Denne artikkelen gir en innføring i ikke-grupperte indeksen I SQL Server ved hjelp av eksempler.
Introduksjon
I En Tidligere artikkel Oversikt OVER SQL Server Grupperte indekser, utforsket vi kravet om en indeks og grupperte indekser I SQL Server.
før vi fortsetter, la oss få et raskt sammendrag AV SQL Server-gruppert indeks:
- den sorterer fysisk data i henhold til gruppert indeksnøkkel
- VI kan bare ha en gruppert indeks per tabell
- en tabell uten gruppert indeks er en heap, og det kan føre til ytelsesproblemer
- SQL Server oppretter automatisk en gruppert indeks for primærnøkkelkolonnen
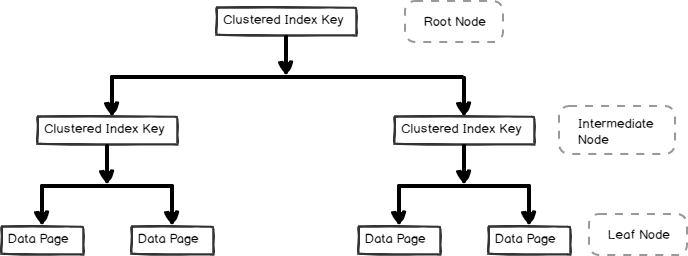
- en gruppert indeks indeksen er lagret i b-tre-format og inneholder datasidene i bladnoden, som vist nedenfor
ikke-Grupperte indekser er også nyttig for spørring ytelse og optimalisering avhengig av spørring arbeidsbelastning. I denne artikkelen, la oss utforske den ikke-grupperte indeksen og dens indre.
Oversikt over ikke-gruppert indeks I SQL Server
i en ikke-gruppert indeks inneholder ikke bladnoden de faktiske dataene. Den består av en peker til de faktiske dataene.
- hvis tabellen inneholder en gruppert indeks, peker bladnoden på den grupperte indeksdatasiden som består av faktiske data
- hvis tabellen er en heap (uten en gruppert indeks), peker bladnoden på heap-siden
i bildet nedenfor kan vi se på bladnivået for ikke-gruppert indeks som peker mot datasiden i gruppert indeks:
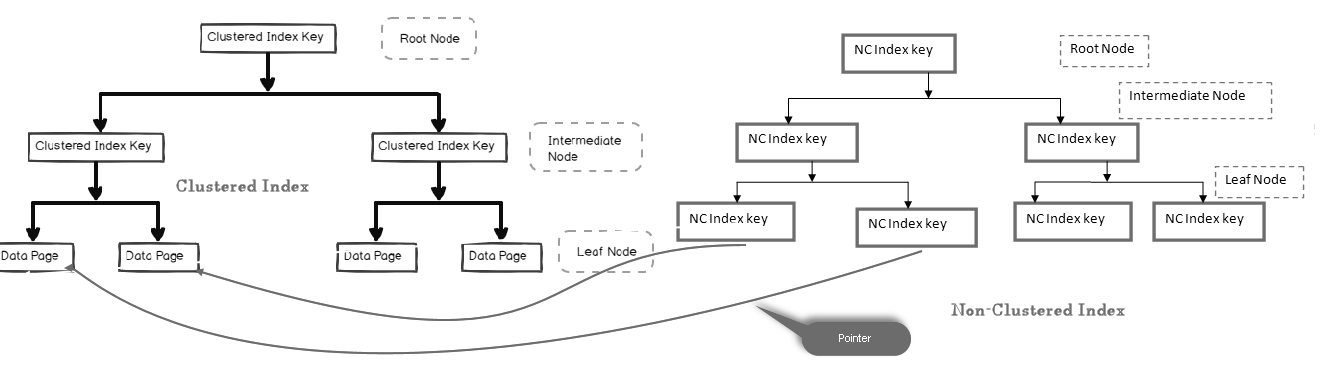
Vi Kan ha flere ikke-grupperte indekser i SQL-tabeller fordi det er en logisk indeks og sorterer ikke data fysisk i forhold til gruppert indeksen.
la oss forstå den ikke-grupperte indeksen I SQL Server ved hjelp av et eksempel.
