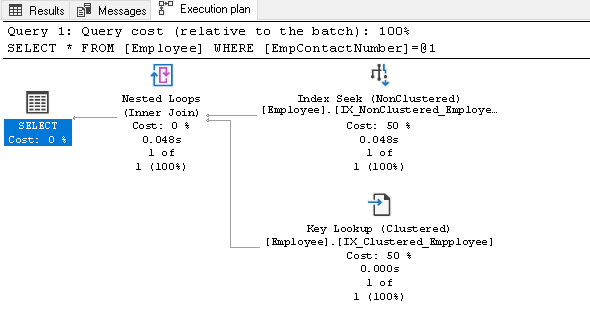
w tym planie wykonania możemy zobaczyć dwa składniki:
- Index Seek (Nieklustrowany)
- Key Lookup (klastrowany)
aby zrozumieć te komponenty, musimy przyjrzeć się indeksowi nieklastrowemu w projekcie SQL Server. Tutaj możesz zobaczyć, że węzeł leaf zawiera nieklastrowy klucz indeksowy (EmpContactNumber) i klastrowy klucz indeksowy (EmpID):
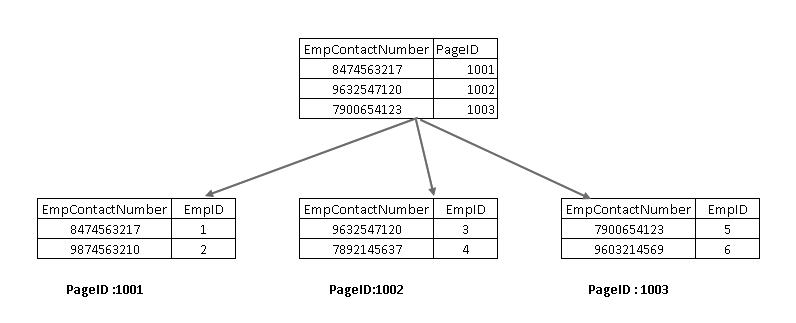
teraz, po ponownym uruchomieniu instrukcji SELECT, przechodzi ona za pomocą nieklastrowego klucza indeksu i wskazuje na stronę z klastrowym kluczem indeksu:
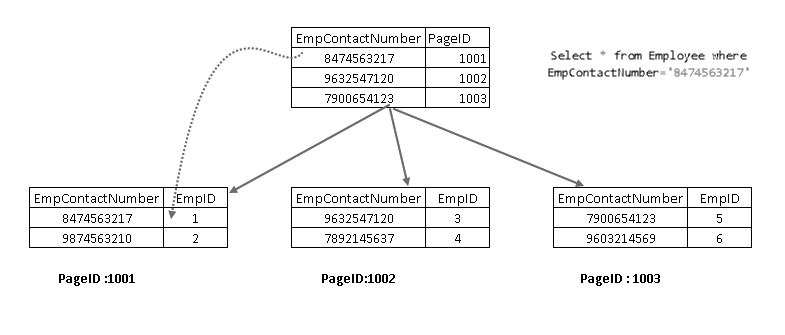
pokazuje, że pobiera rekord z kombinacją klastrowego klucza indeksowego i nieklastrowego klucza indeksowego. Możesz zobaczyć pełną logikę instrukcji SELECT, jak pokazano poniżej:
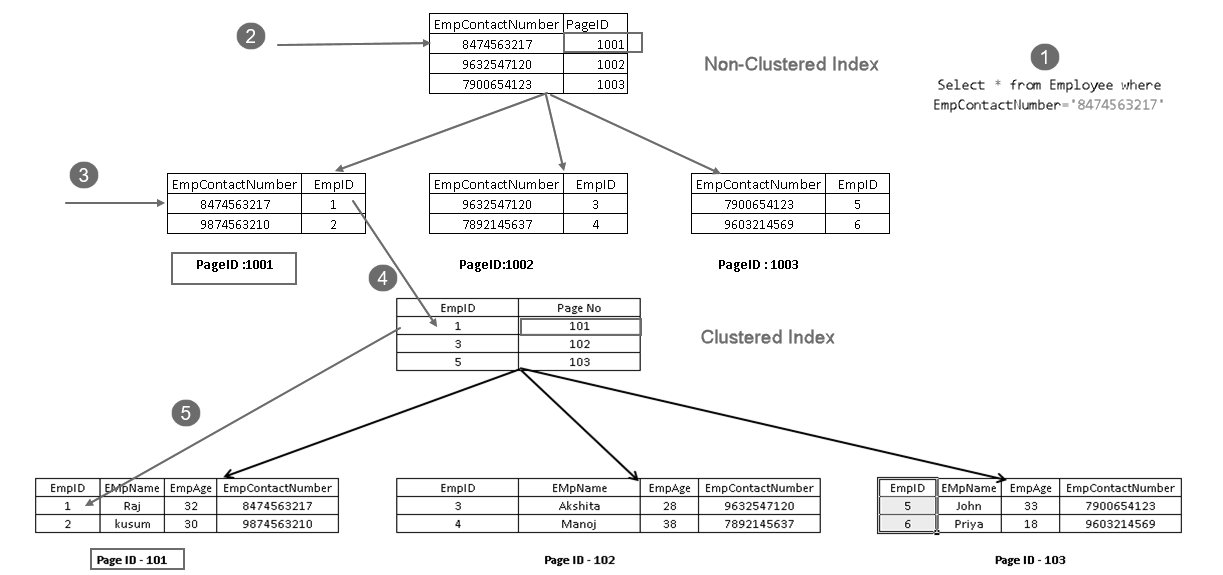
- użytkownik wykonuje polecenie select, aby znaleźć rekordy pracowników pasujące do podanego numeru kontaktowego
- Optymalizator zapytań używa nieklastrowego klucza indeksu i znajduje numer strony 1001
- ta strona składa się z klastrowego klucza indeksu. Możesz zobaczyć EmpID 1 na powyższym obrazku
- SQL Server wyszukuje stronę nr 101, która składa się z rekordów EmpID 1 używając klastrowego klucza indeksu
- odczytuje pasujący wiersz i zwraca wynik użytkownikowi