-
Opprett En Ansatttabell uten noen indeks på den
123456OPPRETT TABELL dbo.Ansatt(EmpID INT,EMpName VARCHAR(50),EmpAge INT,EmpContactNumber VARCHAR(10)); -
Sett inn noen poster i den
123Sett Inn I Ansattes verdier (1, ‘Raj’,32,8474563217)Sett Inn I Ansattes verdier (2, ‘kusum’,30,9874563210)Sett Inn I Ansattes verdier (3, ‘Akshita’,28,9632547120) -
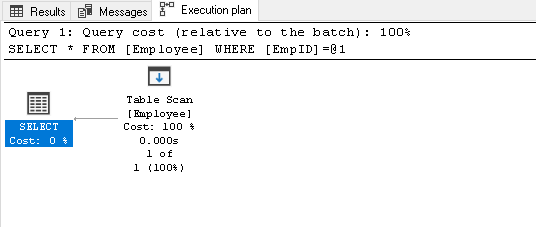
Søk Etter EmpID 2 og se etter den faktiske utførelsesplanen for den
1Velg * Fra Ansatt hvor EmpID=2det gjør en tabellskanning fordi vi ikke har noen indeks på denne tabellen:
-
Opprette en unik gruppert indeks På empid-kolonnen
1LAG UNIKE GRUPPERT INDEKS IX_Clustered_Empployee på dbo.Ansatt (EmpID); -
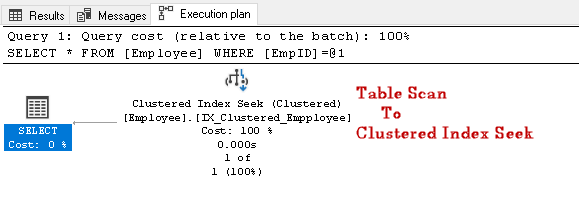
Søk Etter EmpID 2 og se etter den faktiske utførelsesplanen for den
i denne utførelsesplanen kan vi legge merke til at tabellskanningen endres til en gruppert indekssøk:
la oss utføre en ANNEN SQL-spørring for å søke Ansatt med et bestemt kontaktnummer:
|
1
|
Velg * Fra Ansatt hvor EmpContactNumber=’9874563210′
|
Vi har ikke en indeks På empcontactnumber kolonnen, Derfor Bruker Query Optimizer gruppert indeksen, men den skanner hele indeksen for å hente posten:
Høyreklikk på utførelsesplanen og velg Vis Utførelsesplan XML:
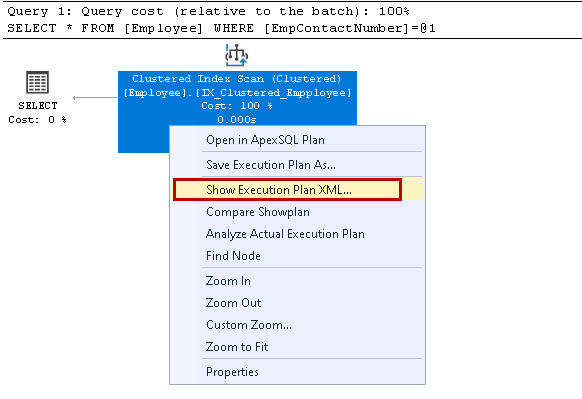
DEN åpner XML utførelsesplan i vinduet ny spørring. Her ser vi at den bruker den grupperte indeksnøkkelen og leser de enkelte radene for å hente resultatet:

la oss sette inn noen flere poster i Ansatttabellen ved hjelp av følgende skript:
|
1
2
3
|
Sett Inn I Ansattes verdier (4, ‘Manoj’,38,7892145637)
Sett Inn I Ansattes verdier (5, ‘John’,33,7900654123)
Sett Inn I Ansattes verdier (6, ‘Priya’,18,9603214569)
|
vi har seks ansatte i denne tabellen. Utfør nå select-setningen igjen for å hente ansattes poster med et bestemt kontaktnummer:
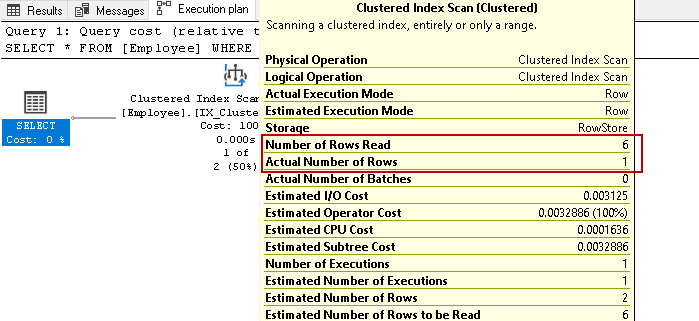
den skanner igjen alle seks radene for resultatet basert på den angitte tilstanden. Tenk deg at vi har millioner av poster i tabellen. HVIS SQL Server må lese alle indeksnøkkelrader, vil DET være en ressurs og tidkrevende oppgave.
Vi kan representere gruppert indeks (ikke faktisk representasjon) I b-tre-formatet i henhold til følgende bilde:

I forrige spørring LESER SQL Server rotnodesiden og henter hver bladnodeside og-rad for datahenting.
la Oss nå opprette en unik ikke-gruppert indeks I SQL Server På Ansatttabellen I EmpContactNumber-kolonnen som indeksnøkkel:
|
1
|
OPPRETT UNIK NONCLUSTERED INDEX IX_NonClustered_Employee PÅ dbo.Ansatt (EmpContactNumber);
|
før vi forklarer denne indeksen, kjør SELECT-setningen PÅ NYTT og se den faktiske utførelsesplanen:
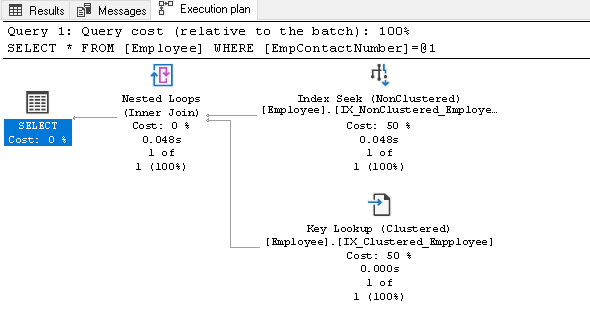
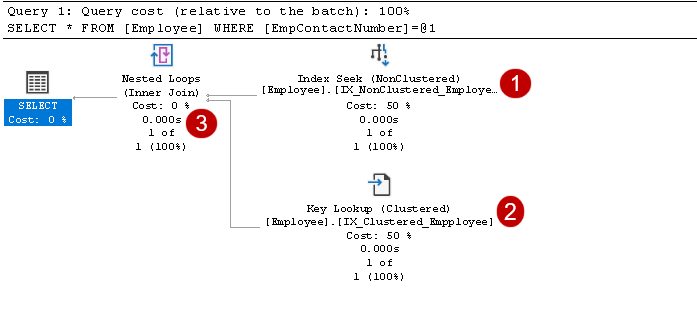
i denne utførelsesplanen kan vi se to komponenter:
- Indekssøk (Ikke-Klumpet)
- Nøkkeloppslag (Gruppert)
for å forstå disse komponentene må vi se på en ikke-gruppert indeks I SQL Server-design. Her kan du se at bladnoden inneholder ikke-gruppert indeksnøkkel (EmpContactNumber) og gruppert indeksnøkkel (EmpID):
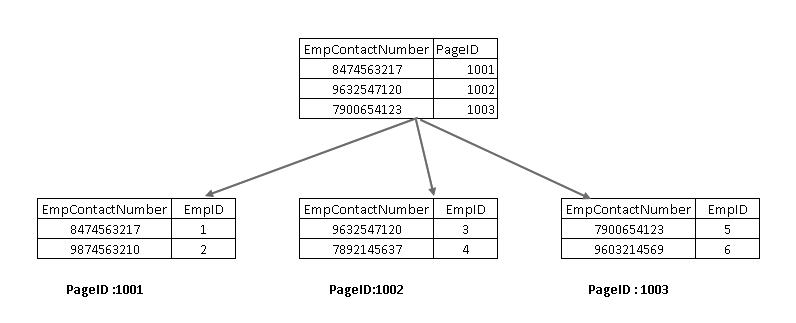
nå, hvis du kjører SELECT-setningen PÅ NYTT, går den gjennom med den ikke-grupperte indeksnøkkelen og peker til en side med gruppert indeksnøkkel:
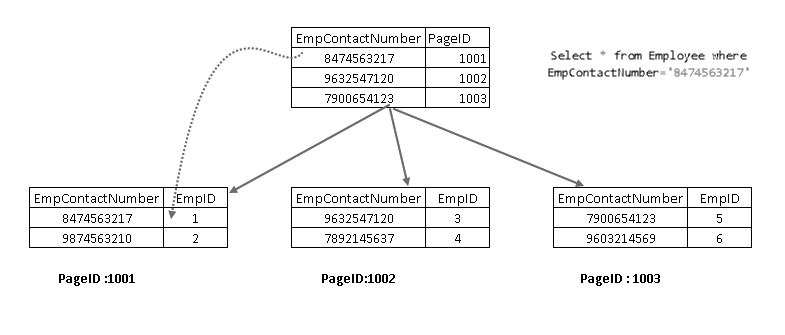
viser at den henter posten med en kombinasjon av gruppert indeksnøkkel og ikke-gruppert indeksnøkkel. Du kan se fullstendig logikk FOR SELECT-setningen som vist nedenfor:
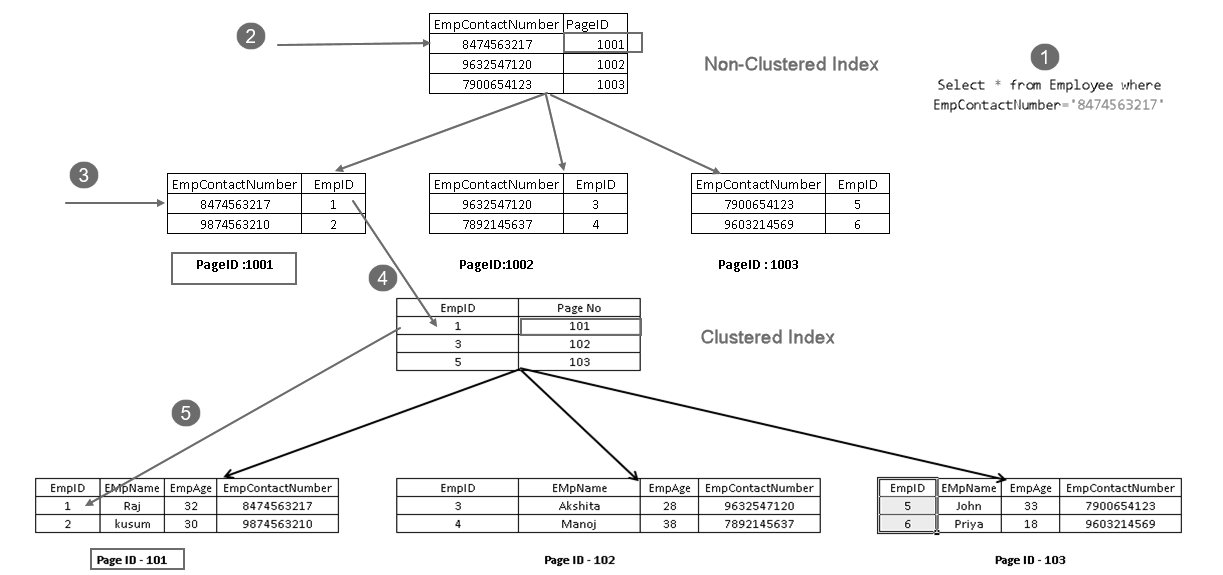
- En bruker utfører en select-setning for å finne ansattposter som samsvarer med et angitt kontaktnummer
- Spørringsoptimereren bruker en indeksnøkkel som ikke er gruppert, og finner ut sidetallet 1001
- Denne siden består av en indeksnøkkel i klyngen. Du kan se EmpID 1 i bildet ovenfor
- SQL Server finner ut side nr 101 som består Av EmpID 1-poster ved hjelp Av gruppert indeksnøkkel
- den leser den matchende raden og returnerer utdataene til brukeren
tidligere så vi at den leser seks rader for å hente den matchende raden og returnerer en rad i utgangen. La oss se på en utførelsesplan ved hjelp av den ikke-klyngede indeksen:

Ikke-unik ikke-gruppert indeks I SQL Server
Vi Kan ha flere ikke-grupperte indekser i EN SQL-tabell. Tidligere har vi opprettet en unik ikke-gruppert indeks I kolonnen EmpContactNumber.