wcześniej widzieliśmy, że czyta sześć wierszy, aby pobrać pasujący wiersz i zwraca jeden wiersz na wyjściu. Spójrzmy na plan wykonania przy użyciu indeksu nieklastrowego:

Nie unikalny indeks nieklastrowy w SQL Server
w tabeli SQL możemy mieć wiele indeksów nieklastrowych. Wcześniej na kolumnie EmpContactNumber stworzyliśmy unikalny, nieklastrowany indeks.
przed utworzeniem indeksu wykonaj następujące zapytanie, abyśmy mieli duplikat wartości w kolumnie EmpAge:
|
1
2
3
|
Update Empage Empage=32 where EmpID=2
Update Empage Empage = 38 where EmpID=6
Update Empage Empage = 38 where EmpID=3
|
wykonajmy następujące zapytanie dla indeksu non-unique non-clustered. W składni zapytania nie określamy unikalnego słowa kluczowego, a to mówi SQL Server, aby utworzyć Nie-unikalny indeks:
|
1
|
Utwórz NIEKLUSTROWANY indeks NCIX_EMPLOYEE_EMPAGE w dbo.Pracownik (EmpAge);
|
jak wiemy, klucz indeksu powinien być unikalny. W tym przypadku chcemy dodać Nie unikalny klucz. Powstaje pytanie: w jaki sposób SQL Server sprawi, że ten klucz będzie unikalny?
SQL Server robi dla niego następujące rzeczy:
- dodaje klastrowy klucz indeksu na stronach liści i nie-liści indeksu nie-unikalnego
- jeśli klastrowy klucz indeksu jest również nie-unikalny, dodaje 4-bajtowy uniquifier, dzięki czemu klucz indeksu jest unikalny
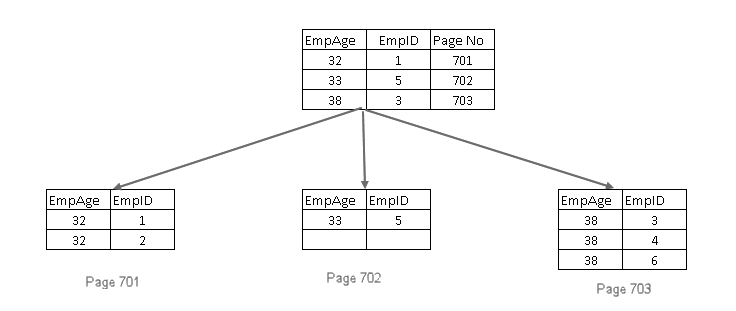
Dołącz kolumny nieklastrowe w indeksie nieklastrowym w SQL Server
spójrzmy ponownie na następujący rzeczywisty plan wykonania następującego zapytania:
|
1
2
|
Select * from Employee
where EmpContactNumber=’8474563217′
|
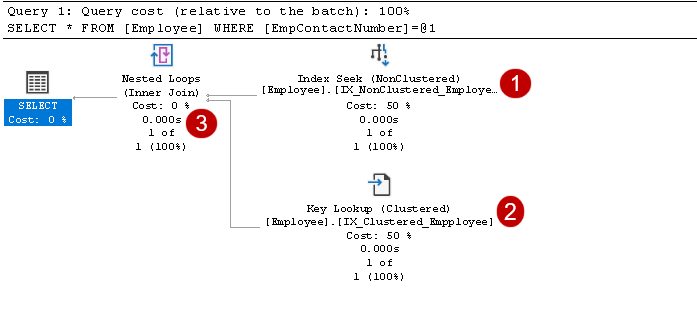
zawiera operatory wyszukiwania indeksów i wyszukiwania kluczy, jak pokazano na powyższym obrazku:
- indeks szuka: SQL Query Optimizer używa wyszukiwania indeksu na indeksie nieklastrowym i pobiera kolumny EmpID, EmpContactNumber
-
w tym kroku, Query Optimizer używa wyszukiwania klucza na indeksie klastrowym i pobiera wartości dla kolumn EmpName i EmpAge
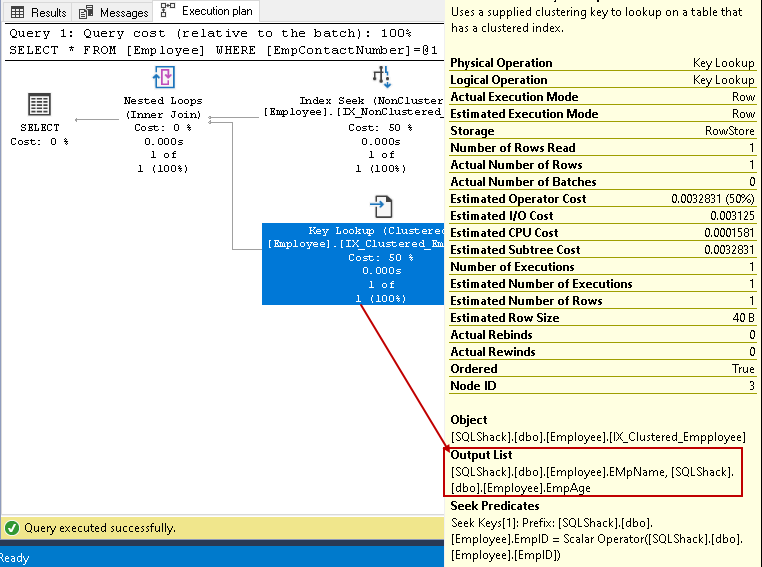
-
w tym kroku Query Optimizer używa zagnieżdżonych pętli dla każdego wiersza wyjściowego z indeksu nieklastrowego w celu dopasowania do wiersza indeksu nieklastrowego
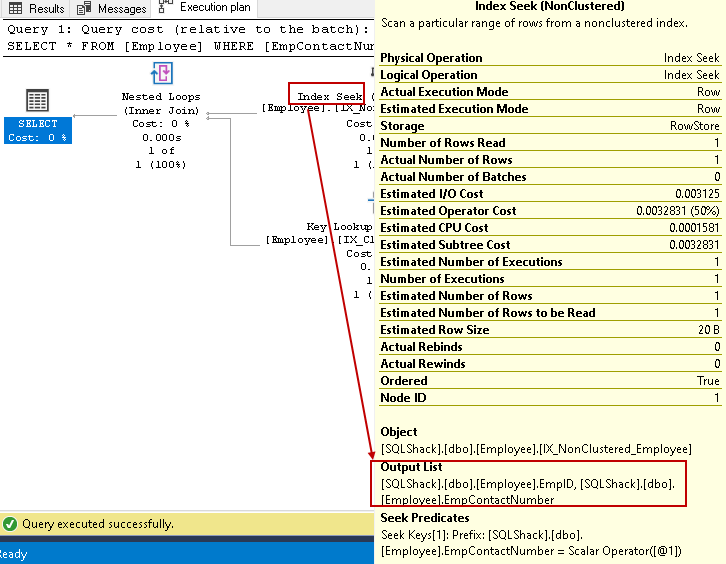
zagnieżdżona pętla może być kosztownym operatorem dla dużych tabel. Możemy obniżyć koszty za pomocą nieklastrowych kolumn indeksu non-key. Określamy kolumnę non-key w indeksie non-clustered używając klauzuli index.
upuśćmy i stwórzmy niezklasyfikowany indeks W Sql serverze za pomocą dołączonych kolumn:
|
1
2
3
4
5
6
7
|
wskaż indeks .
PRZEJDŹ
UTWÓRZ UNIKALNY INDEKS NIEKLUSTROWANY .