før du oppretter indeksen, utfør følgende spørring slik at vi har duplikatverdi i Kolonnen EmpAge:
|
1
2
3
|
Oppdater Ansatt sett EmpAge=32 hvor EmpID=2
Oppdater Ansatt sett EmpAge=38 Hvor EmpID=6
Oppdater Ansatt sett EmpAge=38 hvor EmpID=3
|
la oss utføre følgende spørring for en ikke-unik ikke-gruppert indeks. I spørringssyntaksen angir vi ikke et unikt søkeord, og DET forteller SQL Server å opprette en ikke-unik indeks:
|
1
|
OPPRETT NONCLUSTERED INDEX NCIX_Employee_EmpAge PÅ dbo.Ansatt (EmpAge);
|
som vi vet, bør nøkkelen til en indeks være unik. I dette tilfellet vil vi legge til en ikke-unik nøkkel. Spørsmålet oppstår: Hvordan VIL SQL Server gjøre denne nøkkelen så unik?
SQL Server gjør følgende ting for det:
- den legger til den grupperte indeksnøkkelen i blad-og ikke-blad-sidene i den ikke-unike ikke-grupperte indeksen
- hvis den grupperte indeksnøkkelen også er ikke-unik, legger den til en 4-byte-unikifier slik at indeksnøkkelen er unik
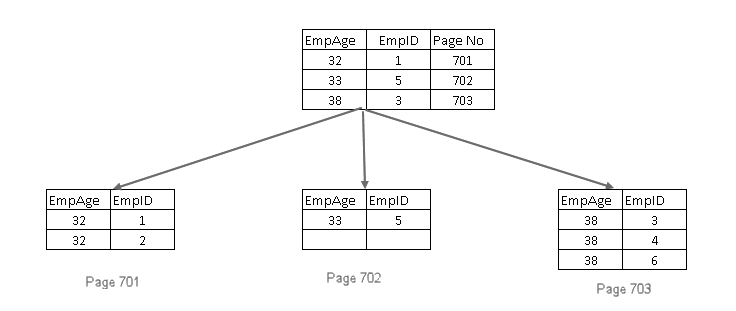
Inkluder ikke-nøkkel kolonner i ikke-gruppert indeks I SQL Server
La oss se på følgende faktiske utførelsesplan på nytt av følgende spørring:
|
1
2
|
Velg * Fra Ansatt
hvor EmpContactNumber=’8474563217′