(
ASC
)
INCLUDE (EmpName, EmpAge)
|
dołączone kolumny są częścią węzła liści w drzewie indeksowym. Pomaga pobrać dane z samego indeksu, zamiast dalej przemierzać je w celu odzyskania danych.
na poniższym obrazku otrzymujemy zarówno dołączone kolumny EmpName, jak i EmpAge jako część węzła leaf:
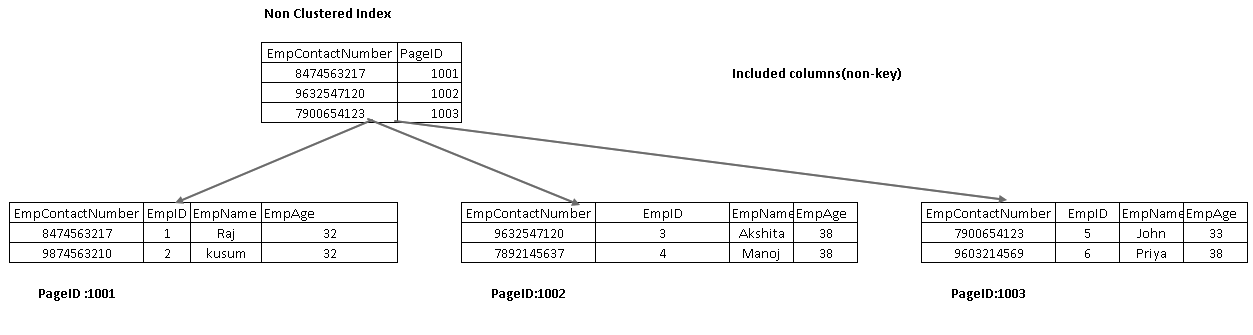
ponownie wykonaj instrukcję SELECT i zobacz rzeczywisty plan wykonania. Nie mamy klucza wyszukiwania i zagnieżdżonej pętli w tym planie wykonania:

najedź kursorem na indeks Szukaj i zobacz listę kolumn wyjściowych. SQL Server może znaleźć wszystkie kolumny za pomocą tego nieklastrowego wyszukiwania indeksu:
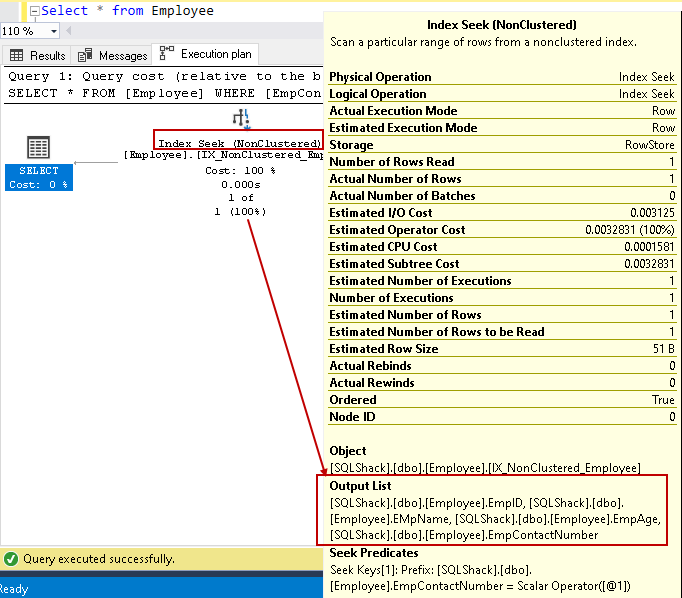
możemy poprawić wydajność zapytań za pomocą indeksu pokrywającego za pomocą dołączonych kolumn innych niż kluczowe. Nie oznacza to jednak, że w definicji indeksu powinniśmy wszystkie kolumny Nie-kluczowe. Powinniśmy być ostrożni w projektowaniu indeksów i przetestować ich zachowanie przed wdrożeniem w środowisku produkcyjnym.
podsumowanie
w tym artykule zbadaliśmy indeks nieklastrowy w SQL Server i jego użycie w połączeniu z indeksem klastrowym. Powinniśmy starannie zaprojektować indeks zgodnie z obciążeniem pracą i zachowaniem zapytań.
- Autor
- Ostatnie posty

jest twórcą jednego z największych darmowych internetowych zbiorów artykułów na jeden temat.jego 50-częściowa seria na SQL Server Always On Availability Groups. W oparciu o swój wkład w społeczność SQL Server został wyróżniony różnymi nagrodami, w tym prestiżowym „najlepszym autorem roku” nieprzerwanie w 2020 i 2021 roku w sqlshack.
Raj zawsze interesuje się nowymi wyzwaniami, więc jeśli potrzebujesz pomocy Konsultacyjnej na dowolny temat poruszany w jego pismach, możesz się z nim skontaktować w [email protected]
Zobacz wszystkie posty, których autorem jest Rajendra Gupta
- użyj szablonów ARM, aby wdrożyć instancje Azure container za pomocą obrazów Linux SQL Server-21 grudnia 2021 r.
- dostęp do pulpitu zdalnego dla AWS RDS SQL Server z niestandardowym Amazon RDS-14 grudnia 2021 r
- przechowuj pliki SQL Server w trwałej pamięci masowej dla wystąpień Azure Container – grudzień 10, 2021