|
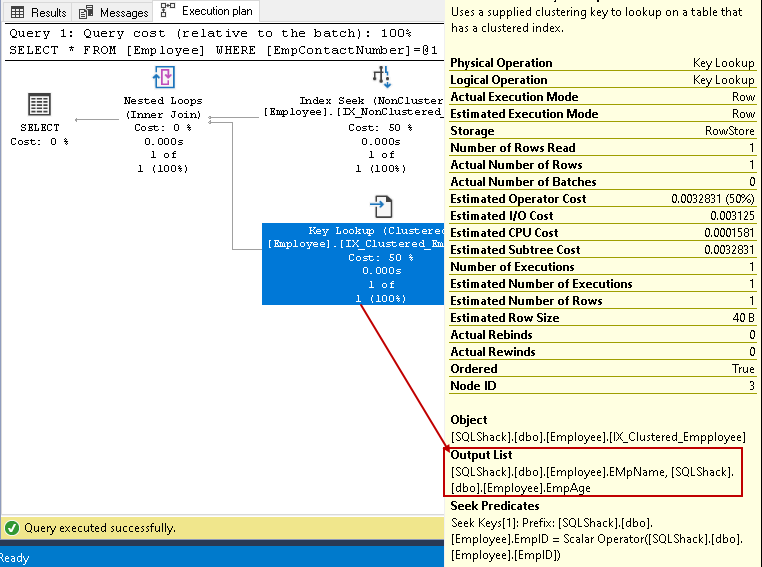
det inkluderer indekssøk og nøkkeloppslagoperatorer, som vist i bildet ovenfor:
- indeksen søker: SQL Query Optimizer bruker en indekssøk på ikke-gruppert indeks og henter empid, EmpContactNumber kolonner
-
I dette trinnet Bruker Query Optimizer nøkkeloppslag på gruppert indeks og henter verdier For EmpName og EmpAge kolonner
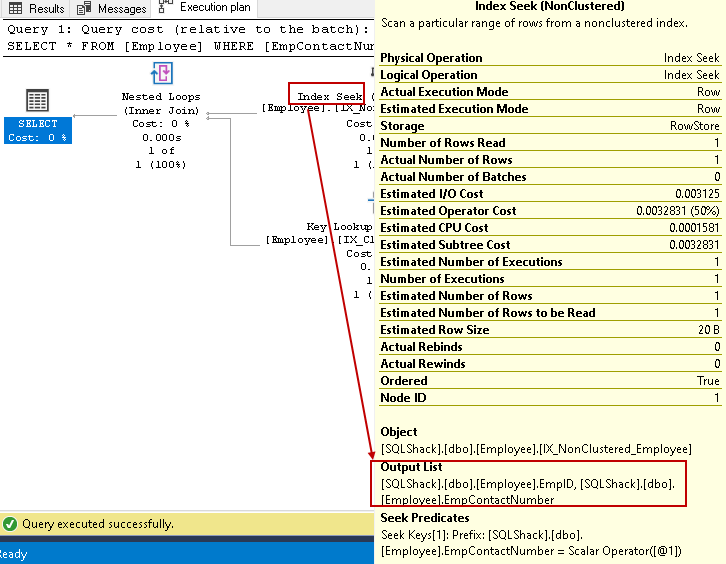
-
I dette trinnet Bruker Query Optimizer de nestede løkkene for hver radutgang fra den ikke-grupperte indeksen for samsvar med den grupperte indeksraden
den nestede sloyfen kan v re en kostbar operator for store bord. Vi kan redusere kostnadene ved hjelp av ikke-klynget indeks ikke-nøkkel kolonner. Vi angir ikke-nøkkelkolonnen i den ikke-grupperte indeksen ved hjelp av indeksklausulen.
La oss slippe og opprettet den ikke-grupperte indeksen I SQL Server ved hjelp av de medfølgende kolonnene:
|
1
2
3
4
5
6
7
|
SLIPP INDEKSEN PÅ .
GÅ
OPPRETT UNIK IKKE-KLUMPET INDEKS PÅ .
(
ASC
)
INKLUDER (EmpName, EmpAge)
|
Inkluderte kolonner er en del av bladnoden i et indekstre. Det hjelper å hente data fra indeksen selv i stedet for å krysse videre for datahenting.
i det følgende bildet får vi begge inkluderte kolonner EmpName og EmpAge som en del av bladnoden:
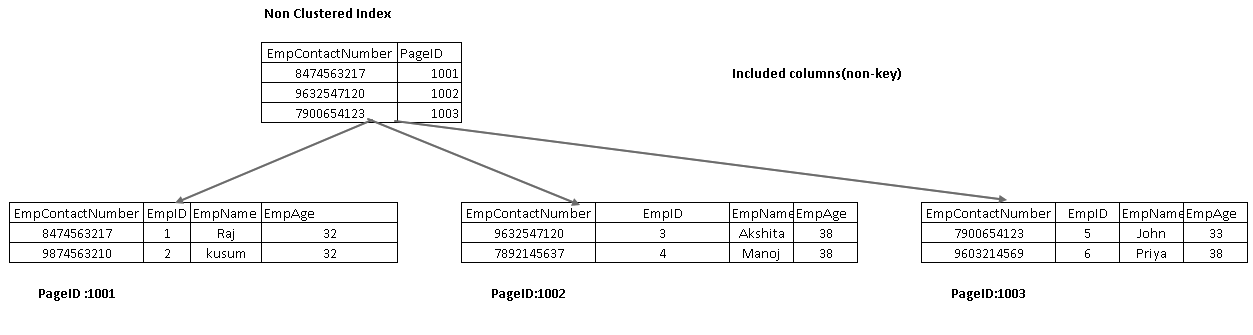
utfør SELECT-setningen PÅ NYTT og se den faktiske utførelsesplanen nå. Vi har ikke nøkkeloppslag og nestet sløyfe i denne utførelsesplanen:

la oss holde markøren over indekssøk og se listen over utdatakolonner. SQL Server kan finne alle kolonnene ved hjelp av denne ikke-grupperte indekssøk:
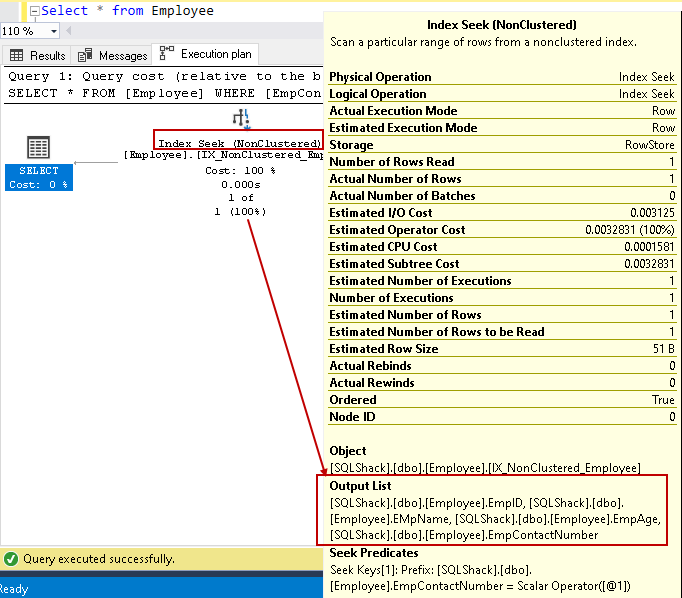
Vi kan forbedre spørringsytelsen ved hjelp av dekkindeksen ved hjelp av inkluderte ikke-nøkkelkolonner. Det betyr imidlertid ikke at vi skal alle ikke-nøkkelkolonner i indeksdefinisjonen. Vi bør være forsiktige i indeksdesign og bør teste indeksadferden før distribusjon i produksjonsmiljøet.
Konklusjon
i denne artikkelen utforsket vi ikke-grupperte indeksen I SQL Server og bruken i kombinasjon med grupperte indeksen. Vi bør nøye utforme indeksen i henhold til arbeidsbelastning og spørringsadferd.
- Forfatter
- Siste Innlegg

han er skaperen av en av de største gratis online samlingene av artikler om et enkelt emne, med sin 50-delers serie På SQL Server Alltid På Tilgjengelighetsgrupper. Basert på hans bidrag TIL SQL Server-fellesskapet, har han blitt anerkjent med ulike priser, inkludert den prestisjetunge «Best author of the year» kontinuerlig i 2020 og 2021 På SQLShack.
Raj er alltid interessert i nye utfordringer, så hvis du trenger konsulenthjelp på et emne som er dekket i hans skrifter, kan Han nås på rajendra.gupta16 @ gmail.com
Vis alle innlegg Av Rajendra Gupta
- Bruk ARM-maler til å distribuere Azure container instances med SQL Server Linux – bilder-21. desember 2021
- Ekstern skrivebordstilgang for AWS RDS SQL Server Med Amazon Rds Custom-14. desember 2021
- LAGRE SQL Server – filer I Vedvarende Lagring For Azure Container Instances-desember 10, 2021